
GraphQL Federation Was Built Backwards

In a recent post , I wrote about the coordination bottleneck in GraphQL Federation and how schema changes that should take days can end up taking months, due to the overhead of finding the right people, aligning on design, and tracking work across subgraphs.
This post goes deeper into why that bottleneck exists. The short version: GraphQL Federation was designed bottom-up from subgraphs, but scalable API design needs a top-down, consumer-first model. It's a design flaw in how Federation was conceived.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
Before we talk about Federation, let's revisit why GraphQL exists.
GraphQL was created to empower the API consumer. Instead of the server dictating what data you get, like REST endpoints do, the client describes what it needs:
No over-fetching. No under-fetching. The client is in control.
GraphQL starts from a simple idea: the API should be designed around what consumers need, not around how the backend happens to be structured.
This is especially important for teams building large, consumer-facing GraphQL APIs across multiple services and teams.
Federation takes the GraphQL schema and splits it across teams. Each team owns a subgraph (a piece of the overall schema), and a composition process merges them into a supergraph.
Here's a simplified example. Team A owns users:
Team B owns orders:
Compose them, and you get a supergraph where a client can query users with their orders. This is the textbook example, and it works well.
Now let's see what happens when something needs to change.
A frontend team is building a new feature and needs to show whether a user is eligible for express shipping. The ideal query looks like this:
Simple enough. But where does shippingEligibility come from?
It doesn't exist in any subgraph. The User type is owned by Team A. Shipping logic lives in a fulfillment service maintained by Team C. The restrictions field depends on data from Team D's compliance service.
To add this field, the frontend team needs to:
- Figure out that
Useris owned by Team A - Realize Team A can't provide shipping data
- Find Team C, who owns fulfillment
- Discover that
restrictionsrequires Team D - Coordinate a design that works across all three subgraphs
- Get the platform team to review the schema design
- Wait for all three teams to implement their parts
- Compose and verify the result
The frontend team started with a clear picture of what they needed. Federation forced them into a scavenger hunt across the organization to figure out who can build it and how.
The consumer knew what the API should look like. Federation made that irrelevant.This is the fundamental problem.
Federation's composition model works from the bottom up: subgraph teams build their schemas independently, and the supergraph is whatever comes out of the composition process.
In other words, bottom-up means starting from individual subgraphs and composing a supergraph as a byproduct, while top-down means designing the supergraph first and then decomposing it into subgraph responsibilities.
The supergraph is a side effect. It's not designed. It's assembled.
GraphQL was designed to be consumer-first. If you take that seriously, the workflow should be the opposite:
Start with what the consumer needs. Design the supergraph to serve that. Then figure out how to distribute the work.
Composition assembles from the bottom up. Decomposition designs from the top down.This is the insight behind what we call Fission.
Fission is a stateful schema graph engine that maintains two synchronized views of your federated graph: the supergraph (the consumer-facing API) and the subgraphs (what each team implements). The supergraph is the source of truth. When you make changes to it, Fission handles the consequences — propagating dependencies, managing entity keys, and keeping everything in sync.
Let's walk through the shipping example with Fission.
The frontend team describes what they need — their "dream query" :
This isn't a wish list. It's the starting point for API design.
On the Hub canvas, the team proposes the new fields directly on the supergraph:
At this point, nobody has decided which subgraph owns these fields. The design is purely about what the consumer needs. This is powerful because teams are not jumping to implementation too early. They avoid anchoring on a particular solution. All options stay open while the conversation focuses entirely on the API contract.
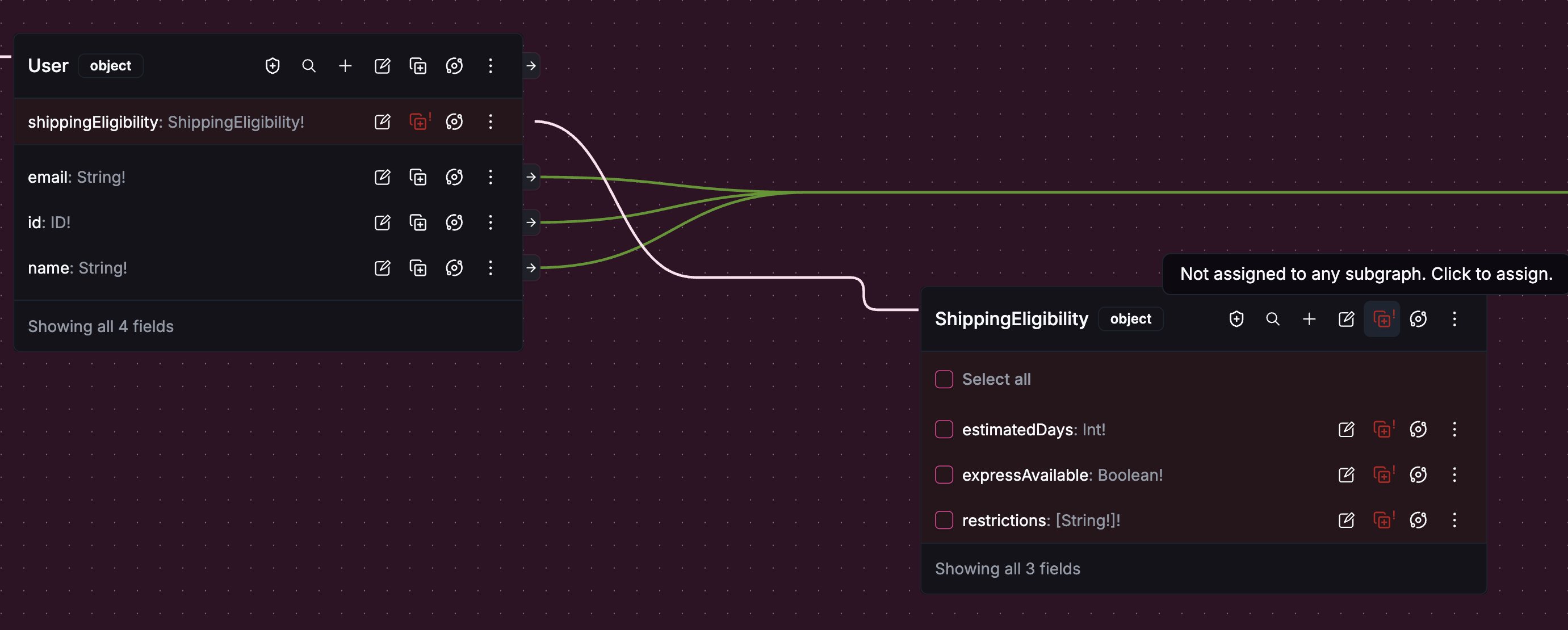
Now the architect assigns the new fields to subgraphs on the Hub canvas. Fission handles everything that follows:
shippingEligibilityonUseris assigned to a fulfillment subgraph → Fission automatically propagatesUser @key(fields: "id")to that subgraph so the entity is resolvableexpressAvailableandestimatedDays→ Team C's fulfillment service will provide theserestrictions→ requires data from Team D's compliance service. Fission pulls in any transitive type dependencies automatically
The result is a concrete proposal: Team C needs to add ShippingEligibility to their subgraph, Team D needs to expose restrictions data, and composition will produce the supergraph the consumer asked for.
Hub routes the proposal to the right stakeholders automatically. Team A reviews because User is being extended. Team C reviews because they're implementing the new type. Team D reviews because their data is required.
Each team approves their part. Once approved, the work is assigned and tracked.
No scavenger hunt. No Slack threads. No platform team acting as a human switchboard.
The difference between composition and decomposition isn't just about workflow. It changes what gets built.
When you compose bottom-up, the supergraph reflects the backend's internal structure. Field names match service internals. Type boundaries align with team boundaries, not consumer use cases. The API is a mirror of the architecture, not a product designed for its users.
When you decompose top-down, the supergraph is designed for the consumer. Field names make sense from the client's perspective. Types are grouped by use case, not by which team happens to own the data. The API is a product.
This is the difference between an API that happens to work and an API that's designed to be used.
An important clarification: Fission and Federation are not competing concepts. They're complementary.
Federation handles runtime concerns: query planning, execution across subgraphs, entity resolution. It's the engine that makes a distributed graph work as a unified API.
Fission handles design-time concerns: how teams decide what the supergraph should look like, who is responsible for what, and how changes are proposed, reviewed, and tracked.
Federation is how you run a federated graph. Fission is how you evolve one.
Without Fission, Federation works fine at small scale — a handful of subgraphs, a few teams, informal coordination. But as the graph grows, the coordination overhead becomes the dominant cost.
That's where Fission and WunderGraph Hub come in.
If this sounds familiar, it should.
The shift from monoliths to microservices had the same tension. Monoliths are easy to design because everything is in one place. Microservices are powerful but introduce coordination overhead.
Federation is the microservices of API design. It gives you distributed ownership but makes coordinated change expensive.
Fission gives you the best of both: design like a monolith, implement as microservices.
You work with the supergraph as if it were a single schema. One coherent API designed for consumers. Then, Fission decomposes it into distributed responsibilities that map to your actual team structure.
We've been working with customers who manage large GraphQL federated graphs, and the pattern is consistent. These are usually platform engineering and architecture teams coordinating many subgraphs and consumer applications.
- Frontend team identifies a need
- Weeks of meetings to find the right backend teams
- Miro boards and design docs to propose schema changes
- Platform team reviews for consistency
- Each subgraph team implements independently
- Composition breaks because of misaligned assumptions
- More meetings to resolve conflicts
- Eventually, the feature ships
- Frontend team proposes the change on the Hub canvas
- Affected teams are identified automatically
- Stakeholders discuss and iterate on the proposal: comments, suggestions, and refinements happen in context
- Once aligned, each team approves its part
- Work is assigned and tracked in the proposal
- Implementation proceeds with clear specifications
- Composition succeeds because the design was validated upfront
The difference isn't incremental. It's structural.
Senior architects who've worked with Federation for years tell us this is a paradigm shift. Not because the technology is magic, but because it finally aligns the workflow with how API design should have worked from the start.
Fission was designed for human collaboration, but the model is inherently agent-friendly.
An AI agent building an application can describe its ideal query, explore the supergraph to see what exists, and propose changes for what's missing. A human reviews and approves. The agent implements.
This isn't science fiction. It's the natural extension of a top-down, consumer-first design model. When the consumer is an agent, having a structured, searchable graph with clear ownership is even more critical than when the consumer is a human.
But that's a topic for another post.
Federation's original design started from subgraphs and assembled the consumer-facing API as a byproduct. Fission reverses that: the supergraph is the source of truth, and subgraph responsibilities follow from it.
Start with what the consumer needs. Then figure out how to build it.It's not a replacement for Federation. It's the missing piece that makes Federation work the way it was always supposed to.
If you want to see Fission in action, watch the webinar or get in touch for a walkthrough.
Frequently Asked Questions (FAQ)
Fission is a stateful schema graph engine that inverts the traditional Federation workflow. Instead of composing subgraphs into a supergraph (bottom-up), you design the consumer-facing API on the supergraph first, and Fission handles the decomposition into subgraph responsibilities — including dependency propagation, entity key management, and federation directive handling.
A dream query is the ideal GraphQL query a consumer would write if there were no technical constraints. It represents what the API should look like from the consumer perspective. Fission uses dream queries as the starting point for API design, then works backwards to determine how to distribute the implementation across subgraphs.
Traditional Federation starts with subgraphs and composes them into a supergraph. The consumer-facing API is a side effect of what backend teams happened to build. Fission flips this: you design the consumer-facing API first, then decompose it into subgraph responsibilities. This puts the API consumer first, which is the original promise of GraphQL.
No. Fission complements Federation. Federation handles the runtime composition and query execution across subgraphs. Fission handles the design-time workflow — how teams decide what the supergraph should look like and who is responsible for implementing each part.
Yes. Fission works with both new and existing federated graphs. For existing graphs, it provides a way to visualize the current state, propose changes at the supergraph level, and automatically identify which subgraphs and teams are affected.
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


