
RAG Cost Control for AI Agents: How to Prevent AI Spend Drifts

TL;DR
RAG costs drift when retrieval, reranking, tools, API calls, caching, and model routing each make local decisions with no shared control layer. In agentic AI systems, "one request" can turn into multiple model calls, tool calls, and thousands of tokens before generation. To regain predictable spend, measure per-request tokens and model calls, then tune chunking, retrieval depth, caching, and routing behind a shared router or API orchestration layer that enforces these policies before generation.
Why fragmented RAG and agentic workflows create unpredictable LLM spend, weak governance, and scaling overhead
Most teams treat rising AI costs as a model problem, but it's usually not. As AI systems grow - especially agentic RAG stacks - it becomes harder to predict spend, responses slow down, governance breaks down, and teams need to take on more operational overhead.
The issue is that retrieval, routing, caching, model calls, and agentic workflows are spread across services with no shared control. By the time a request reaches the model - cost, latency, and risk have already compounded.
This is a control problem. Without a single place to enforce limits and inspect requests, each service makes decisions locally and no one sees the full request, allowing costs to drift up over time.
The fix: Enforce retrieval limits, reranker gates, and caching policies at a shared control point before generation.
Why this matters: From a business perspective, this is where AI systems stop being predictable. Local optimization inside separate services creates hidden cost and latency multipliers that are hard to trace at the request level.
Control mechanism
Set maximum retrieval depth (top-k) and tune it against real query distributions, enforced at the router layer before chunks reach the model.
In many implementations, every retrieved chunk is appended directly to the prompt. Many systems over-retrieve, especially when top-k is not tuned against real query distributions, but extra tokens often do not improve answers proportionally. However, they always increase cost.
What is Retrieval Depth (Top-K)?
Retrieval depth, often called "top-k," is how many documents or chunks your system retrieves for each query.
If you retrieve 5 chunks (top-k = 5), the system sends the 5 most relevant chunks to the model.
If you retrieve 10 chunks (top-k = 10), it sends 10.
Retrieving more chunks increases the chance of including useful context, but also increases token count and cost on every request.
Most systems default to higher values than necessary.
When retrieval happens across services, each team optimizes locally. Often, no one sees total prompt size.
Control mechanism
Only invoke rerankers when initial retrieval confidence falls below a threshold, and cap tool loop depth to prevent cascading calls.
Cross-encoder rerankers and multi-step pipelines add latency and cost before the final answer.
Rerankers can reduce cost when they let you retrieve fewer chunks while maintaining precision, but if you add a reranker without reducing retrieval depth, you pay extra model cost and latency on top of the original token load.
If you add tool calls or retries, then one question becomes a cascade:
- generation
- retrieval
- tool execution
- regeneration
Each step looks justified. Together they multiply token spend and increase response time.
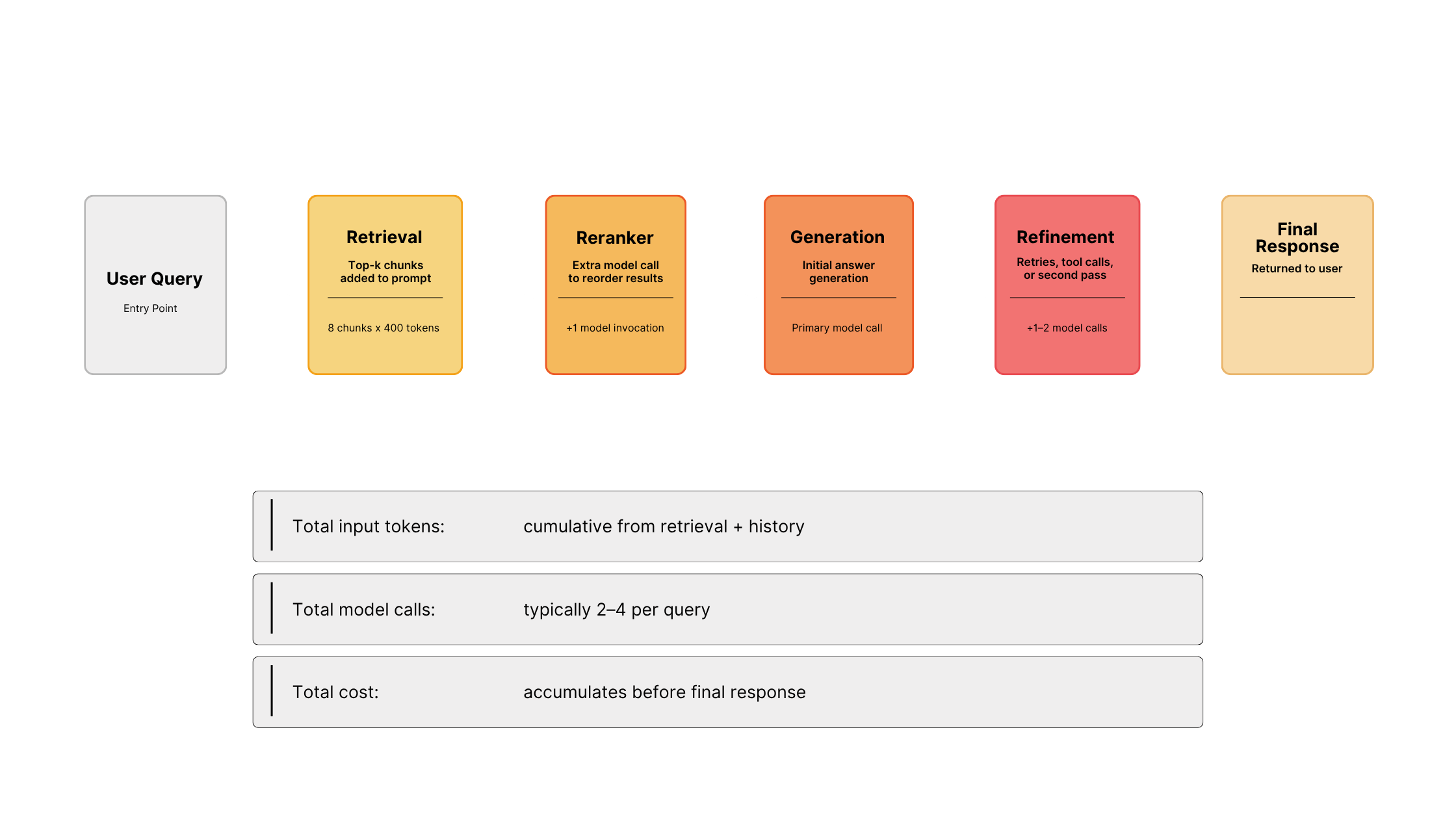
A single query is rarely just one model call. In many production RAG or agentic pipelines, a single user question can fan out into multiple model invocations across retrieval, reranking, tools, and refinement, consuming thousands of tokens in the process.
Most systems will measure “one request”, but your bill will reflect the full workflow.
Control mechanism
Implement change detection before re-embedding—hash document content and only re-embed when meaningful changes occur.
Every document update triggers re-embedding.
If your system updates frequently - wikis, knowledge bases, ticketing systems - then embedding runs constantly, even if the content barely changes. It usually runs through background indexing jobs, not request-level metrics, so most teams don’t track it separately.
It hides in the infrastructure bill.
If your expenses continue to rise, don’t optimize everything at once. Start with the biggest multiplier.
- If input tokens are much higher than output → reduce retrieval (chunks per query, chunk size, pruning)
- If one request triggers multiple model calls → simplify the pipeline or add routing
- If the same queries repeat → implement caching before changing models
- If rerankers run on every query → gate them behind a confidence threshold
Most systems won’t need a full redesign, they just need to remove one or two sources of cost amplification.
If you want predictable AI spend or enforceable governance, this is the minimum level of visibility required. Without it, cost and risk are managed after the fact.
Before you redesign, measure. You can start by checking these:
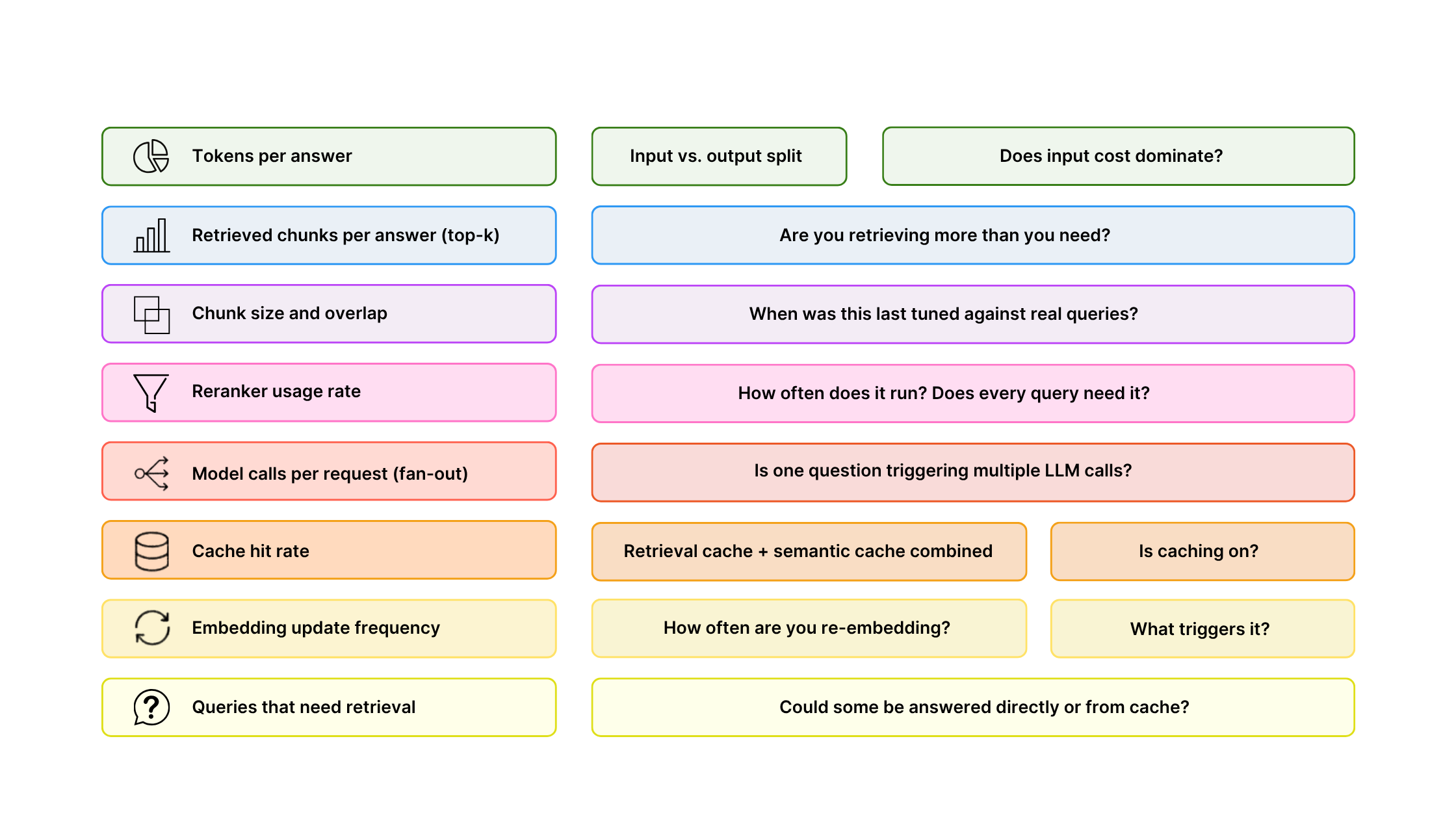
If several are unknown, you are operating blind, because you can't enforce what you don't measure.
The biggest savings will come from controlling what reaches the model.
Chunking: Chunk size determines context per retrieval. It's easy to set it once and forget it. However, tuning chunk size to real query patterns can reduce retrieval depth without hurting quality while directly cutting tokens per request.
Hybrid search: Higher precision means you can retrieve fewer chunks while maintaining quality. Fewer chunks means fewer tokens sent to the model. This reduces wasted context.
Context pruning: Remove low-value segments before generation. Shrink prompt size while keeping answer quality.
Caching: Semantic caching can significantly reduce LLM costs in production workloads, with Redis reporting that it can cut LLM API costs by up to 68.8% in typical production workloads, while also improving latency by serving cache hits in sub‑100 ms. If the same question is asked 50 times in a week, don’t pay 50 times for generation. In practice, semantic and retrieval caches eliminate many redundant calls by serving repeated or similar queries directly from cache.
Model routing: Don't send every query to the strongest, most expensive model. Route simple queries to cheaper models. Escalate complex ones. The same applies to retrieval: not every question needs it.
In many production RAG systems, most token usage comes from the input context rather than the generated answer, so reducing input tokens often has a larger impact on cost than trying to optimize output length.
This is also where governance and operational overhead break down. If retrieval, reranking, caching, and model selection live in separate services, policy becomes a cross-team coordination problem.
In many RAG architectures, retrieval lives in one service, reranking in another, generation in still another. On top of this, caching is often inconsistently applied, routing is ad hoc, leading each team to make reasonable local decisions, but global cost discipline ends up scattered across teams.
In many systems, there is no single API orchestration boundary where you can cap retrieval depth, enforce token limits, apply caching consistently, route by query type, or trace fan-out before the model.
Teams respond with observation: logging inside services, checking cloud billing after the fact. But billing data tells you what you spent. It doesn't tell you why a request cost ten times more or which step is responsible.
A shared control layer is one effective way to get that visibility. Visibility is the prerequisite for enforcement.
You either centralize control, or you accept cost drift as a property of the system.
At minimum, you need per-request visibility across the full pipeline as close as possible to the final assembled prompt before generation:
- Input tokens
- Output tokens
- Retrieval depth
- Reranker usage
- Model selection
- Total cost per request
This must reflect the fully assembled request before generation—not individual service logs stitched together afterward.
RAG is not automatically cheaper. It trades cost for accuracy and freshness, and without control, cost can exceed alternatives.
In narrow domains with stable knowledge and infrequent updates, a fine-tuned mid-size model without retrieval may be simpler and less expensive. If your workload is dominated by repetitive queries, a caching-first architecture may eliminate most model spend before retrieval matters. In strict governance environments retrieval without a control layer introduces risk.
RAG pays off when retrieval depth, context size, caching, and routing are actively managed. Left on defaults, cost drifts up regardless of your model.
Most AI systems are assembled from separate retrieval, caching, tool, and model layers. As these systems grow, cost control and governance depend on teams coordinating across services rather than enforcing policy in the architecture itself.
A shared router layer creates a single enforcement point. Instead of each service deciding independently how much context to send or which model to call, policy can be applied consistently before generation.
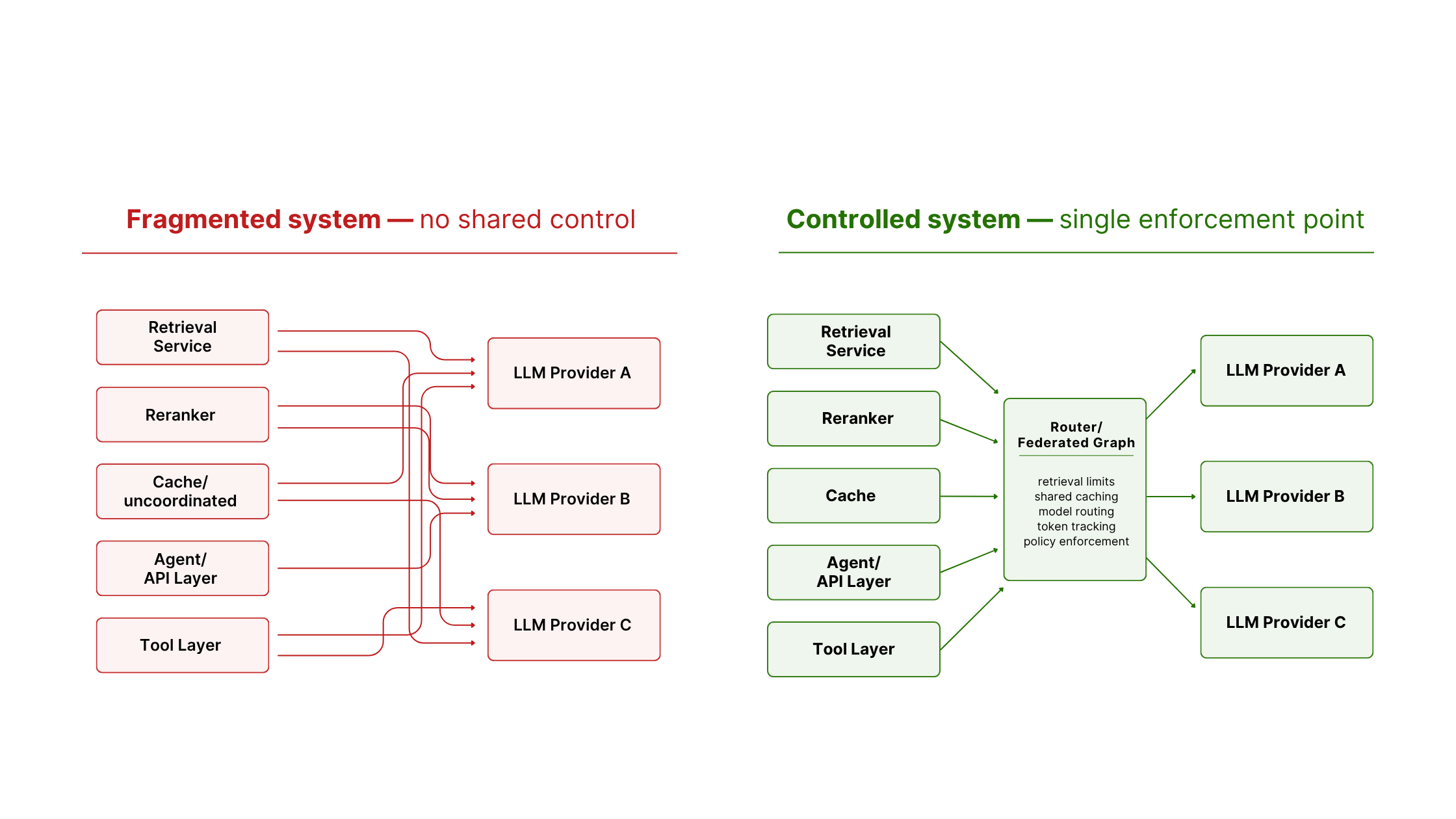
This turns cost control and governance into system behavior, not team coordination. It also removes the need to rebuild control logic as systems scale.
WunderGraph’s Router provides that shared control layer across the federated graph:
- Predictable spend: Retrieval limits, caching, and model routing are enforced in one place, reducing hidden fan-out and unnecessary token usage.
- Enforceable governance: Policies apply before generation across the full request path, not only through service-level conventions or after-the-fact monitoring.
- Faster scaling: Teams can add AI workflows without rebuilding control logic across services.
If your AI spend or system behavior is unpredictable, start here:
RAG systems rarely fail from one bad decision — they drift. Retrieving a few more chunks per query, a reranker added "just in case," an extra tool loop, a larger chunk size: each change looks harmless alone, but together it can become expensive. Without a shared boundary enforcing retrieval and generation policy, systems tend to drift toward higher token consumption over time.
The first step is visibility. Run the measurement checklist above. If several metrics are unknown, that's where you should start. Once you see where cost multiplies, you can control it.
If you want centralized cost control, you need a single enforcement point. The Router is one way to implement it.
If you are thinking about this as a router-level control problem, Yury covers Cost Control for Your Supergraph, showing how the same idea applies to GraphQL workloads by estimating and enforcing expensive operations before they reach downstream services.
For the AI side of the architecture, Jens wrote a post about how GraphQL Is the API Layer AI Agents Actually Need, explaining why typed, queryable APIs help agents request only the data they need instead of flooding the context window.
Frequently Asked Questions (FAQ)
A shared layer where retrieval limits, caching, model routing, and token tracking are enforced before generation, instead of being scattered across services.
No. In narrow domains with stable knowledge, a fine-tuned mid-size model without retrieval can be simpler and cheaper. RAG pays off when retrieval, caching, and routing are actively managed.
Start with retrieval depth and caching. Tune retrieval depth against real query patterns, add semantic caching for repeated queries, and gate rerankers and optional MCP tool paths behind confidence thresholds before changing models.
Local optimization across separate retrieval, reranking, caching, model, and tool layers—including MCP tools and other agentic API calls. Each team makes reasonable decisions, but no one sees the full request, so token usage and fan-out grow over time.
- Pinecone — Rerankers (RAG series)
- AI Token Usage Guide (2026) — LLM Token Usage Projection Guide
- RAG at Scale: How to Build Production AI Systems in 2026
- Context-aware RAG system with Azure AI Search to cut token costs
- Dense Passage Retrieval for Open-Domain Question Answering
- Pinecone — Chunking strategies
- Elastic — Hybrid search
- Claude Prompt Caching docs
- OpenAI Prompt Caching docs
Content Manager
Brendan Bondurant is the Content Manager at WunderGraph, owning technical content across GraphQL Federation, API tooling, and developer experience. He partners with leadership on product and company messaging and works cross functionally to align positioning, terminology, and content strategy across channels.

Data Architect: GTM & MI
Tanya brings cross-functional background in Data & MI, CMO, and BD director roles across SaaS/IaaS, data centers, and custom development in AMER, EMEA and APAC. Her work blends market intelligence, CRO and pragmatic LLM tooling teams actually adopts and analytics that move revenue.


