
Why you need a Package Manager for APIs


Archive Notice
This article is archived and no longer maintained. It describes an earlier version of WunderGraph built around the WunderNode and a "package manager for APIs" concept, which is no longer part of the current product. The examples and setup steps may not work as described. For current documentation and guidance, see https://wundergraph.com/cosmo
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
TL;DR
The post builds one example app, a weather API plus a jobs API in Next.js, and compares three ways to integrate them: client-side, server-side (the BFF pattern), and WunderGraph as a "package manager for APIs." Client-side integration is the easiest to start with but creates tight coupling, can't store secrets securely, and piles on boilerplate. A BFF removes the tight coupling and centralizes authentication and caching, but you pay for it in implementing, deploying, and maintaining the backend. The package-manager approach aims to give you the BFF pattern at lower cost: you declare your API dependencies in a config file, WunderGraph composes them into a virtual GraphQL schema, and it generates the BFF (hosted on the edge) plus a thin, typesafe client that handles login, caching, and invalidation, so you get authentication and edge caching by configuration with zero boilerplate.
Let's imagine we're building a modern web application using NextJS. Our task is to use two APIs, one for weather, one for jobs, and combine them into a product. Our users should see the current weather and get a list of jobs. This should sound like a pretty common task, developers have to accomplish every day across the world. It's not extremely challenging, but it still takes some effort. Before implementing the application, we have to make a few considerations:
- How do users log into the application?
- How do you fetch data from both APIs?
- Should we directly call the APIs from the client?
- Should the integration happen in a backend application?
- How do we store the secrets, e.g. API keys?
- Do we have to secure data?
- How do we keep the UI updated with rapidly changing data, e.g. weather?
- How can we make the application easy to evolve and expand? (loose coupling)
- What API client should you use?
- How do we implement caching?
- What about cache invalidation?
One possible way to build this application is by integrating both APIs directly within the client application. Another approach is to build a backend for frontend to integrate the APIs in a secure backend. The third approach we'd like to take a look at is using WunderGraph, the package manager for APIs. We'll look into all three approaches, their architecture and discuss their pros & cons.
Client-side integration is one of the easiest approaches which also comes with some drawbacks. In this scenario, the application code sits side by side with the two clients, one for each API. It's clear that the client application talks directly to the APIs, creating a tight dependency between them.
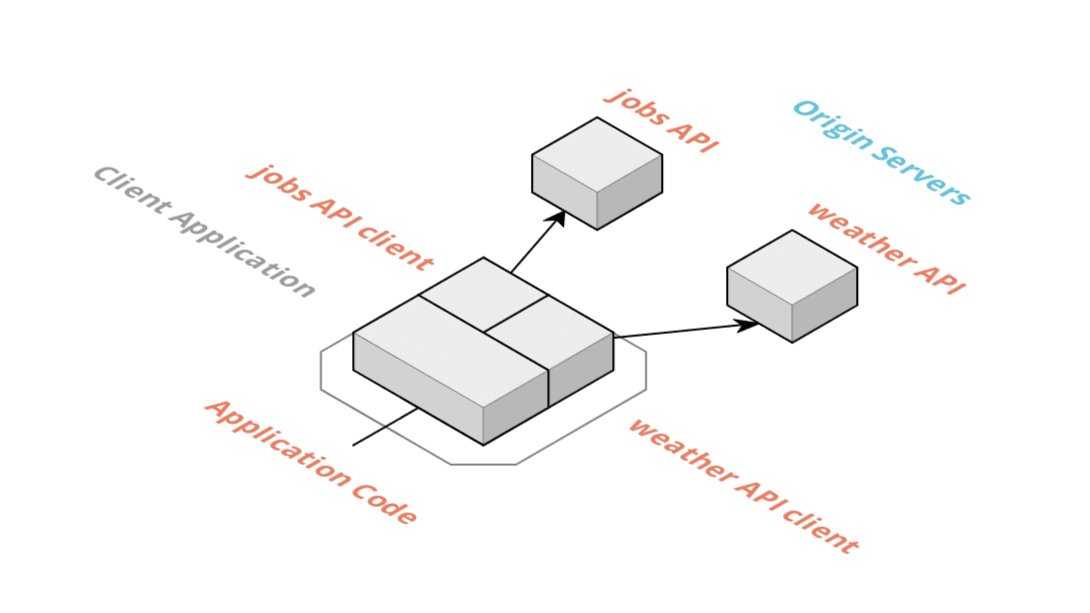
Pros
- This approach comes with an easy to understand architecture
- No additional backend needs to be deployed or operated
- No extra dependencies, except the two APIs
Cons
- We have a tight coupling between the client application and the two APIs
- We need to choose a client technology to talk to the APIs
- It's more complex to implement a unified authorization layer that works for both APIs
- Implementing a unified caching strategy for both APIs is also rather complex
- We need to handle multiple API clients in the client, the complexity of the client application will grow if we add more APIs
- There's no way to store secrets in the application as the code is public so it's harder to limit access to the APIs
- Lots of boilerplate required to talk to both APIs, e.g. setting up code generation for both APIs so that we can enjoy some type-safety
- In general, this approach can get us results pretty fast. On the other hand, the drawbacks might overwhelm us in the long term.
The fact that we cannot store secrets in the frontend might even be a deal-breaker, depending on the project requirements.
The second approach we'd like to look at is server-side integration. This pattern is also well known as "Backend for Frontend" (BFF). We're essentially moving the complexity of the integration to a secure server. This adds complexity but comes with a lot of benefits.
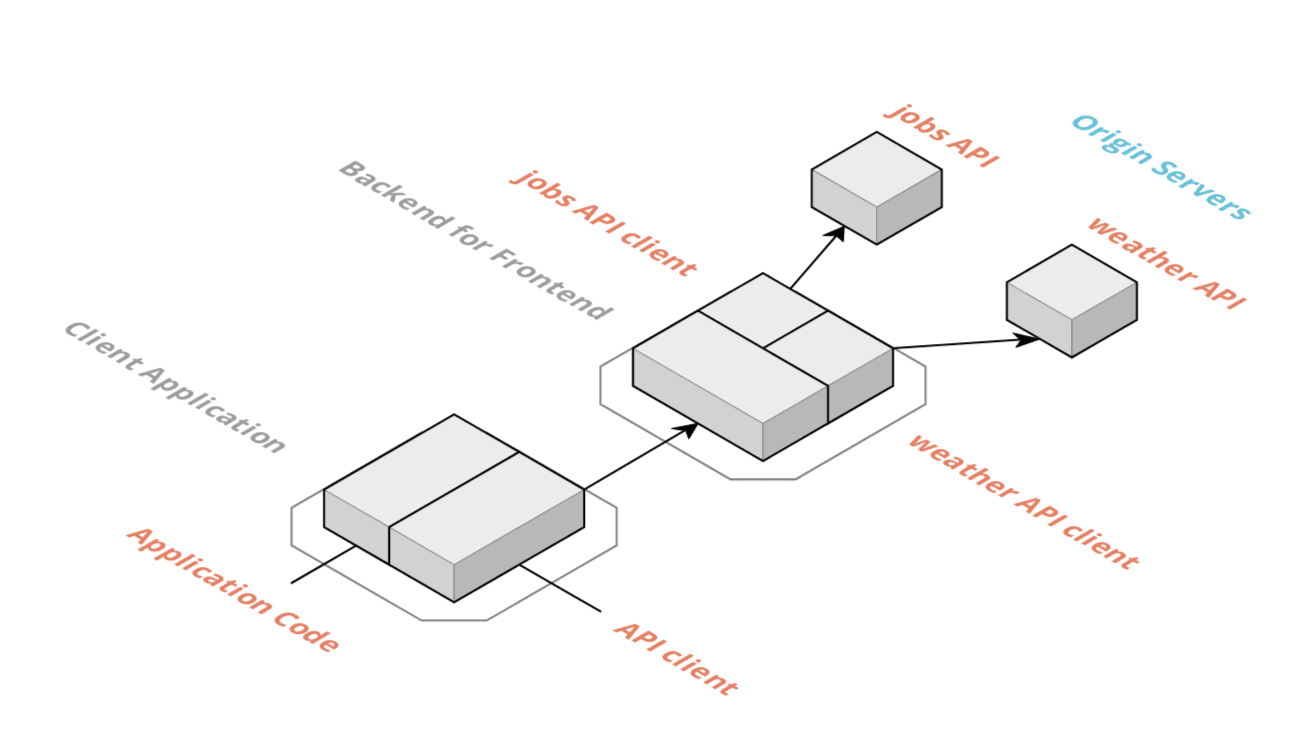
In this scenario, the client application only has a single API client which is talking to the BFF. The BFF consists of all the business logic, implements authentication & caching and contains API clients for both upstream APIs. The BFF secures access to the APIs and can apply general rules to both of them.
Pros
- There's no more tight coupling between the client application and the upstream APIs as they are abstracted away by the BFF.
- Rules like rate limiting, authentication & caching can be implemented in a unified way in the BFF
- Secrets like API keys can be stored securely in the BFF
- Less complexity in the client application as we can define exactly the API the client asks for in the BFF
Cons
- Implementing, deploying and maintaining the BFF adds a lot of complexity (cost) to the project
- the problem of solving authentication & caching still needs to be solved, just in a different layer
- cost for maintenance and extension of the application increases as both client and server (BFF) needs to be touched and deployed
- the boilerplate to talk to both APIs is still required, it only moved to the server
- Building a BFF is a very good strategy to tackle the problem. While it comes at a cost, compared to a client only application, our architecture is a lot cleaner and easier to maintain. One of the main benefits is that we have no more tight coupling between the client application and the upstream APIs. Ideally, we want a BFF but at a lower cost, easier to maintain and evolve. That's where an API package manager comes into play.
As stated above, implementing a BFF is a very clean and easy to maintain architecture to solve a common problem like the one described in the scenario above. Our goal is to use the BFF pattern but reduce implementation and maintenance cost while increasing the developer experience. What is a package manager for APIs?
Throughout our careers, we had to solve many problems similar to the scenario described above. The problem is always the same. Get data from x different services that speak y different protocols. Compose all APIs together, secure the communication and make sure that content that can be cached will be cached to ensure good performance of the problem.
Getting data from different services and composing it together to form something new should sound very familiar to developers. Maybe not (yet) if we're talking about APIs but we know the pattern very well when we use code from others. Package managers help us bring all the dependencies into one place to build something new on top of them. We don't have to manually install code from others. We don't have to manually copy files to other computers if we want to share our code with our teammates. Instead, we push code to git repos and npm repositories so that others can easily pull it.
Yet, when it comes to APIs, we seem still live in a cave. If you're super lucky, someone pushed an OpenAPI specification somewhere. Or maybe you have to deal with a SOAP WSDL? There's also gRPC. What about GraphQL? When you deal with high class products like e.g. Stripe you're lucky because they offer an SDK, but does that really solve the problem? There's no way to simply "install" all the APIs you need and start using them. Even with SDKs available, how does a codebase scale if you need many of them? How do you keep SDK updated and compatible if you don't have the resources like Stripe?
Let's have a look at the Architecture of WunderGraph to understand how we can solve this problem.
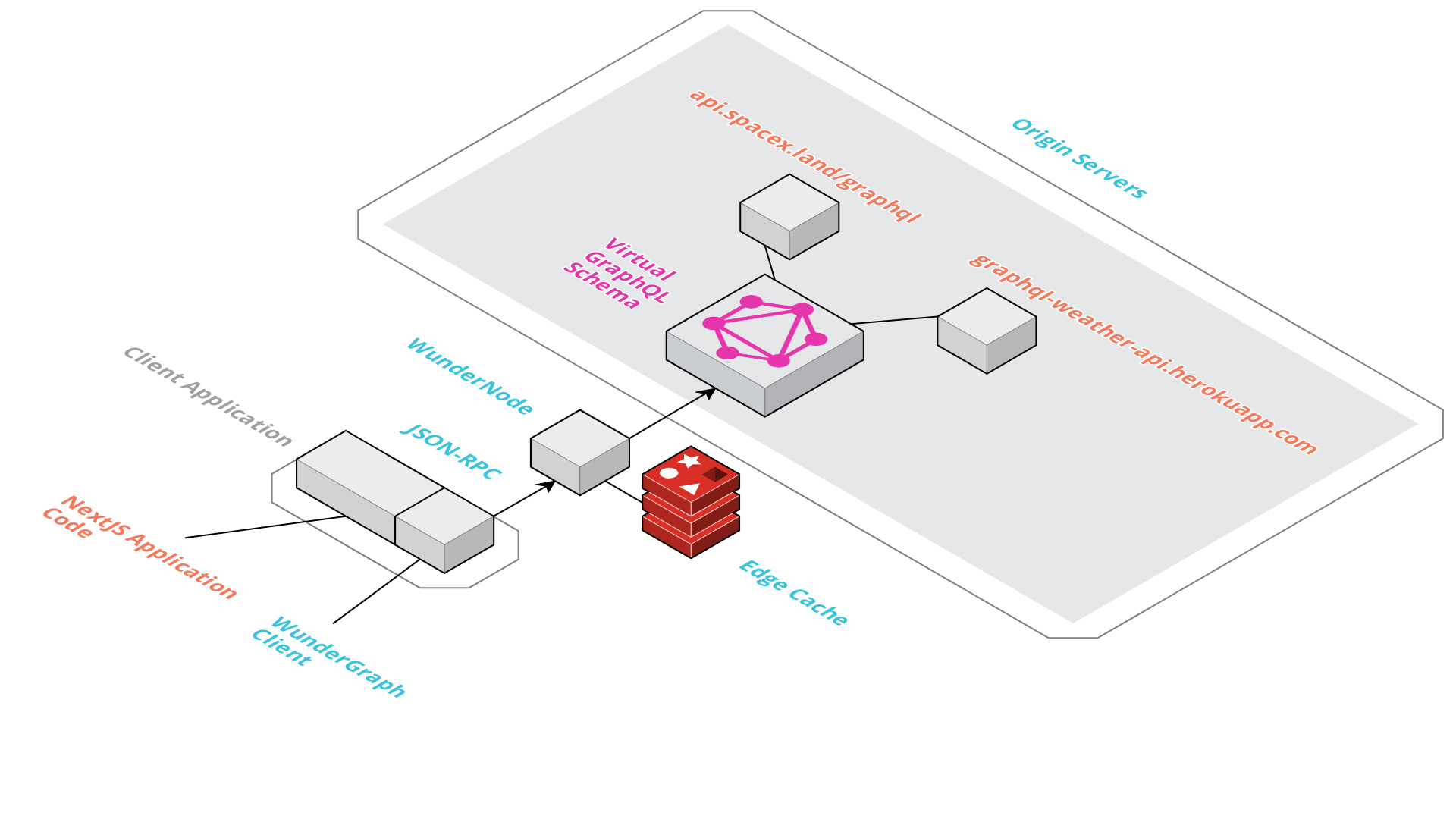
All our Dependencies (APIs) are on the right. WunderGraph composes them into a virtual GraphQL schema. WunderGraph supports REST APIs (via OpenAPI Specification), GraphQL and Federation and can be extended for any other Protocol. The specifications of the origins will be automatically transformed into a virtual GraphQL schema. GraphQL has a very expressive type system and allows us to query exactly the data we need. Because GraphQL comes with some other drawbacks, we're not directly exposing this API, which is why we call it "virtual".
We can specify all our dependencies in a configuration file, just like a package manager. WunderGraph then introspects all the schemas and builds the virutal GraphQL API. What's left is that we have to write GraphQL queries, mutations and subscriptions to express the operations we need for our application. We're able to configure caching & authorization rules for each individual operation. WunderGraph then generates two components, a WunderNode configuration and a typesafe client. The WunderNode As we've discussed above, we need a Backend for Frontend but ideally, we don't want to implement it. The WunderNode is our BFF. It's a service provided by WunderGraph, hosted on the Edge so that content can be cached as close to your users as possible. You don't have to worry about WunderNodes, we do. Simply add your dependencies, write your Queries and configure your Operations. The WunderNode configuration gets automatically generated. You can deploy your APIs to them in seconds.
The BFF alone wouldn't fully solve the problem. We still need a client in our frontend application. However, you also don't have to worry about the client. We're generating the client for you. The client is very thin but super smart. It knows how to log your users in and out. It knows how to cache data and when and how to invalidate it. Of course, the client also knows about all the operations, their inputs and how the responses will look like. The client is typesafe. You'll love using it.
Pros
- like the BFF, no tight coupling between your upstream APIs and the client
- Authentication via configuration
- Edge Caching via configuration
- Typesafe generated client
- you don't have to build, maintain and operate a BFF
- zero boilerplate
- zero touch secure by default
- extreme developer productivity
Cons
- You have no more excuse wasting time with writing boilerplate and custom integrations. You have to focus on activities directly related to business value.
By the way, we're using WunderGraph to build WunderGraph. We don't ever want to manually integrate APIs again. That's why we use our tool to build our own service. This also helps us to improve the developer experience as much as we can. Whenever we're not satisfied with the experience, we immediately improve it. We wouldn't want to use a tool which doesn't perfectly solve the problem for oursevles. So far, we're super happy with the results and believe you'll love it too.
Frequently Asked Questions (FAQ)
It creates tight coupling between the client and the APIs, requires choosing a client technology, makes unified authorization and caching complex, can't store secrets because the code is public, and adds a lot of boilerplate.
It moves the integration complexity to a secure server that holds the business logic and API clients for the upstream APIs, so the client only talks to the BFF, which removes tight coupling and lets rate limiting, authentication, and caching be implemented in a unified way with secrets stored securely.
Implementing, deploying, and maintaining the BFF adds a lot of complexity and cost, the authentication and caching problems still need to be solved in a different layer, and both client and server must be touched and deployed.
It's an approach where you specify all your API dependencies in a configuration file, and WunderGraph introspects their schemas and composes them into a virtual GraphQL schema, similar to how a package manager brings dependencies into one place.
It generates the BFF itself, hosted on the edge, and a thin, typesafe client that knows how to log users in and out, cache data, and invalidate it, so you don't have to build, maintain, or operate a BFF yourself.
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


