
When to Migrate from Cosmo OSS

TL;DR
Cosmo OSS is a production-grade, Apache 2.0-licensed GraphQL Federation platform that works well for early adoption, internal evaluations, and smaller-scale deployments. As teams grow and systems get more complex, the operational overhead of self-managing schema coordination, observability, compliance, and infrastructure increases. Cosmo Enterprise builds on the same core and adds governance (schema registry, composition checks, contracts), full observability (Advanced Request Tracing, ClickHouse-powered analytics, OpenTelemetry), security and compliance (SOC 2 Type II, HIPAA, GDPR, RBAC, SSO), and formal support, without requiring a rebuild. Migration is incremental, CLI-based, and non-disruptive because both versions share the same engine.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
Cosmo is a production-grade GraphQL Federation platform trusted by some of the most demanding engineering teams in the world. It’s developer-friendly, supports both Federation v1 and v2, and is licensed under Apache 2.0 . That makes it a powerful foundation for any organization evaluating federation at scale.
Cosmo OSS is ready for real workloads from day one. Startups use it to ship quickly; enterprises use it to validate architecture and make decisions before rolling out more broadly. The same core technology powers Cosmo Enterprise, so when it’s time to move beyond proof-of-concept, you’re not rebuilding—you’re stepping into a tested platform with full observability, governance, and support.
Cosmo OSS gives teams a fast on-ramp to Federation without locking them into a commercial platform too early. If you already run services like Postgres, Redis, or your own observability stack, Cosmo fits in without disruption. The Helm chart works out of the box for most teams, so you can collect logs, test routing, and evaluate the architecture in real conditions without a heavy lift or vendor lock-in.
Built for speed, it lets teams iterate quickly, deploy fast, and experiment safely. The self-contained architecture makes it easy to get started: a single CLI and Router is enough to begin. No hosted control plane, central server, or extra infrastructure required.
You can deploy anywhere, customize freely, and fork if needed, because there is no vendor lock-in.
That’s why Cosmo OSS is an ideal choice for early adoption, internal evaluations, or rolling out Federation in lower environments before committing to the full platform.
Cosmo OSS is licensed under Apache 2.0, which makes it open, permissive, and production-ready. But open source is not the same as free support.
Maintainers donate software, not time. If your team relies on OSS at scale, the trade is collaboration, not consumption. Community users are encouraged to report bugs, flag security issues, or open well-scoped PRs—but no one is owed prioritization or support without a contract in place.
As Jens put it in The Good Thing, Episode 16 (paraphrased), “Open source means you can use it. It doesn’t mean I’ll teach you how to use it.” That boundary matters. OSS works because people respect the limits of volunteer time and unpaid stewardship; when users push past that, it breaks down.
Support, SLAs, onboarding, security reviews, and compliance are not what open source provides. That is exactly what Cosmo Enterprise exists to deliver.
Even helpful PRs come with cost. Once we merge your PR, we’re responsible for it: every contribution requires thorough review, testing, and long-term maintenance. A change may not be merged if it adds too much complexity or doesn’t align with the project’s direction.
OSS is a distribution model, not a business model. You can run Cosmo OSS at any scale, but if you want guarantees, support, and architectural backing, you need more than a repo—you need a partner.
Cosmo Enterprise exists so you don’t have to become an expert just to ship. Or as Stefan put it in the same episode, “There are maybe ten real federation experts in the world. Eight of them work here.” That’s not bravado, it’s context.
Short answer: migrating adds governance, observability, performance tooling, and formal support on top of the OSS core—without changing how you build.
Cosmo Enterprise is the commercial counterpart to the open source stack. It includes everything in Cosmo OSS, enhanced with governance, observability, performance tooling, and formal support. The shift isn’t about changing how you build, but about protecting what you build at scale.
Once multiple teams contribute to a shared supergraph, governance is no longer optional. Cosmo Enterprise provides the controls needed to move fast without breaking shared infrastructure.
The schema registry tracks versions and validates changes automatically. Composition checks run on every change, ensuring consistency across environments. Contracts let you tailor schema exposure, while field-level usage data shows you what’s safe to change.
When something breaks, it needs to be clear where and why. Cosmo Enterprise gives you full traceability across federated operations, environments, and regions.
Advanced Request Tracing (ART) connects each request across services. Field-level analytics reveal patterns in usage and performance. ClickHouse powers high-cardinality queries, so you can drill into the details without lag.
Native support for OpenTelemetry makes it easy to integrate with your existing dashboards—no need to maintain a separate observability stack just for the graph.
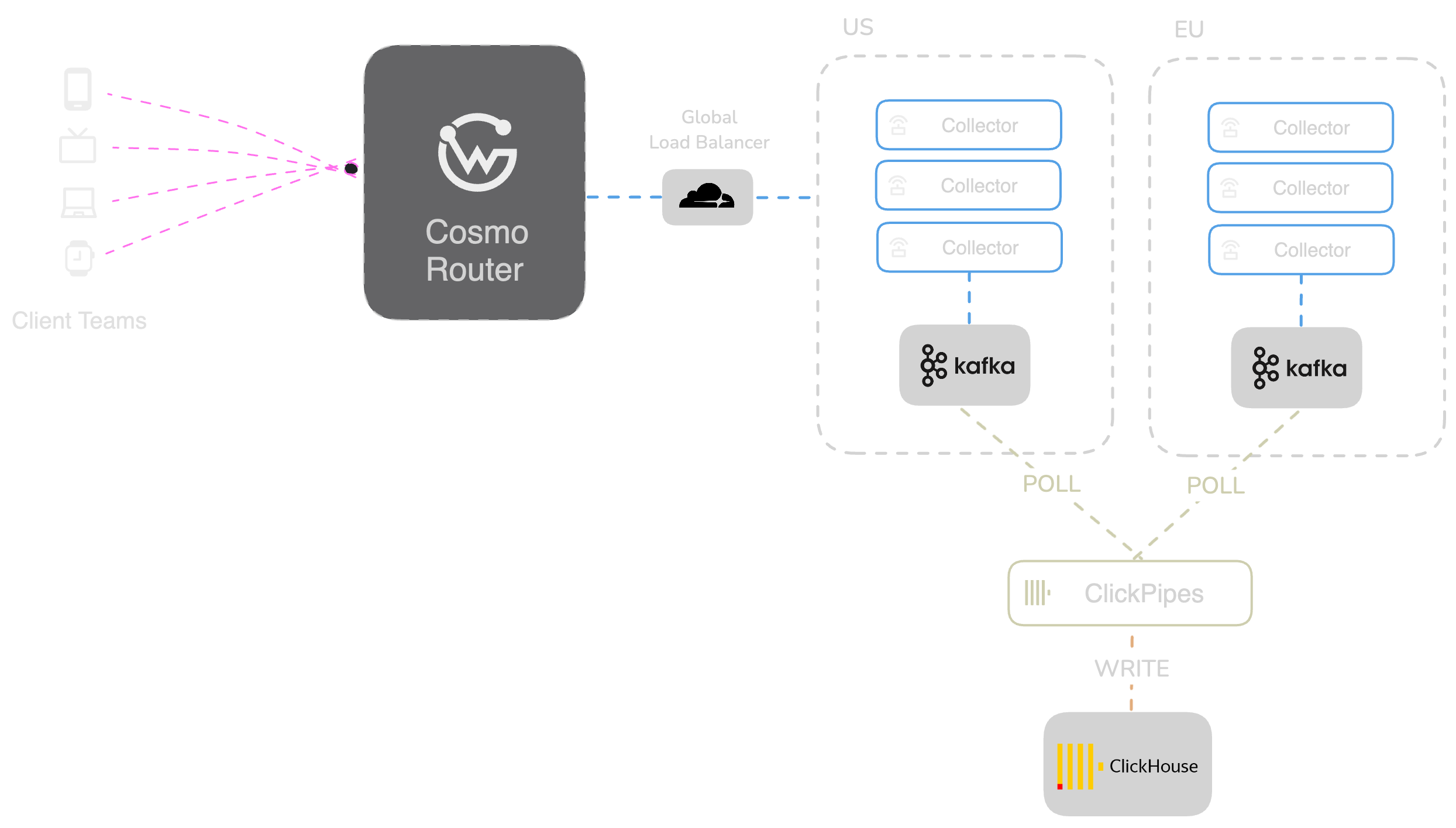
Cosmo Enterprise ships with a fully integrated observability pipeline. This diagram shows how it works across global environments:
Enterprise deployments require a different security posture, and Cosmo Enterprise meets that bar.
The Router is self-hosted, so your data stays in your environment; only anonymized metadata is shared with Cosmo Cloud. The system enforces query complexity limits, restricts operations to trusted documents, and is designed to block the OWASP Top 10 GraphQL threats.
Security is not an add-on, but the baseline. It is SOC 2 Type II certified. GDPR and HIPAA compliant. It supports audit trails, SSO via OIDC or SAML, and fine-grained RBAC.
Cosmo Enterprise is built to handle whatever scale you reach. The Router is written in Go and optimized for low latency and minimal CPU overhead. Configuration updates are CDN-backed, so you’re not waiting during deploys or failovers.
Companies processing billions of requests per month run Cosmo in production, and performance holds as the scale changes.
You also get direct access to the team that built the platform. From incident response to schema tuning, Enterprise support is real help from real engineers.
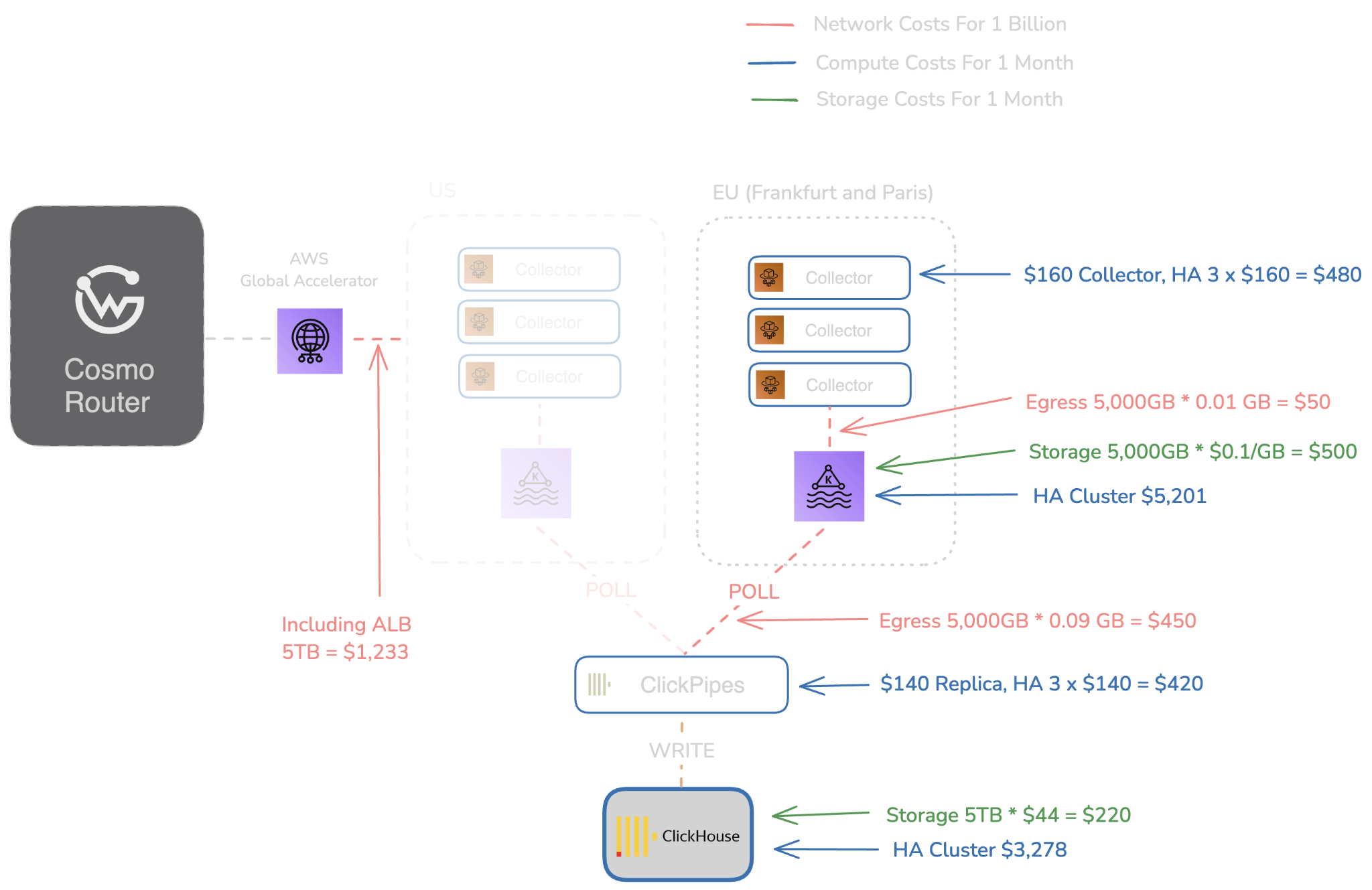
This shows what a typical observability pipeline looks like at 1B requests per month, including regional HA setups and storage costs. Estimated monthly costs: $9,379 compute, $1,733 network, $720 storage, totaling $11,832/month at 1B requests, or $44K at 10B.
Cosmo Enterprise adapts to your trust boundaries, team size, and compliance needs. Deployment is not a constraint, but a feature.
Whether or not you want full control, the platform supports your model without asking you to trade flexibility for convenience.
Cosmo Cloud handles the entire control plane: the schema registry, studio, observability, and analytics. You deploy the Router, and nothing else is required of your team.
This model is ideal for teams that want the benefits of GraphQL Federation without the operational overhead. WunderGraph operates the backend, including ClickHouse, Kafka , Redis , Postgres, and Keycloak. There’s no maintenance or patching your team is responsible for.
The same platform engineering team that built Cosmo runs it, with direct involvement from the CTO. Usage-based pricing is transparent, with discounts as you scale. By offloading ops, monitoring, and compliance, you can reduce your total cost of ownership by six figures per year.
In hybrid mode, you host the Router inside your own infrastructure while WunderGraph handles everything else.
This gives you control over data flow while still benefiting from cloud-native governance. Only anonymized metadata is sent to the cloud; payload data stays in your environment.
Hybrid deployment is common in regulated industries where data locality is non-negotiable. It lets you meet internal policy without sacrificing platform capabilities, which is why it’s often the first step toward Enterprise. This model gives your team full control over the data path while offloading governance, analytics, and schema management to the Cosmo Cloud platform.
Cosmo Cloud and Hybrid deployments share the same core architecture. Here’s how the control plane, Router, observability, and security services fit together:
For teams with strict compliance mandates or infrastructure investments, full self-hosting is available. You run it all: the Router, schema registry, studio, observability stack, and user access system.
This is the most operationally intensive model, but it also gives you complete control. Air-gapped deployments, sovereign cloud, and private environments are fully supported, and WunderGraph works alongside your team to get it up and running.
Just to be clear: open source does not equal self-hosted enterprise. Cosmo Enterprise is a feature set, and how you deploy it is up to you.
Short answer: you’ve outgrown Cosmo OSS when schema coordination gets risky, observability gaps slow debugging, operational load climbs, compliance demands mount, or performance lags behind traffic.
Cosmo OSS can take you far. But at some point, the cost of maintaining it outweighs the speed it once gave you. Here are the signs it’s time to move forward.
As more teams and subgraphs join the graph, schema coordination becomes harder to manage. Without automated checks and version tracking, composition issues can go unnoticed until they cause production problems. What once felt nimble now feels brittle.
Without field-level usage data or per-subgraph metrics , it’s hard to connect symptoms to causes. When something breaks, you’re left guessing instead of diagnosing. Reliability depends on observability, and OSS doesn’t give you enough to trace requests end to end.
If you’re maintaining Redis, Postgres, ClickHouse, Keycloak, backups, dashboards, and alerts without a platform team, you’re not just running a graph—you’re running an entire observability stack. The effort adds up fast.
If your organization is preparing for SOC 2, HIPAA, or internal audits, OSS alone won’t get you there. There’s no built-in RBAC, audit logging, SSO, or policy enforcement. You’ll have to build and maintain those layers yourself, or migrate to a platform that includes them.
When latency creeps up, config updates stall, and metrics lag behind traffic, it’s a sign the system isn’t keeping pace. Cosmo OSS is fast, but it’s not built for global-scale observability out of the box. As demand grows, you need infrastructure designed for it.
Cosmo Enterprise runs on Kafka and ClickHouse to power real-time analytics with global uptime and low latency—no matter the load.
If you’re managing schema merges, writing internal docs, maintaining workflows, and resolving incidents across teams, you’ve taken on platform responsibilities. Cosmo Enterprise gives you production-grade tooling, observability, and governance out of the box, so your team can refocus on building products instead of maintaining infrastructure.
Short answer: you don’t rebuild. Cosmo Enterprise uses the same core engine, so you migrate incrementally—often starting with one subgraph or a hybrid Router—without rewriting schemas or disrupting your teams.
Whether you’re using Cosmo OSS, Apollo Federation, or another gateway, you can scale into the platform without rewriting schemas. Cosmo Enterprise is designed for gradual adoption.
Most teams begin with a single subgraph, team, or environment. The OSS Router works with Cosmo Cloud out of the box, so you can enable analytics, governance, and studio without replatforming.
The Federation syntax and CLI stay the same. There’s no need to retrain teams or rewrite pipelines.
Hybrid deployment is often the first move. You self-host the Router and connect it to Cosmo Cloud for schema registry, composition checks, studio, and analytics.
This gives you the benefits of governance and observability without touching your data plane. It’s the fastest way to unlock Enterprise value while maintaining full runtime control.
Cosmo is fully Apollo Federation–compatible (see the migration guide). You can import your existing schemas, project structure, and composition logic using built-in tools to import schemas. In short, you swap out your router, not your entire architecture.
Your subgraphs don’t change. Your SDLs don’t change. You keep using the same wgc CLI, Docker images, and Helm charts. Schema pushes work as they always have, and Routers pull updates automatically from the CDN.
The entire system is designed to be non-disruptive. The Routers remain live and responsive—even if the control plane is offline. Cosmo OSS and Enterprise share the same core engine, which means migration is incremental, reversible, and never a cliff.
Most of these teams upgraded to Cosmo Enterprise when OSS tools, homegrown systems, or operational gaps started to limit progress. Each migration was driven by different needs: compliance, performance, governance, or scale.
In eBay’s case, they didn’t switch to Enterprise—they partnered directly with WunderGraph to shape the OSS core itself. Their investment and feedback helped ensure Cosmo could meet the demands of large-scale, self-hosted environments.
At eBay, our developers leverage Federated GraphQL management tools to enhance productivity and streamline ways of working, all in service of providing more innovative experiences for our customers. Our investment in WunderGraph’s highly performant open-source platform will help boost eBay’s API ecosystem and enable our teams to work faster and smarter in building products that help our sellers thrive.
— Bryan Woodruff, VP of Seller Experience Engineering at eBayeBay processes over 10 billion GraphQL requests per day. With their own data centers and dedicated infrastructure teams, they chose a fully self-hosted federation model that fits their scale and operational priorities.
In 2025, they joined WunderGraph as a strategic investor and design partner, working closely with the team to shape Cosmo for use in large, complex environments.
WunderGraph’s partnership with eBay has been a two-way collaboration. eBay gets the flexibility of an open source federation platform that fits their needs, while WunderGraph benefits from their real-world scale and feedback. As CEO Jens Neuse explained in TechCrunch :
I would say we are experts in federation, but we don’t have experience in eBay-scale problems. And so by having this very close relationship, they taught us everything in terms of how we need to build our product so that it can be integrated into companies like eBay, because they have very specific requirements.
eBay’s partnership with WunderGraph is more than a technical implementation, it is a shared commitment to open standards and collaborative infrastructure design at global scale.
kHealth operates under strict U.S. healthcare regulations, including HIPAA. They needed a GraphQL federation platform that could meet high compliance standards while remaining operationally lean.
The team originally planned to self-host the full stack. But after evaluating Cosmo Enterprise, they adopted a hybrid model: the Router runs inside their infrastructure, while the control plane, analytics, and Studio are managed by WunderGraph.
This setup allows them to:
- Maintain full HIPAA compliance without building custom security layers
- Reduce infrastructure overhead by offloading observability and governance
- Balance control and convenience by combining local data routing with managed federation tooling
Building it ourselves was something we talked about, but the amount of effort required to build and maintain it long term just wasn't worth it.
— Tim Caplis, Principal Software Engineer at SoundCloudSoundCloud adopted Cosmo to reduce infrastructure overhead, improve routing efficiency, and accelerate development.
They saw immediate results:
- Infrastructure costs dropped from $14,000 to $9,750 per month—even after adding new components.
- CPU usage fell from 600 cores to just 80, cutting compute by 86% and saving an estimated $265,000 annually.
- Query performance improved, with lower latency and faster execution across the board.
Development also sped up. Teams deployed changes faster, with less operational overhead and better integration between frontend and backend. By simplifying their architecture, they made their platform easier to scale and maintain.
Read the full case study →Soundtrack Your Brand adopted Cosmo Enterprise to gain clarity around schema usage and improve developer autonomy.
They gained:
- Field-level visibility through metrics and ART
- Better insight into subgraph performance
- Stronger collaboration through Studio and usage-based change validation
These capabilities improved the developer experience and reduced the overhead of coordinating across teams.
Read the full case study →Now, Cosmo presents all the relevant stats—how many queries run, their response times, and key performance metrics—making it much easier to communicate what's happening under the hood. This improved observability not only enhances request tracing but also helps teams understand how their queries run in a federated system. Ultimately, Cosmo has made it much easier for teams to buy into Federation.
— Stephen Wootten, Senior Software Engineer at On The BeachOn The Beach replaced their in-house federation layer with Cosmo Enterprise after delivery pipelines became bottlenecked by schema coordination.
With Cosmo, they:
- Unblocked schema changes across multiple teams
- Centralized workflows using Cosmo Studio
- Reduced time-to-merge and reenabled automated composition checks
Governance and contract-based workflows give teams autonomy without compromising the graph.
Read the full case study →Short answer: stay on OSS when the project is small, short-lived, or exploratory—one team, one graph, no compliance needs—and your team is comfortable managing infrastructure, metrics, and backups itself.
As Jens said in the same episode of The Good Thing, “We made Cosmo OSS open because we want it to be the standard.” If you’re building something small or short-lived, OSS may be all you need.
It’s the right fit for a prototype or side project. One team, one graph, no federation. No compliance or access control needs. If your team is comfortable managing metrics, infrastructure, and backups, you can move quickly without extra layers.
Cosmo OSS is production-ready, but it’s not support-ready. If you’re running real workloads in production, be prepared to support it yourself.
“We like OSS. We work on it because it’s fun and meaningful. But if you’re relying on it in production, it’s your responsibility too.”
— Jens Neuse, CEO & Co-FounderWhere OSS shines most is in evaluation. If you’re just beginning to explore Federation, Cosmo OSS gives you full access to the patterns and tools with no friction. You can test schema composition, try out subgraphs, and learn the workflow without vendor lock-in.
But OSS is not a safety net. Once you serve real users or hit scale, you need governance, observability, and platform support. That’s when Cosmo Enterprise becomes the right next step.
Open source Cosmo is a great place to start. It’s open, fast, and built for real-world use. But it’s not always the right place to stay.
When federation coordination gets risky, when visibility breaks down, when compliance expectations rise, or when platform overhead starts to eat into delivery time—those are signs you’ve outgrown OSS.
Cosmo Enterprise gives you the tooling, controls, and support to move forward safely. Whether you self-host or go fully managed, migration is incremental, CLI-based, and non-disruptive. No need to rebuild your graph. No need to lose momentum.
Start where you are and scale when you’re ready.
Frequently Asked Questions (FAQ)
Cosmo Enterprise is the commercial counterpart to the open source stack. It includes everything in Cosmo OSS, enhanced with governance, observability, performance tooling, and formal support. Both share the same core engine, so moving from OSS to Enterprise does not change how you build.
No. Cosmo OSS is licensed under Apache 2.0, which makes it open, permissive, and production-ready, but open source is not the same as free support. Maintainers donate software, not time. Support, SLAs, onboarding, security reviews, and compliance are what Cosmo Enterprise exists to deliver.
The signs are schema coordination getting risky as more teams and subgraphs join, limited visibility without field-level usage data, a growing operational burden from maintaining Redis, Postgres, ClickHouse, and Keycloak yourself, mounting compliance pressure from SOC 2 or HIPAA, and performance that lags behind traffic.
No. Cosmo OSS and Enterprise share the same core engine. Your subgraphs and SDLs do not change, and you keep using the same wgc CLI, Docker images, and Helm charts. Most teams migrate incrementally, often starting with a single subgraph or a hybrid Router, so the move is incremental, reversible, and never a cliff.
Three. Cosmo Cloud is fully managed, where WunderGraph operates the entire control plane and you deploy only the Router. Hybrid mode self-hosts the Router inside your infrastructure while WunderGraph handles everything else, with only anonymized metadata sent to the cloud. Self-Hosted Enterprise runs the full stack in your environment, including air-gapped and sovereign cloud deployments.
Stay on OSS when the project is small, short-lived, or exploratory: one team, one graph, no compliance or access control needs, and a team comfortable managing metrics, infrastructure, and backups itself. It is also the right fit for evaluating Federation without vendor lock-in.
SoundCloud cut infrastructure costs from $14,000 to $9,750 per month and reduced CPU usage from 600 cores to 80, an 86% drop in compute that saved an estimated $265,000 annually. They also saw improved query performance with lower latency after adopting Cosmo.
Ready to move beyond OSS? Cosmo Enterprise gives you the governance, observability, and support to scale federation with confidence. Talk to our team today.
Note: All quotes from Stefan and Jens in this post are paraphrased from The Good Thing, Episode 16 .
Content Manager
Brendan Bondurant is the Content Manager at WunderGraph, owning technical content across GraphQL Federation, API tooling, and developer experience. He partners with leadership on product and company messaging and works cross functionally to align positioning, terminology, and content strategy across channels.


