
WunderBase – Serverless GraphQL DB using SQLite, Firecracker & Prisma


Archive Notice
This article is archived and no longer maintained. The concepts and implementation details may not reflect how WunderGraph works today. For current product information, see WunderGraph Cosmo
Today we're happy to announce the open source release of WunderBase, a Serverless Database with a GraphQL API on top of SQLite, Firecracker/Fly machines, and Prisma. It's embarrassingly simple, but powerful, as the codebase is less than 400 lines of Go.
WunderBase is built on top of Fly machines, which is a REST API that allows you to run virtual machines in seconds. What's special about machines is that they can sleep when an application exits with a zero exit code.
When you send a request to WunderBase, the virtual machine wakes up in about 300-500ms and executes the request. Ten seconds (configurable) after the last request was processed, we send the machine to sleep again. This means that you really only pay for storage and the CPU time you really use, hence the name "Serverless Database".
If you'd like to jump right into the code and try WunderBase out for yourself, you can find the source code on GitHub .
If you're less of a reader, you can also watch the video below to see WunderBase in action.
We're in the works of building WunderGraph Cloud, applying the principles of Vercel to Backend/API development. We take the most important backend primitives like Authentication & Authorization, Database, Queue, PubSub, Key-Value Store, Cache, etc. and make them available as a single, unified SDK.
Git push and 30 seconds later, you've got a fully functional Serverless backend without touching any infrastructure. Make some code changes, open a PR, and get a preview environment with your changes.
For this to work, we need a fast and inexpensive way to create and destroy databases. But as you'll see, there are many other use cases for WunderBase than just preview environments.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
Here's an overview of how WunderBase works:
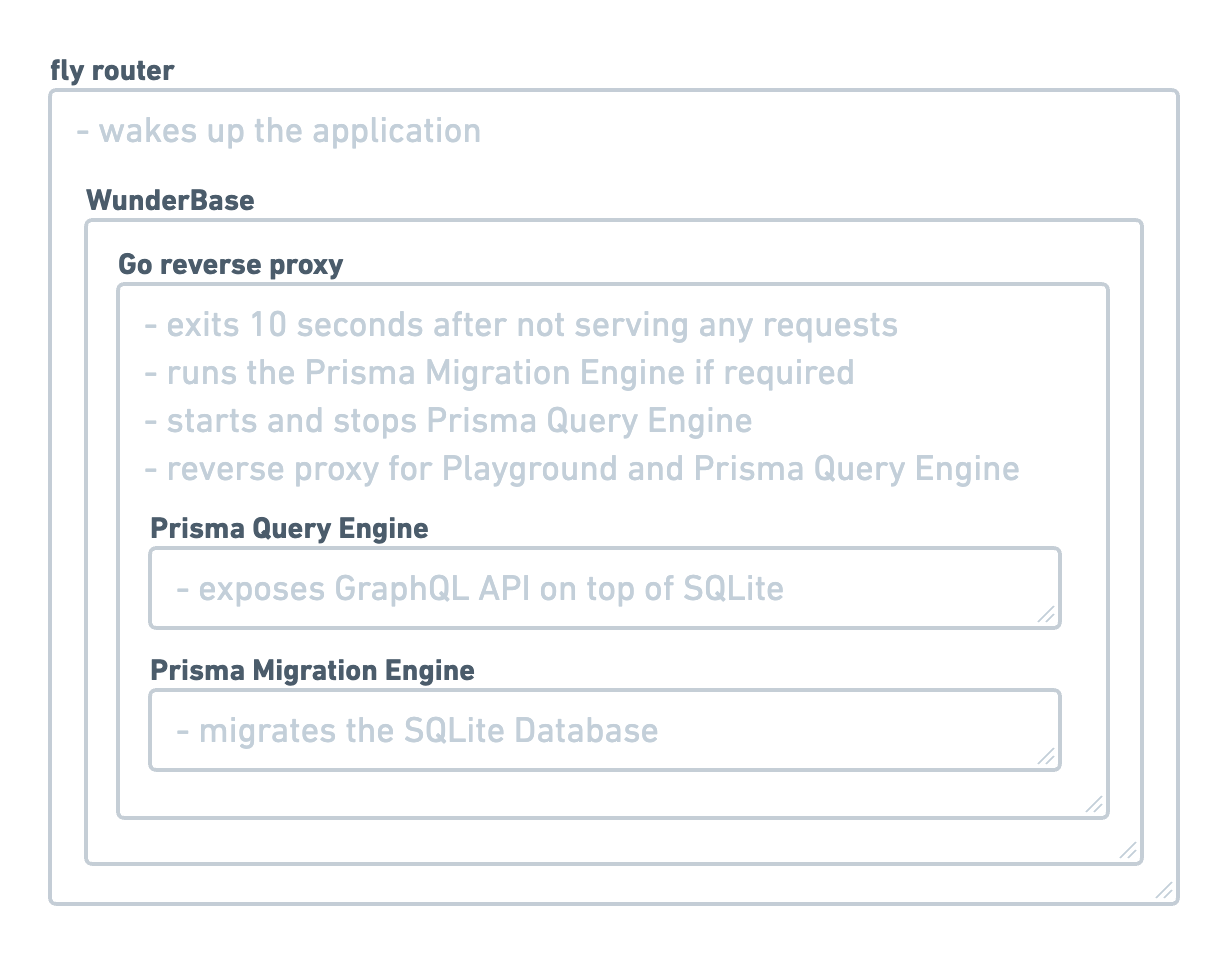
- You deploy WunderBase to a Fly machine with a volume attached
- The Fly machine boots up and starts WunderBase
- We use the the
prisma.schemafile to migrate the database using the Prisma Migration Engine - Once the migration is done, we create a lock file to prevent future migrations if the
prisma.schemafile didn't change - Finally, we start the Prisma Query Engine to serve the GraphQL API
- Ten seconds (configurable) after the last request was processed, we exit WunderBase with a zero exit code to indicate to fly that this Machine should go to sleep
Request flow:
- You send a request to WunderBase
- The Fly machine wakes up in about 300-500ms
- The fly proxy forwards the request to WunderBase
- WunderBase sanitizes the request and proxies it to the Prisma Query Engine
- The Prisma Query Engine executes the request and returns the result
- WunderBase sends the result back to the client
- Again, after ten seconds of inactivity, we shut down the Machine
When using AWS Lambda, you have to follow certain rules to make your application compatible with the environment. E.g. when you're using Golang, you have to export a Handler function that takes a context.Context and the name of the event. Also, you don't really have much control over the environment your application runs in. At some point, the Lambda runtime will shut down your application.
With Fly machines, we can operate at a much lower level. We create a Docker container that listens on a specific port. We tell fly to run this container and send all requests to this port. If we think the Machine should sleep, we exit the container with a zero exit code. Fly will keep our volume around and start the container again when we send a request.
A lot of applications are written in a Serverful single-tenant way would usually be quite expensive to run as a multi-tenant service. With Fly machines, we can run these applications in a very cost-efficient way. However, there's a catch. We have to optimize the application for fast startup and shutdown. I know that fly is working on allowing machines to "sleep" and "resume", just like closing and re-opening a laptop. This would allow us to run applications that are not optimized for fast startup and shutdown. In the meantime, we've built WunderBase in a way to optimize for fast startup and shutdown times.
When a request is waiting to be served, we need to make sure that the Machine starts up as fast as possible. At the same time, we always want to keep the database schema in sync with the prisma.schema file. If we ran a migration every time the Machine starts up, we would have to wait for the migration to finish before we can serve the request. That's not ideal, so we've optimized this path.
When the Machine starts up, we hash the prisma.schema file and check if there's a lock file with the same hash. If there's a lock file, we compare the content of the lock file with the hash of the prisma.schema file. If they are the same, we know that the migration for this schema has already been executed. If there's no lock file, we run a migration and create a lock file with the hash of the prisma.schema file.
We store the lock file in the volume, so it's available even if the Machine was sleeping.
Next, we needed to make sure that the Prisma Query Engine shuts down properly. We start the Prisma Query Engine as a separate process. Before we kill the main process, we send a SIGTERM signal to the Prisma Query Engine. If we would immediately kill the main process, the sub-process would keep the Machine from shutting down for a few more seconds. Instead, we're using a sync.WaitGroup to wait for the Prisma Query Engine to shut down before we exit the main process. This way, we've reduced the shutdown time from 5-10 seconds to 1-2 seconds.
If we didn't do this, you'd have to wait up to 10 seconds when sending a request to WunderBase while it's shutting down.
How does WunderBase compare to other Serverless Databases like DynamoDB, CockroachDB, MongoDB, FaunaDB, Planetscale or Neon?
We can have long debates about what Serverless really is or if the term actually makes sense. After all, there are still servers involved. To me, Serverless means that you don't have to worry about the infrastructure and that you only pay for what you really use.
For a long time, Serverless was mostly about functions. You write a function, deploy it, and you're done. Someone else takes care of the infrastructure and you only pay per request.
Then came a new wave of Serverless offerings that give you a "Serverless Database". You write a schema, deploy it, and you're done. But are these really Serverless?
From a user perspective, yes. From a technical perspective, no. Most databases still are "Serverful" in the sense that the database server is always running.
Some solutions, like Neon, try to solve this problem by separating the compute and storage layer. Others, like CockroachDB or Mongo put a proxy in front of the database so that you can "imitate" a Serverless Database.
In contrast, the storage layer of WunderBase is always "sleeping", because it's just a file. SQLite is probably the only real Serverless database because it's just a file. The Serverful part of WunderBase is the proxy that runs the Prisma Query Engine and translates between GraphQL and SQL. But as we've discussed earlier, we can send this proxy to sleep and wake it up again when we need it.
Another important aspect of WunderBase is that it's actually quite simple and very transparent what's going on. We've got a proxy that translates between GraphQL and SQL, and we have a SQLite database / file on a volume.
I've told one of my Co-Founders that I'm a bit embarrassed to release WunderBase because it's so simple and just a few hundred lines of code. He answered that it's not embarrassing at all, because it's actually quite impressive that we've managed to build something that's so simple and yet so powerful. And he's right! Sometimes you combine the right ingredients in the right way and achieve something that took others years to build. It took me just a few hours to build WunderBase. The most time-consuming part was to write proper tests and this blog post.
You might be thinking that WunderBase is just a toy project. We're definitely not going to compete with the big players in the Serverless Database space. Instead, we're looking at serving use cases that others are unable to serve.
I'll give you a few examples:
- It takes seconds to create a new WunderBase instance. You can use it for a quick prototype or to test something out.
- For each branch you deploy, you can have a separate WunderBase instance that's isolated from the main branch/database.
- A lot of applications don't ever store more than a few gigabytes of data and have very little traffic. WunderBase is perfect for these use cases.
One use case that excites me the most is that you can "shard" at the database layer. What this means is that you can have a single database model that's shared across multiple databases. You can have one database per user, tenant, or any other key and route traffic to the correct database based on the user's (tenant's) ID. If you have a customer with a lot of data, you can easily put them on a separate database. If each customer has their own database, you can do point in time recovery for each customer individually.
Another interesting use case is OLAP. Let's say we'd like to analyze terabytes of data in seconds. We can shard the data across multiple databases and run a query on each database in parallel. We can then aggregate the results and return them to the user. While we're not serving any requests, we can shut down the databases. This way, we're only really paying for the storage and compute that we're using. This could be an Open Source alternative to BigQuery.
I've done some benchmarking and was able to achieve 2k write requests per second and 10k read requests per second. There's a benchmark script in the WunderBase repository that you can use to run your own benchmarks. Make sure to set the rate limit environment variables properly to not get rate-limited. During my testing I've realized that 2k/10k is the maximum that I can achieve before getting Timeout errors, so I've added some rate limiting to the proxy to keep everything stable.
There are multiple ways to scale WunderBase. We can add read replicas to scale reads. There's tooling to replicate SQLite databases, both locally or even remotely. So we could have a master database and read replicas in different regions.
Another way to scale WunderBase is to have multiple master databases. With this approach, we can scale writes based on a key like the user ID or tenant ID.
If you've got users all over the world, you can combine both approaches to optimize for latency.
Another question you might ask is if you're able to migrate from SQLite to e.g. PostgreSQL or MySQL. The answer is yes and it's actually quite easy. As we're using Prisma, we can just change the provider in the datasource block in the prisma.schema file. If we're using the same Schema, Prisma will give us the same GraphQL API, even if we're using a different database.
So it's possible to switch from SQLite to MySQL, PostgreSQL, SQLServer or even Planetscale.
Backups can be implemented e.g. by leveraging LiteStream, a tool that streams the changes from a SQLite database to S3.
There's one caveat that you should be aware of. The GraphQL API that WunderBase (Prisma Query Engine) exposes is not intended to be publicly exposed. You should always put a GraphQL API Gateway like WunderGraph in front of it. It's perfectly fine to use GraphQL as the ORM layer, but this API is not intended to be consumed by clients in the browser directly.
Additionally, Prisma Query Engine is only exposing a subset of GraphQL, e.g. you cannot use variable definitions. We've done some extra steps in WunderGraph to make it compatible with GraphQL, like writing a "variable definition inliner" to automatically inline variable definitions and make the GraphQL Operation compatible with the Prisma Engine. I'll follow up with a blog post about this topic as it was actually quite interesting to reverse engineer the Prisma Query Engine and make all of this work together.
All of this wouldn't have been possible without the amazing work that the Prisma team has done. Besides the 400 lines of glue code that I've written, the rest is just Prisma.
I also know that this is not the intended use case of Prisma. Nikolas Burk keeps reminding me that Prisma is an ORM and the GraphQL layer of the Prisma Query Engine is an internal detail. Prisma generates a client library on top of this Engine which uses GraphQL internally.
I personally think that it's much more powerful to expose the GraphQL API directly. This way, I'm able to join multiple APIs together easily and talk to all my services with a single language.
So, thank you and sorry for abusing your product! Open Source is awesome! =)
I'm very excited about the future of Firecracker-based applications. I'm pretty sure that this paradigm will allow us to build or re-build a lot of applications in a more efficient way, like Serverless Databases, Serverless Caches, Serverless Queues, Serverless Search Engines, etc.
Our goal for WunderGraph is to create a TypeScript Framework that allows you to build Serverless Applications in a very simple way. From databases to file storage, queues, pub/sub, key-value, and caching. We want to provide a unified SDK that allows you to focus on the code, not on the infrastructure.
Today, we're starting with a Database, but there's alot more to come.
Make sure to follow us on twitter or linkedin to stay up to date on our progress.
Finally, I'd love to hear what you'd build with WunderBase. I've got a few ideas (see above), but I'm sure that there are many more use cases that I haven't thought of yet.
In case you've missed it above, here's the link to the source code of WunderBase on GitHub . Give it a star if you like the project and go tinkering with it. =)
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


