
The Missing Layer in GraphQL Federation

GraphQL Federation is a powerful idea. Take a unified API, split ownership across teams, and let each team ship independently.
In theory, this gives you the best of both worlds: a single, coherent API for consumers and autonomous teams on the backend.
In practice, it creates a problem nobody talks about.
The promise of Federation is clear: frontend engineers get a single schema to query, backend teams own their slice of the graph, and everyone ships faster.
The reality is different.
Let's say you're a frontend engineer building a new feature. You open the supergraph schema to check if it has everything you need. For small schemas, this works fine. But once you're looking at thousands of lines of SDL spread across dozens of types, it becomes overwhelming. For product owners or designers trying to understand what capabilities exist, it's a wall of code.
But the real pain starts when the schema doesn't have what you need.
You need a few new fields. Maybe a new root query. Maybe a field on an existing type that's owned by another team.
Sounds simple. It's not.
The supergraph is built from many subgraphs — in some cases, more than a hundred — and each subgraph is typically owned by a different team. You can't just add an isAvailable field on the User type because the team owning that type might not be able to provide that information. Or they might have a different name for the concept. Or they're in the middle of a migration.
Before you can even have that conversation, you need to figure out who to talk to. Which team owns the User entity? Who maintains the Product subgraph?
So you ask the platform engineering team. They usually know. But now you've moved the problem to them, and they're already overwhelmed.
Platform engineers are the people who maintain the schema standards, run design reviews, and help teams compose correctly. They are the bottleneck for the entire organization, and every new schema change request makes it worse.
Here's how most organizations handle this today:
Meetings. Lots of meetings. Teams schedule calls to discuss schema changes, often with people who turn out not to be the right stakeholders.
Miro boards. Someone spends hours creating a visual representation of the relevant types and their relationships. By the time the board is ready, the schema has already changed. There's no way to sync it. It's a snapshot that's outdated the moment it's created.
Slack threads. Schema change proposals buried in threads that the right people never see, or see too late.
The platform team as a switchboard. Every request flows through them. Who owns this type? Can this field be added here? Is this name consistent with our conventions? They become the human router for every schema change, leaving little time for the work that actually matters — reliability, performance, and architecture.
The result: complex schema changes can take months. Not because the implementation is hard, but because the coordination is.
Here's the part nobody talks about.
The big idea behind GraphQL is that it empowers the API consumer. Query exactly the data you need, no more, no less. The schema is a contract designed around what clients need.
Federation breaks this principle.
In the current model, you build subgraphs from the bottom up, then compose them into a supergraph. The supergraph is a side effect of composition. It's whatever the subgraph teams happened to build.
But that's backwards.
If GraphQL is about empowering the consumer, then the consumer-facing API should be the starting point. You should design the API you want consumers to have, then decompose that design into work for the subgraph teams.
Composition builds the supergraph from the bottom up. Decomposition designs it from the top down.This isn't just a philosophical difference. It changes how teams collaborate on every schema change.
Instead of a frontend engineer trying to reverse-engineer which subgraph teams to talk to, they propose the change they need at the supergraph level. The affected teams are identified automatically. Each team reviews and approves their part. And once approved, the work is assigned and tracked.
We call this approach Fission , the inverse of Federation. We'll publish a deep technical dive on Fission separately, but the key insight is this: if you want Federation to actually work at scale, you need to flip the direction.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
This is why we built Hub.
Hub is a collaborative platform for supergraph development. It gives teams a visual canvas — think Miro, but purpose-built for your schema — where you can see all types, fields, their relationships, and who owns each entity.
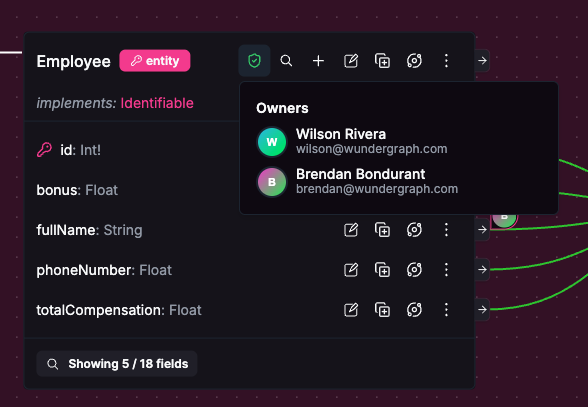
Instead of navigating a wall of SDL, you explore the graph visually. Product owners can understand what capabilities exist. Frontend engineers can see where the data they need lives, as well as who to talk to if it doesn't exist yet.
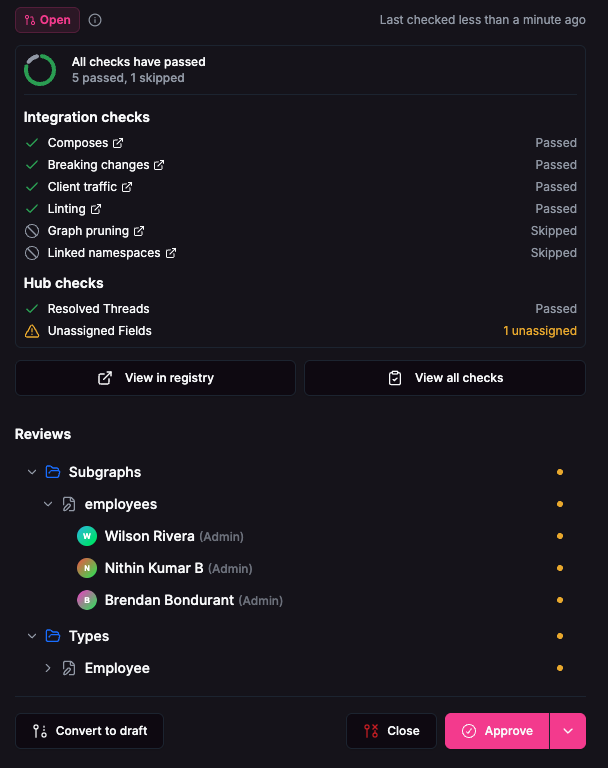
When you need a change, you propose it directly on the canvas. Hub automatically identifies which entities and subgraphs are affected, and invites the right stakeholders to review. At least one representative from each affected subgraph has to approve. Once approved, the work is assigned and progress is tracked across all teams.
In a nutshell: discovery for what capabilities exist, collaboration for how they evolve, and governance to keep quality high as the graph scales.
Here's what we keep hearing from platform engineering teams: the bottleneck isn't writing code. It's getting alignment on what to write.
Once a team knows what to build, the implementation is the easy part. With LLMs, it's getting even faster. An engineer can describe the change and have working code in minutes.
Getting to that point is the hard part. Finding the right people, aligning on the schema, keeping it consistent with the rest of the graph, and coordinating implementation across subgraphs is where weeks turn into months.
This is why the rise of AI makes this problem more urgent, not less. LLMs accelerate implementation, but they can't coordinate humans. If coordination is your bottleneck, AI won't give you the velocity you're expecting.
Hub solves the collaboration and governance problem, so platform engineering teams can focus on what they're best at: reliability, performance, and architecture. Not being a human switchboard for schema change requests.
While we keep talking about APIs, Hub is really a platform to explore, exchange, and manage business capabilities packaged as APIs.
Today, those capabilities are explored and evolved by humans. But we're already seeing the next shift.
What once started as a collaborative canvas for engineers will evolve into a development platform for AI agents. An agent can ask Hub through MCP if a query exists for the data it needs. If not, it can propose the schema change. A human reviews and approves. The agent implements.
You don't need SDKs or specifications for this workflow. You need a searchable, unified graph of all available capabilities where agents can query precisely the information they need. No wasted tokens, no hallucinations.
As Cloudflare noted , it doesn't work to expose thousands of API endpoints to an agent. You need a structured, searchable graph. That's what Hub provides.
If this succeeds, every organization will have agents working alongside humans to continuously evolve their business capabilities. Hub is the brain in the middle, the central nervous system that coordinates it all.
Scaling business capabilities means scaling the API surface. And scaling the API surface means adding more teams. But adding teams without collaboration and governance tooling creates friction, not velocity.
Federation gave us the ability to split a schema across teams. What's been missing is the layer that makes those teams work together effectively.
That's Hub.
If you're running Federation at scale and feeling the coordination tax, we'd love to show you what we've built. Get in touch or explore the docs to learn more.
Frequently Asked Questions (FAQ)
The biggest bottleneck is coordination. Federation splits a unified schema across teams, but changing that schema requires finding the right people, aligning on design, tracking implementation across subgraphs, and ensuring quality. Without tooling, platform engineering teams become the bottleneck for the entire organization.
Composition is the current model: teams build subgraphs independently and compose them into a supergraph. Decomposition flips this — you design changes at the supergraph level and then assign work to the appropriate subgraph teams. Decomposition puts the API consumer first, which is what GraphQL was designed to do.
Hub provides a visual canvas to explore the supergraph, propose schema changes, automatically identify affected teams, and track implementation progress. It adds a governance layer so that schema quality stays high as the graph scales.
LLMs can implement code changes faster than ever, but they cannot coordinate humans across teams. As AI accelerates development velocity, the human coordination bottleneck becomes the limiting factor. Solving collaboration is the prerequisite to unlocking AI-driven development velocity.
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


