
When Prompt Injection Gets Real: Use GraphQL Federation to Contain It

From 2024 to 2025, major AI security breaches like Amazon Q, Vanna.AI, and EchoLeak showed that security controls built for human users fail when applied to large language models. The systems trusted model output as safe execution.
When LLMs run code, call APIs, or trigger builds, unverified logic slips through. The issue isn’t the model but the lack of trust boundaries to decide what an LLM is allowed to execute or access.
WunderGraph Cosmo applies federation principles—persisted operations, scoped access, and signed configurations—to enforce runtime boundaries that block unverified execution, prevent data leaks, and secure builds from tampering.

By 2025, large language models were writing SQL, pushing code, sending emails, and triggering builds. For many teams, this shift felt safe. Their apps already had authentication, logging, and API gateways in place.
But those controls were built for users, not models.
Incidents over the past year showed how that assumption fails. When an LLM receives instructions, those instructions can include executable logic hidden inside prompts, code snippets, or markdown links. Once the model runs that output, traditional defenses don’t trigger because there are no runtime gates to decide what an AI can execute, what data it can reach, and which artifacts it can deploy.
Each failure shared the same pattern:
- Instructions executed without verification
- Access scopes broader than intent
- Builds trusted artifacts without proof
The outcome: compromised environments, leaked data, and shaken confidence.
You don’t have to predict every malicious prompt, but you need to govern what executes, what’s reachable, and what’s trusted. Federation gives you the runtime surface to enforce those boundaries consistently across every service, schema, and client.
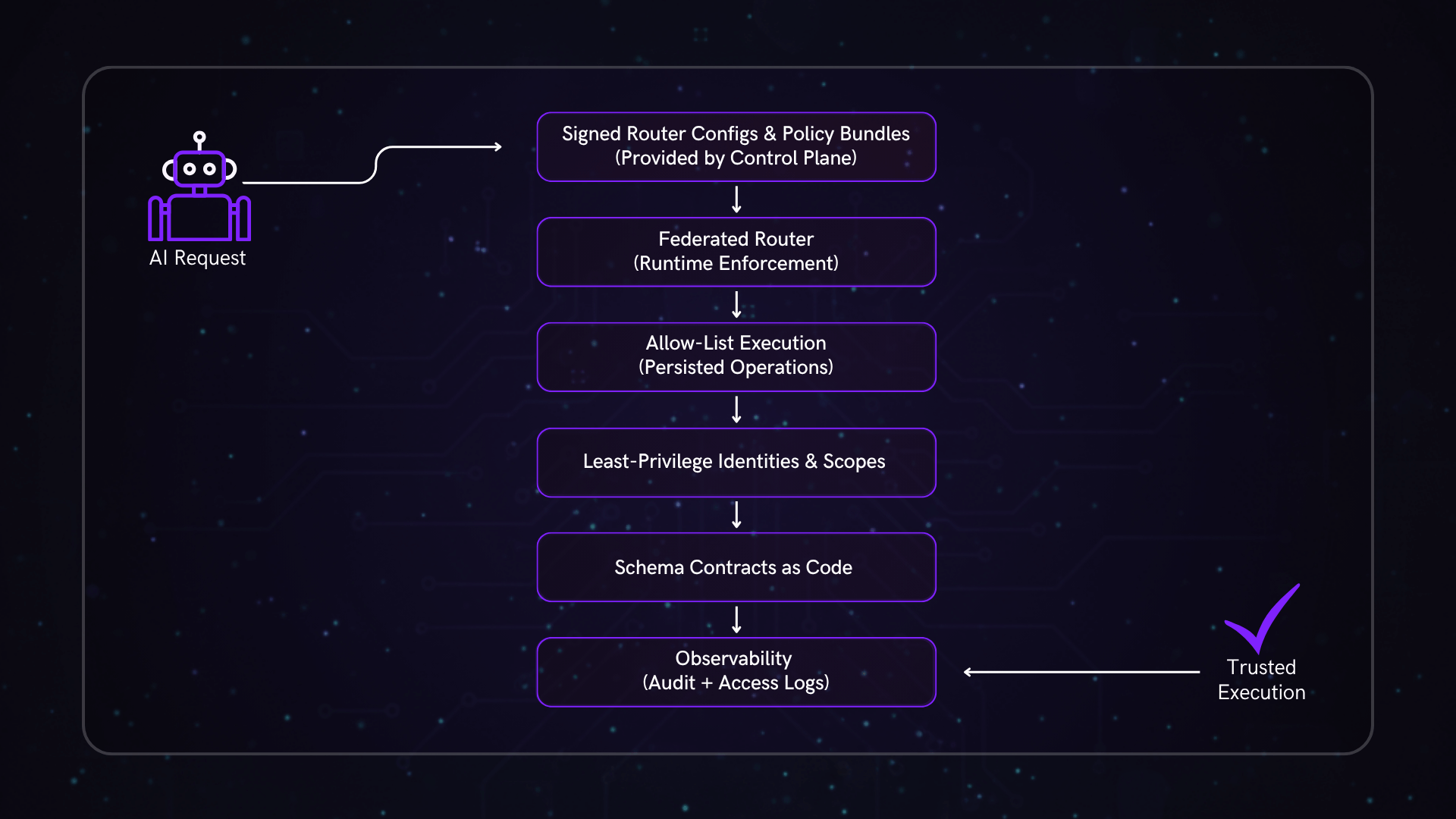
First, only approved operations run. Then we limit who can run them. We hide anything the client doesn’t need. Finally, we only ship signed configs.
Federation supports a secure-by-design posture by making safe defaults such as allowlists, scoped identities, signed configurations, and contract as code the standard path for execution.
Prompt injection isn’t a model flaw; it’s a system design gap that federation closes.
In a federated architecture, every query and credential passes through a central router that enforces policy across services.
In each major incident from 2024 to 2025, attackers didn’t break the LLM. They broke the system around it. Hidden instructions inside trusted data such as emails, repositories, or visualization requests were treated as valid actions.
Traditional controls like authentication and encryption assume threats come from outside the trust boundary. In prompt injection, the logic hides inside it.
- Persisted operations restrict behavior to pre-approved actions.
- Scoped access binds credentials to least privilege.
- Signed configurations verify and block tampered builds.
These controls don’t sanitize every prompt. They make sure the system won’t execute or expose anything outside its defined trust zone. It's a more durable defense than chasing injection patterns.
In mid-2024, researchers discovered a critical flaw in Vanna.AI, a Python library that turned natural language into SQL and visualizations. The issue wasn’t in the model’s reasoning. It was in the system’s trust.
CVE-2024-5565 • CVSS 8.1 • Affected: vanna <= 0.5.5 • Patched: none as of publication date (per GHSA)
Vanna’s visualization path used an LLM to generate Plotly code, then executed that code directly with Python’s exec() function. Any attacker who could influence the prompt could inject arbitrary Python instructions. The system ran the model’s code without review.
Execution chain: ask(…) → generate_plotly_code(…) → get_plotly_figure(…) → exec()
The result: remote code execution with a CVSS score of 8.1.
- No runtime gating: Model output was trusted and executed as-is.
- No scope separation: The LLM held implicit authority to run arbitrary logic.
- Default path executed LLM-generated Plotly code via
exec()whenvisualize=True(default).
JFrog recommends sandboxing execution and adding output-integrity checks. These were mitigations, not defaults in Vanna.
With a federated access layer enforcing persisted operations, the system would never execute LLM-generated code directly.
Cosmo can be configured to accept only pre-registered queries (persisted operations), and anything that is not on the allowlist is rejected. Even if a prompt produced Python or SQL code, it would be blocked from execution because it doesn’t match an approved operation.
By assigning the AI client a scoped role — for example, read-only analytics access — even approved operations would be limited in reach. The AI could query approved data, but couldn't invoke runtime commands or modify state.
Finally, signed configurations ensure that no unverified code or schema changes are deployed into production, closing the loop between definition and execution.
After the disclosure, the maintainer released a hardening guide to help users apply safer defaults.
In early 2025, researchers disclosed EchoLeak, where a single crafted email triggered Copilot to encode sensitive data into an image URL, exfiltrating it through a trusted proxy.
CVE-2025-32711 • CVSS 9.3 (Critical, Microsoft) / 7.5 (High, NIST) • Affected: Microsoft 365 Copilot • Patched: Mitigated (vendor guidance issued)
No sandbox failed or vulnerability was exploited.
The system followed user instructions as designed — but the result was a data leak.
Vendor response: Microsoft deployed mitigations and issued guidance for isolating untrusted input.
- No prompt isolation or input sanitization – malicious Markdown was accepted as trusted context.
- No output validation – generated outbound requests weren’t checked before execution.
Federation would have contained it through scoped identities, schema contracts hiding sensitive fields, and persisted operations denying unapproved requests.
In July 2025, AWS disclosed a supply-chain breach in the Amazon Q Developer VS Code extension.
CVE-2025-8217 • Affected: Amazon Q Developer VS Code Extension • Patch: Upgrade to v1.85.0; remove v1.84.0 instances entirely
An attacker exploited an over-scoped build token to gain repository access, merging a pull request that injected malicious prompt instructions into version 1.84.0.
Vendor response: AWS patched the extension, rotated credentials, and published incident details .
- Over-scoped token allowed unauthorized commits to reach production.
- No signature verification; signed artifacts would have blocked the tampered release.
- No runtime validation against an approved manifest before deployment.
The failure stemmed from missing trust boundaries.
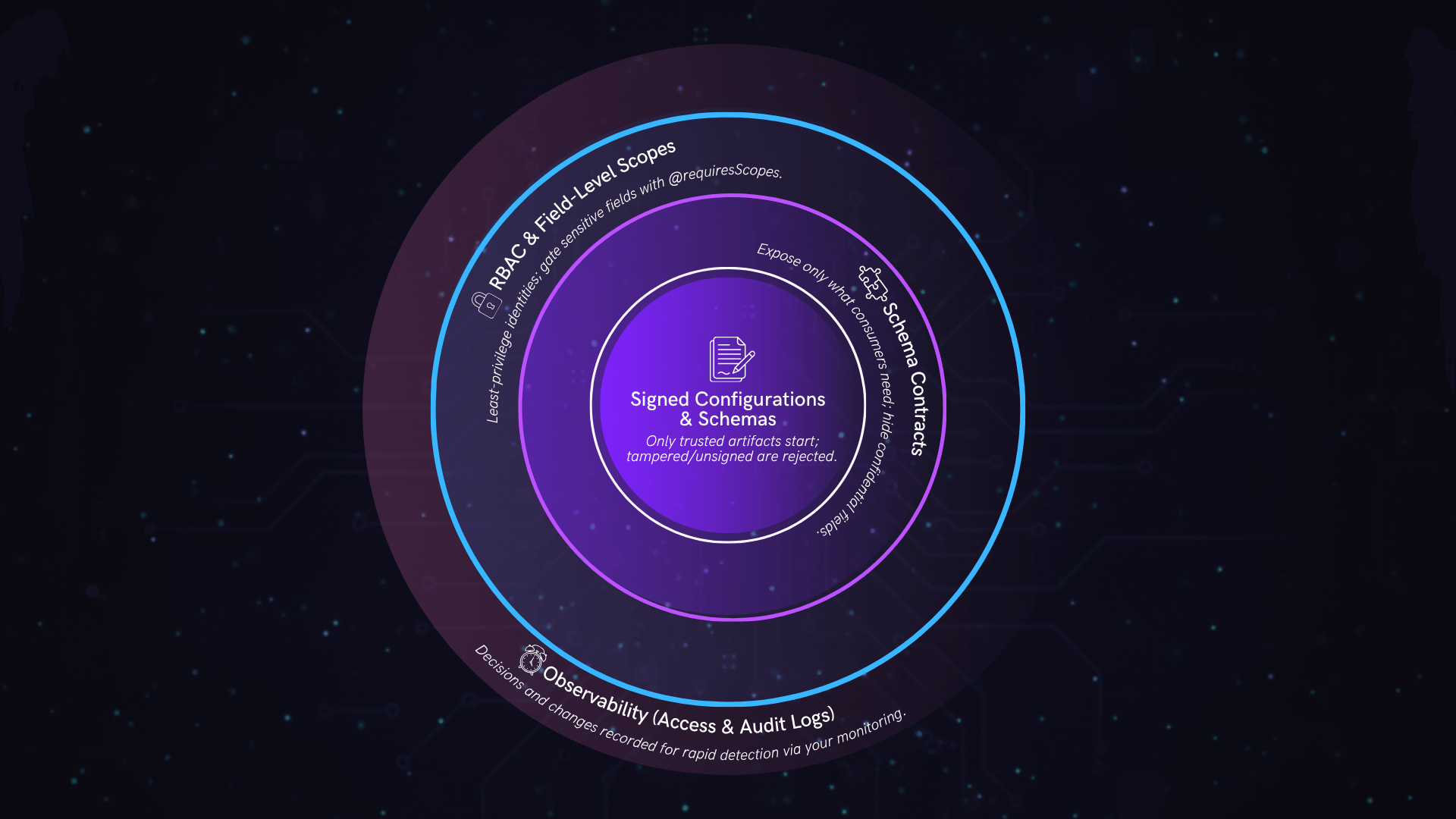
- Signed Configurations and Schemas rejecting unsigned or altered files at startup.
- Scoped Access and RBAC limiting token permissions.
- Persisted Operations that block injected or unapproved queries.
- Audit Logs : capturing every schema, config, and key change.
Across all three incidents, the pattern was the same. Each began when untrusted logic entered a trusted path, escalated because the system executed it without verification, and grew worse through over-scoped access or unsigned artifacts.
Each failure lines up with a missing boundary — all of which federation now enforces for you.
Prompt injection is not an edge case but a predictable outcome of systems that execute model output without policy.
The fix isn't more filters, but rather, stronger boundaries:
- Govern execution with allowlists.
- Govern reach with scoped identities.
- Govern trust with signed artifacts.
Teams that implement these controls move from reactive patching to proactive containment.
They no longer rely on the model’s good behavior — they rely on verifiable controls.
Recent incidents exposed gaps in execution control, identity scope, and artifact trust.
These are the controls teams can apply now to contain similar risks:
| Risk | Control | Cosmo Feature | Effect In Practice |
|---|---|---|---|
| Injected or unvetted instructions executing at runtime | Enforce a persisted operation allowlist | block_non_persisted_operations | Only pre-approved queries run; injected logic fails validation |
| AI clients retrieving or mutating sensitive data | Apply role-based access control and field-level scopes | @requiresScopes directives, API key RBAC | AI identities can reach only approved operations and fields |
| Prompt-injected queries discovering hidden fields | Publish a schema contract for AI consumers | Contracted schema via Cosmo Studio or CLI | The AI never sees or queries fields outside its contract |
| Compromised or tampered deployments | Require cryptographic signing of schemas and configs | graph.sign_key (HMAC) | Unsigned or altered builds are rejected automatically |
| Silent misuse or failed policy checks | Enable audit and access logging | access_logs, Studio audit trail | Configuration changes are recorded in Studio’s audit log; failed or rejected requests appear in router access logs when enabled |
Each control maps directly to a real failure pattern from the incidents above. Models still misbehave, but now the system won’t.
You can’t tune your way out of prompt injection, but you contain it with runtime boundaries.
Here’s how to roll out controls in order of impact:
- Action: Enable
block_non_persisted_operations: true. - Outcome: Only approved GraphQL operations run; injected or ad hoc queries are rejected.
Action: Create a schema contract that exposes only the fields your AI clients need.
Tag sensitive fields in your schema:
Create the contract via CLI:
Outcome: Your AI clients get a clean, focused schema without access to sensitive data.
- Action: Schema contracts are automatically published when created via the CLI command above. The contract creates a filtered version of your schema that excludes tagged fields.
- Outcome: Confidential or internal fields are excluded from the AI's graph through the contract schema.
- Action: Sign router configurations and schemas with an HMAC key.
- Outcome: Tampered or unsigned artifacts are blocked at startup.
- Action: Enable access logs and include failed requests.
- Outcome: Configuration changes and rejected requests are traceable. (Audit logs are recorded automatically in Cosmo Studio.)
By following this sequence, teams move from reactive response to controlled execution.
Each layer builds on the last: first decide what runs, then who can run it, then what’s visible, and finally what’s trusted.
This approach doesn’t rely on predicting the next exploit. It governs every outcome.
The past year’s incidents didn’t come from clever attackers or flawed models.
They came from systems that trusted model outputs as if they were human decisions without verifying what, who, or how.
You can’t eliminate prompt injection, but you can contain its impact.
Resilient teams do this by governing what executes, what’s reachable, and what’s trusted.
Even if the model goes off script, these controls hold the line.
Cosmo was built for this shift, not just to connect services but to enforce runtime rules that protect and isolate AI-driven systems.
Federation isn’t just for stitching schemas; it’s how you enforce runtime rules.
By combining trusted execution, scoped access, and verified configuration, teams can turn prompt injection from a breach into a blocked request.
The goal isn’t perfection.
It’s predictability.
You decide what the AI can do, what it can see, and what it can ship.
Everything else is denied, logged, and contained.
That’s practical AI governance.
For a broader look at responsible AI system design, see Rethinking API Access in the Age of AI Agents by Cameron Sechrist, which introduces harm limiting as a framework for guiding model behavior beyond access control.
Content Manager
Brendan Bondurant is the Content Manager at WunderGraph, owning technical content across GraphQL Federation, API tooling, and developer experience. He partners with leadership on product and company messaging and works cross functionally to align positioning, terminology, and content strategy across channels.

Data Architect: GTM & MI
Tanya brings cross-functional background in Data & MI, CMO, and BD director roles across SaaS/IaaS, data centers, and custom development in AMER, EMEA and APAC. Her work blends market intelligence, CRO and pragmatic LLM tooling teams actually adopts and analytics that move revenue.


