
API Management does too little, Backend as a Service does too much


State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
Full Lifecycle API Management, as the name implies takes care of all things APIs. Backend as a Service on the other hand completely abstracts away the need to write a backend at all.
These two seem fundamentally different, but maybe there's a closer relationship between the two as we might think. In the end, both approaches help us build applications, so there must be some overlap.
This post will look at both technologies and analyze them in terms of overlap in functionality, the use cases they are designed for, pros and cons. The goal is to give you a good understanding of the two, and the tradeoffs they make.
What we'll see is that strongly opinionated tools anad frameworks give you more out-of-the box functionality, while less opinionated ones are easier to integrate with other systems.
Finally, I'd like to conclude with a better approach, a cross-over between backend as a service and API Management. I will introduce a new concept that is both open to extension and integration while delivering more out-of-the-box functionality than strongly opinionated frameworks.
If you search for the term using a popular search engine, you might end up on the description from axway . It categorizes the lifecycle of APIs into 10 Stages:
- Building
- Testing
- Publishing
- Securing
- Managing
- Onboarding
- Analyzing
- Promoting
- Monetizing
- Retirement
Let's break these down a bit. First, you make a plan to solve a problem using an API. You then start building the API, test it, and finally publish it in some way. You have to make sure the API is properly secured. APIs need maintenance and evolve over time, this process has to be managed.
Once the API is published, you want developers to be able to use it, so you have to help them with the onboarding. With the first users using your APIs, you probably want to understand how they use your API product, so you add analytics to your API to get access to this data.
Your API is now ready for growing the user base, it's time to promote the API, for example through the use of an API Developer Portal or an API Marketplace.
APIs can be published internally as well as externally, e.g. to partners or a wider public audience. Depending on the business model, you might want to monetize the usage of your API, allowing you to make money from offering your service as an API product.
Eventually, the life cycle of the API ends with the retirement of the API.
I've been involved in building API Management tools over the last couple of years, so I'm very well aware of the lifecycle of APIs and how API Management tools support developers throughout the whole journey.
Full Lifecycle API Management (FLAPIM) tools are a massive step forward to promote the concept of APIs.
Full lifecycle API Management has a Developer Experience gap.
At the same time, I believe that there's a huge gap in FLAPIM solutions, resulting in a poor Developer Experience, billions of wasted resources, and a huge opportunity for improvement.
This problem becomes obvious when looking at the concept of "Backend as a Service" (BaaS), which has its own flaws.
To describe BaaS, let's have a quick look at the core aspects of a web or mobile application.
At the very beginning, you have to identify the Actor of the application. The Actor of an application could be a real person, or a service, anonymous or with a specific identity. We call this step authentication.
Once we know the Actor, we need to understand if they are allowed to do a specific activity. This is called authorization.
Obviously, an Actor without any Actions available makes no sense. So, our application also needs a State Machine. The State Machine could have persistence or be ephemeral, it could live in the client or the server, or both, and it could be monolithic or distributed.
Most applications rely on multiple distributed state machines with persistence on the server-side.
Aside from state machines, applications could also allow users to upload and download files, which are simply binary blobs of data, not as structured as the data used by state machines. These could be images, pdfs, etc.
That's it for the core ingredients of an application. In short, authentication, authorization, distributed state machines and file management.
So what's Baas then?
Some people realized that building distributed state machines with persistence is actually quite complex. As we've learned in the previous chapter on FLAPIM, there are a lot of steps involved in building a "state machine" and exposing it as an API.
Backend as a Service takes the core ingredients of building an app and offers them as an easy-to-use service. Define your data model, configure authentication and some roles and your "API" is essentially done. You can now use the SDK of the BaaS solution to build your frontend application.
BaaS simplifies the steps of getting from idea to state machine, wrapped and exposed as an easy to consume API.
Let's put ourselves in the shoes of an API consumer, the main user of the API, the builder, the one who takes one or more APIs and builds something on top of them.
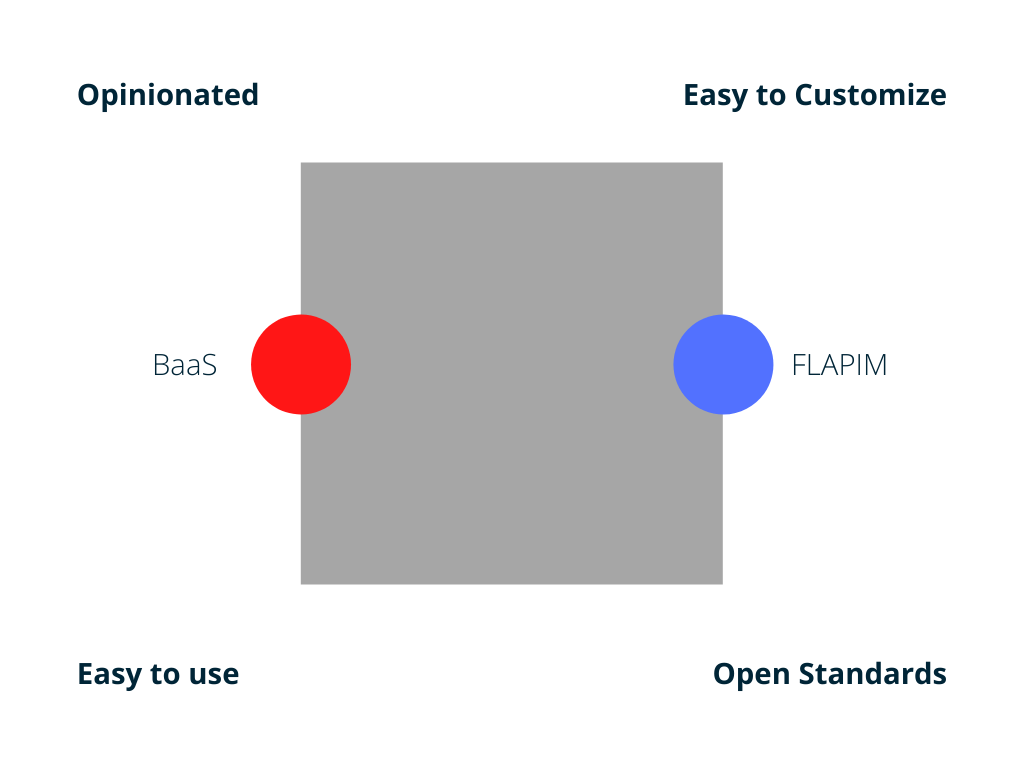
From their point of view, we can categorize both BaaS and FLAPIM into four categories.
How opinionated is the framework? Is it easy to customize? Does it use open standards? Is it easy to use?
BaaS tools are usually well integrated systems. They are very opinionated in that they make decisions for you. For example, they define the data storage technology. Making these decisions for you has two effects. For one, it makes BaaS tools very easy to use because everything fits together nicely. On the other hand, these decisions make it harder for you to customize the system. Additionally, BaaS frameworks don't always use open standards, locking you into an ecosystem.
Good examples for this are Google Firebase or AWS Amplify. They give you a lot of out of the box functionality, but you have to buy into their ecosystem of tools, making you reliant on their them, also known as vendor lock-in.
Full Lifecycle API Management solutions on the other hand are general purpose solutions. Many of them are open source and use open standards like OpenID Connect for authentication and OAuth2 for authorization. Being this open makes them very easy to extend and integrate with other components. On the other hand, they are not as integrated as BaaS solutions, making them a lot harder to use.
Let's look at an example to make the distinction clear. Imagine, we're building a chat application. Users can log in, join a chat room and write and read messages.
With a BaaS, you have an authentication API out of the box. The SDK allows you to make a single function call to log a user into the application. On the "backend" side of things, you define your data model, the chat room, and a message type with a relation between the two. This automatically gives you an API which can be used by the SDK to join a chat room and write or receive messages through a realtime API. The result is achieved very easily at the expense of locking your data into a proprietary system.
Going the Full Lifecycle API Management route, we start differently. First, we have to choose an identity provider, e.g. Auth0 or Keykloak. That's already a big cost, because you have to learn and understand what OpenID Connect is. Once you have set up your identity provider, you can start building your backend solution. You have to make a lot of decisions. What database should you use? How do you define the data model? What API style should you use? What language and framework to implement the backend? Once the API is implemented and deployed, you have to integrate it with the authentication solution, usually through the use of an API gateway from your FLAPIM solution of choice.
At this point, we have a ready to use API, but there's still more work to be done. You now have to find a library for your client-side authentication implementation. Once that's done, you can authenticate the user. Finally, add an API client to interact with the API and connect it to the user interface.
Going the "custom API" route gives you full flexibility of any aspect of your application. You are free to choose an identity provider. You could self-host a solution like Keykloak to own the profile data of your users. On the backend side of things, you can optimize specifically for your use case and, again, own your data 100% if you want. At the same time, building a custom API adds a lot of complexity and requires a lot more skills.
Looking at this example, we can make the following observations. If you use an opinionated solution, you get an easy-to-use tool that gets you to your goal quickly. Being opinionated is responsible for both the productivity and locking you into the system.
A custom solution on the other hand requires a lot more experience and resources. On the upside, you're not locking yourself into an ecosystem of a specific vendor.
Another observation I've made is that full lifecycle api management, while the name suggests it, does almost nothing to support you in the process of building your application.
We've talked about the lifecycle and all the things that FLAPIM does, on the other hand, there's so much work left that we have to question the usefulness of API management.
This is, of course, a provoking thought. API management takes away a lot of complexity, especially when your organization is growing. However, I still see a huge gap between Backend as a Service and FLAPIM.
Looking at the current situation, let's define an optimal solution.
Ideally, we want a solution that gives us the ease of use of a Backend as a Service that is not just easy to customize but also relies on open standards.
So far, we haven't seen a solution like this, so we've built one. It's going to be open source soon. You can sign up for the waitlist if you'd like to get notified once it's out .
OK, how do we built a solution that actually helps the developer to quickly build applications without locking them into a specific stack?
To get to the solution, we have to break down the core aspects of an application:
- authentication
- authorization
- APIs
- file storage
With these 4 ingredients, we're able to build almost any application. What's missing is a way of combining them in a structured way, a way of composing the individual parts to form a stack. Luckily, there's a concept that enables composition!
If you don't want to force someone into a specific implementation, you should introduce an abstraction so that your user can select their implementation of choice, as they only rely on the abstraction.
We've talked about it all the time, I'm talking about the API, the application programming interface.
What's left is that we have to choose good interfaces to implement our application, and then figure out a way of combining the interfaces into a complete stack.
Choosing these interfaces, all we have to do is select the most widely adopted specifications.
- authentication: OpenID Connect
- authorization: Oauth2
- APIs: OpenAPI, GraphQL, gRPC, WSDL
- file storage: S3
Wile the community is pretty clear on how to do authentication, authorization and managing files, there's an issue with API Specifications and styles, there are many of them and if we only supported one of them, extensibility and openness for extension would be at risk.
However, dealing with multiple API styles in the same application is going to be problematic. If clients have to deal with multiple API styles and various backends at the same time, their implementation will be quite complex.
I've realized this is going to be the core of the problem of API integration a couple of years ago and started exploring how to solve it. What I ended up doing is to build an API engine that speaks a single language while being able to talk to multiple differing interfaces behind the scenes.
The solution is a general purpose API execution engine, with configurable data sources, exposing a GraphQL API on top of all your services. It's open source , widely adopted and in production for multiple years now.
Here's a high level overview of the engine. In a nutshell, it combines multiple (micro) services of different protocols into a GraphQL API. This API can then be consumed by different clients.
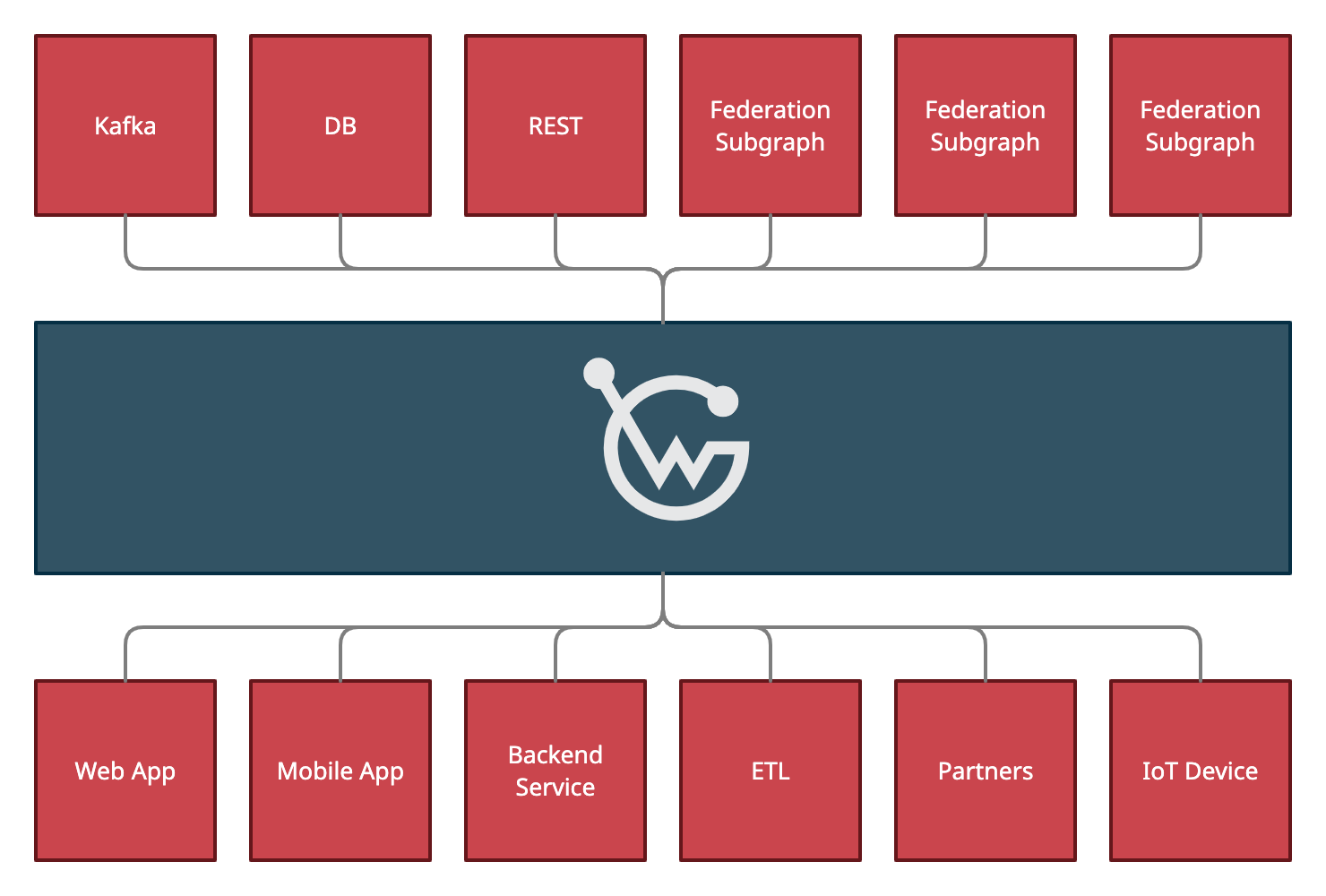
The resulting GraphQL API doesn't really exist though, as it's simply an abstraction, which is why I call it the "virtual graph" or "API-Mesh" as we're doing a mash up of all the APIs.
With this, we've got our final ingredient, an API abstraction layer for all our APIs.
Coming back to our ideal stack we now have all the abstractions complete.
- authentication: OpenID Connect
- authorization: OAuth2
- APIs: API-Mesh combining OpenAPI, GraphQL and more
- file storage: S3
I never intended to build a Backend as a Service solution. That's because I always felt them cumbersome to use and was afraid of vendor lock-in.
What I mean by cumbersome is best described by looking at code examples, here's one from Supabase:
In the first example, the developer has to know that "rooms" exists. When inserting data, you also have to know what fields can be inserted and what are the allowed values. That's because the "sdk" (await supabase) doesn't know anything about your data model.
In the second example, they've invented their own "Query Language" which looks almost like GraphQL. Again, you have to know what fields are available.
This might work for a small project with 2 developers but doesn't scale beyond a certain point.
Here's another example, Firebase this time, same problem. The developer must know that "users" exists and what fields and field types are available.
This examples shows how you can read data using Firebase. It's interesting that they leak "snapshots" to the API consumer.
Here's another example using the Firebase Realtime Database.
You have to build a "ref" using "users/" + userId and then, again, guess fields and types. Well, it's actually just javascript so there's not even type information.
To close off the rant, let's also have a quick look at appwrite.
Appwrite lets you create a document in a collection. It's the same problem as with all the others, "data" is of type JSON Object.
To sum it up, Backend as a Service is a great idea, but for me it completely fails to deliver on the Developer Experience.
I also don't like that we're binding user interfaces directly to "database interactions". There seems to be a lack of abstraction, using an API in the middle, an API that's designed around use cases, not database tables.
While working with the "virtual Graph", I've came to a conclusion that completely changed my life. It solves the problem with lack of type safety in Backend as a Service tools entirely. As I said before, I didn't want to build a Backend as a Service kind-of-solution but still ended up here.
Let's recap quickly what the "virtual Graph" is. It's an API abstraction on top of all your services and APIs. It introspects all the services specifications, converts them into a GraphQL Schema, and generates an API execution engine that can execute this schema.
As it's a general purpose solution and open for extension, any service, api, database, etc... can be connected to this virtual Graph.
The virtual Graph has one important feature, it's typed! It's a GraphQL API in the end, so it has a schema, and you can write GraphQL Operations to interact with the API.
That said, this resulting API has a problem, it's barely usable. Imagine, you combine 10 microservices with 3 databases and merge all the APIs together. This doesn't just sound messy, it is messy. That's not an API you'd want to expose.
It was then that I've had this life changing but simple thought. Life changing, because I cannot stop working on this, simple, because it's so obvious.
The GraphQL Schema is not the API, the Operations define the API
This thought probably goes against everything you know about GraphQL. The GraphQL Schema defines the API, doesn't it?
Using the GraphQL Schema to define the API is one way of doing it, but using the Operations instead to define the API is way more powerful. Let me explain the concept in five steps.
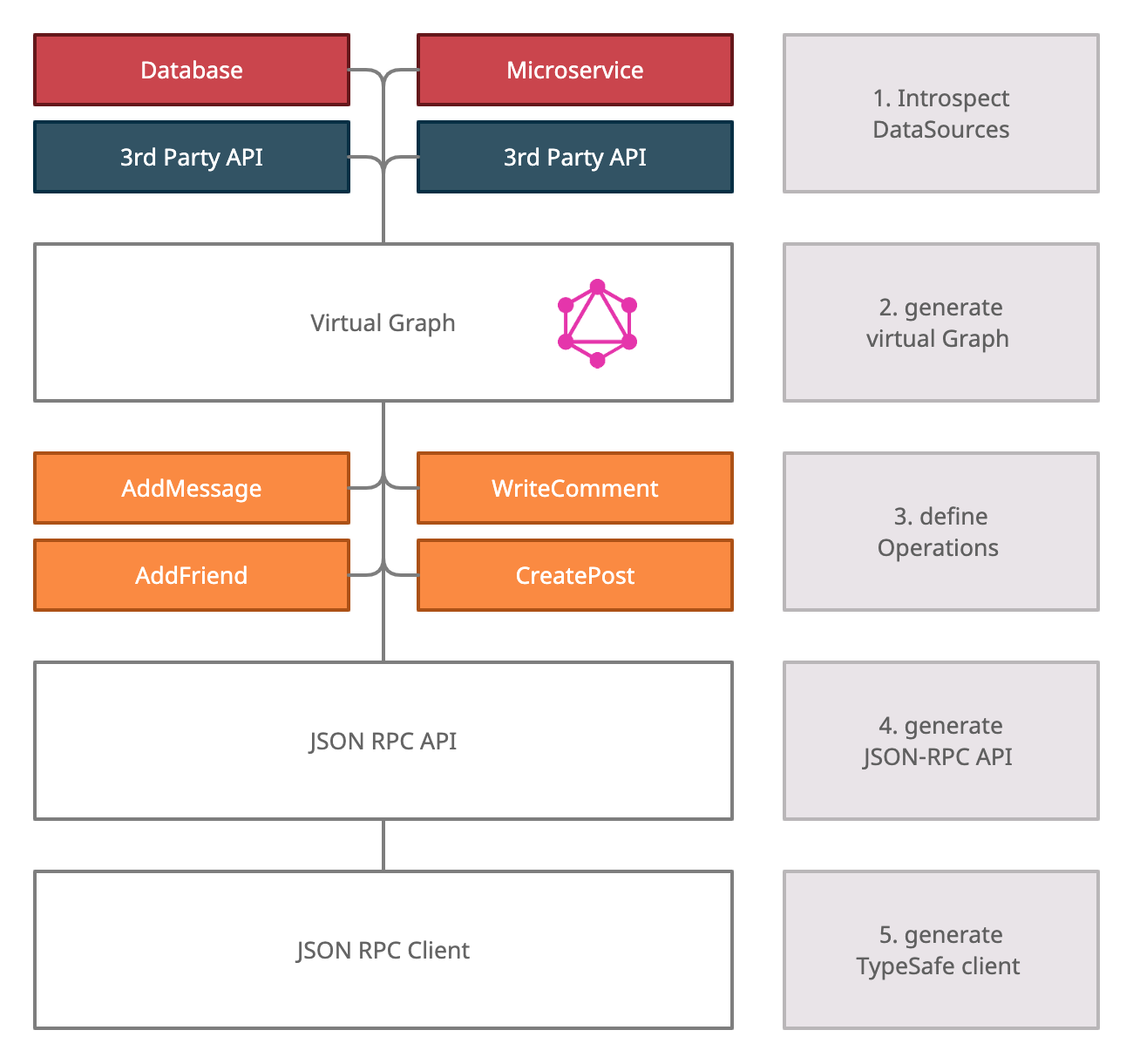
In the first step, we introspect all DataSources. To simplify this, we've created a TypeScript SDK. Here's an example of introspecting a PostgreSQL Database.
This happens automatically once you run wunderctl up. WunderGraph converts all DataSources into a GraphQL Schema and generates Resolvers, functions to resolve / execute the GraphQL Schema.
Once the virtual Graph is generated, you can define your Operations:
This Operations allows the end user of the API to create a message. Through the use of the @fromClaim Directives, we're able to inject Claims from the user into the Operation. This is enabled because WunderGraph integrates with OpenID Connect.
Once the Operations are defined, WunderGraph generates a JSON-RPC API. During development, wunderctl up takes care of all of this.
wunderctl is not just a dev tool to introspect your services using the SDK and generating the JSON-RPC API, it can also generate fully TypeSafe clients.
This fifth step is where the magic happens. Each of the Operations is defined by writing a GraphQL Operation. GraphQL Operations don't just return JSON, but the input variables can also be expressed as a JSON Object.
This means two things. First, we can extract a JSON-Schema for all the inputs and responses for each Operation. Second, this JSON-Schema can be used to generate 100% TypeSafe clients.
There's a whole section in the docs on the generated clients if you want to read more.
To sum it up, by introspecting all the services, merging them into a common virtual Graph, then defining the Operations via GraphQL Operations, and finally generating the API and the Client, we achieve 100% TypeSafety.
Combined with our Open Source Approach, this is the BaaS we've always wanted.
Reminder, if you'd like to get notified once we release our Open Source Framework, sign up for the early access list .
We're currently looking into building a group of "WunderGraph Insiders" who get some special benefits.
- private discord channel invite where we share ideas and give you exclusive insights
- eary access to the open source version before everyone else
- engage in a panel of enthusiasts and shape the roadmap
We've gone quite far into the "data layer", almost forgetting about the rest of the stack. Let's now put it all the pieces together to build our "abstract" Backend as a Service solution.
As described in the data chapter, WunderGraph supports OpenID Connect for authentication. All you have to do is use the TypeScript SDK and point it to your authentication provider of choice.
Here's an example config.
For more info, please check the docs on authentication.
We've already touched on this as well. Authorization is supported by WunderGraph by injecting Claims into the Operations. This way, you're able to use a userID or EMail and use it as a parameter to a service or database.
We've described the solution extensively above.
The missing piece to round off our BaaS is managing files. As we're relying on the S3 standard, the configuration is straight forward using our TypeScript SDK.
More info on how to configure S3 in the docs.
With that, we've got our complete Backend as a Service solution. It's 100% TypeSafe on both backend as well as frontend. You can plug in any API you want, REST, GraphQL, PostgreSQL, MySQL, Apollo Federation, etc... If you want to add an additional DataSource, you're able to contribute it to the project yourself.
As WunderGraph is only an "abstract" framework and not relying on specific implementations, we also call ourselves an "anti vendor lock-in" solution.
For Data Storage, you can use any database hosting provider you like. For Authentication, you are free to choose between different vendors. The same goes for File Storage, as there's a wide array of S3 implementations.
Finally, for all interface implementations across Data Storage, Authentication and File Storage, there exist Open Source solutions that can be hosted on premises. You can run your own PostgreSQL DB (Data Storage), combine it with Keykloak (OIDC) and run Minio (S3) in your own environment.
Thanks to the generated TypeSafe clients, you get a better Developer Experience than Firebase & Co., while staying 100% in control of your data.
Got curious? Have a look at our Quickstart and try it out in a minute on your local machine, it's free.
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


