
From 10+ Seconds to Under One: Solving Their Slowest Operation

A growing personal finance marketplace hit severe planning delays on its Apollo Gateway, with complex queries taking more than 10 seconds and blocking traffic. After migrating to WunderGraph Cosmo and enabling the Cache Warmer, planning latency dropped by roughly 90–95 percent, and previously slow operations became 12–18 times faster. The team was able to remove fragile prewarm scripts and stabilize performance, leading to safer upgrades and continued growth.
The company requested anonymity to avoid drawing attention to internal architecture decisions that are still evolving. Large consumer finance platforms often keep infrastructure changes private to reduce unnecessary scrutiny from partners and to avoid creating expectations about future technical roadmaps. Identifying information has been removed as a precaution.
A personal finance marketplace ran its platform on Apollo Federation, with a Node.js Apollo Gateway in front of roughly 10 subgraphs. Many of the subgraphs were Node services, with one written in Go. The setup worked when they supported fewer product lines, but as the system expanded, the gateway became a bottleneck.
Complex requests began exposing long planning times. For example, some queries took more than 10 seconds to plan, and while they waited, other requests stacked up behind them. The slowdown spread across the graph and eventually began affecting the customer experience.
They were locked into an old Federation version. New subgraphs followed the current Apollo patterns, but the gateway could not validate or plan these shapes. They wanted to upgrade, but due to legacy code, it wasn’t safe.
The mismatch between subgraphs and the gateway widened, and engineers frequently needed to add patches to keep the system online. Every patch increased the maintenance weight and made the system harder to move forward.
This pattern is common. Early graphs behave well, but as more product domains attach to the system, slowdowns begin to appear. These slowdowns turn into planning delays, which turn into backlogs.
The team attempted to prewarm slow queries with a custom script. This helped until a new slow query surfaced. If they missed updating the script, performance across the entire graph dropped. The root cause was always the same: their gateway couldn’t keep pace, but they couldn’t upgrade out of the problem.
A modern graph needs fast planners, safe composition, and predictable cold-start behavior. It needs visibility across subgraphs and a way to handle new query shapes without adding risk. Their gateway was not providing that.
The team documented their requirements: strong Federation support, better performance on complex paths, lower maintenance weight, and the removal of the upgrade blocks that prevented them from shipping features. Cost mattered too, both in infrastructure and in team time.
The replacement had to support more traffic, more subgraphs, and more patterns without introducing new fragility.
WunderGraph Cosmo matched their requirements and included direct engineering support. Early in the evaluation, they found gaps around some Federation features. The WunderGraph team patched these issues or added missing support so the migration could continue.
This mattered.It kept the plan moving and gave the team confidence that Cosmo could handle a graph that was already large and still growing.
They followed a phased rollout. First, they matched the Cosmo Router to the gateway feature set. Next, they published schema updates to both registries so the gateway and Cosmo could remain aligned during testing. Once everything was stable, they shifted traffic one small slice at a time.
If they found a roadblock, they raised it, and the WunderGraph team resolved it. Internal processes stayed the same, subgraph teams retained ownership, and QA regression tests validated each new composition before it reached users.
As the platform grew, the team needed a clearer view of request paths and system behavior. Cosmo Studio provided this with traces, analytics, and schema visibility.
They saw slow requests, complex paths, and where subgraphs struggled.OTEL tagging confirmed that performance stayed on par or improved. Cache-hit metrics helped them tune the router after the rollout, and the studio replaced guesswork with direct signals.
The gateway struggled the most with heavy planning paths. Queries that took 10 seconds or more to plan would stall everything behind them. The manual prewarm script reduced some of the pain but always required updates, and any omissions degraded performance for the entire graph.
It preplanned the slowest queries before serving traffic and populated the cache with the plans that took the longest to compute. Later requests skipped the expensive planning step. Once they saw the results, they were able to remove their internal script entirely.
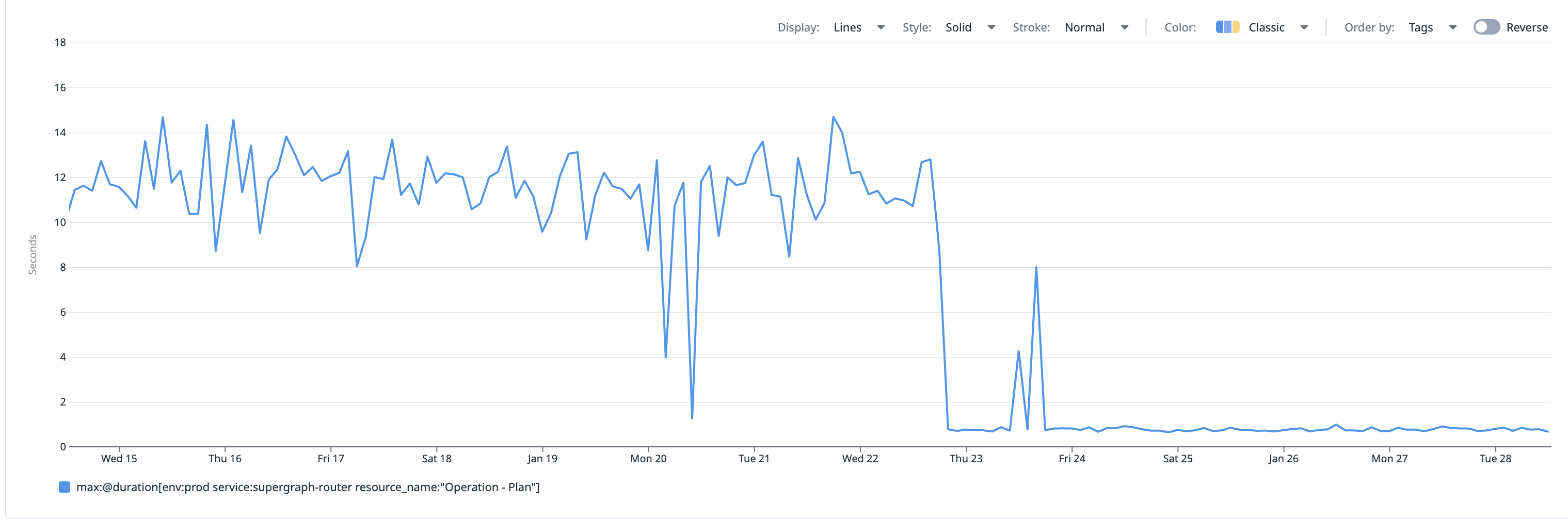
After enabling the Cache Warmer , they shared performance data for one of their slowest production operations. Before warming, the operation consistently took 10+ seconds. Immediately afterward, it dropped to sub-second execution and stayed stable.
No other changes were deployed during this window, allowing the team to clearly attribute the improvement to cache warming. Once the Cache Warmer was in place, latency fell by roughly 90–95 percent. The operation became 12–18 times faster, falling from double-digits to under a second.
The team had already seen how dangerous cold-start planning could be in high-traffic environments. During Super Bowl–level traffic preparation, it became clear that the real issue wasn’t throughput, but router instances starting with empty query-plan caches.
A slow-to-plan operation could take several seconds, and those outliers introduced latency that compounded under load.
Cold starts produced unpredictable, multi-second planning times the moment new instances came online. To avoid this, the preparation work warmed the query-plan cache ahead of traffic so the router never entered a cold-start window.
Cosmo’s Cache Warmer followed this model. It preplanned the most expensive queries before serving traffic and ensured the router started with a populated planning cache, eliminating the cold-start window.
The Super Bowl work showed the same pattern this marketplace saw firsthand: removing cold-start planning costs makes a federated graph safer, faster, and far more predictable during scale events.
We documented this pattern in detail during our Super Bowl scale-up analysis .
Performance improved and long planning times no longer block unrelated traffic. Latency stabilized. Supergraph updates became routine, and horizontal scaling behaved predictably. The team remained cautious about router version updates, but day-to-day operations became simpler.
Migrating to Cosmo provided a stable federated layer. They removed the limits that once slowed their product teams and gained a platform that could support growth without patches or workarounds.
Many teams encounter these issues as they scale. Slow planners. Blocked upgrades. Fragile scripts. Rising maintenance costs. The problems don’t start with outages. They start with delays, and the delays spread.
Cosmo helps resolve these issues at the root. The Cache Warmer eliminated heavy planning paths and removed cold-start hazards, giving the team a stable platform that could support real growth.
If your gateway shows early signs of strain, this path will feel familiar. The delays will grow. The patches will stack up. The upgrade blocks will get harder to clear.
Cosmo fixes this before it becomes a platform issue.
Frequently Asked Questions (FAQ)
Their Apollo Gateway had heavy planning paths that took more than ten seconds to compute. These slow plans stalled unrelated traffic and created backlogs across the entire graph.
They were locked into an older Federation version. Newer subgraphs followed modern Apollo patterns, but the gateway couldn’t validate or plan them safely, creating upgrade blocks and ongoing maintenance risk.
They removed it entirely. Cosmo’s Cache Warmer replaced the script by automatically preplanning the slowest operations and populating the query-plan cache before serving traffic, so new router instances no longer start with empty caches.
Their slowest production operation dropped from avg 10+ seconds to sub-second execution, yielding a 12–18× improvement with roughly 90–95 percent lower planning latency.
Long planning times stopped blocking unrelated traffic, supergraph updates became routine, and horizontal scaling behaved predictably because new router instances no longer suffered cold-start planning delays.
Content Manager
Brendan Bondurant is the Content Manager at WunderGraph, owning technical content across GraphQL Federation, API tooling, and developer experience. He partners with leadership on product and company messaging and works cross functionally to align positioning, terminology, and content strategy across channels.


