
The complete GraphQL Security Guide: Fixing the 13 most common GraphQL Vulnerabilities to make your API production ready


Editor's Note: While this post provides great insights into securing GraphQL APIs and addressing vulnerabilities, we'd like to introduce you to WunderGraph Cosmo , our complete solution for GraphQL Federation and API management. Cosmo goes beyond securing individual endpoints; it offers a comprehensive platform for managing and federating APIs with built-in security features, performance optimizations, and scalable architecture. Whether you're mitigating common vulnerabilities or building secure and performant APIs, explore how Cosmo can transform your API workflows and deliver peace of mind in production environments.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
It's 2021, GraphQL is on its rise to become a big player in the API Ecosystem . That's perfect timing to talk about how to make your GraphQL APIs secure and ready for production.
So here's my thesis: GraphQL is inherently insecure. I'll prove this throughout the article and propose solutions. One of the solutions will require some radical change in the way we're thinking about GraphQL, but it will come with a lot of benefits that go way beyond just security.
If you pick a random GraphQL framework and run it with default settings in production, disaster is waiting to happen.
Why? Why is GraphQL so much more vulnerable than e.g. REST? Let's compare a URL against a GraphQL Operation. According to Wikipedia, the concept of the URL was first published in 1994, that's 27 years ago. If we search the same source for the birth of GraphQL, we can see, it's Sep 2014, around 7 years old.
This gives parsing URLs an advantage of 20 years over parsing GraphQL Operations. Quite the headstart!
Next, let's have a look at the antlr grammar for both.
The grammar for parsing a URL is 86 lines. The grammar for parsing a GraphQL document is 325 lines.
So, it's fair to say that the GraphQL language is around 4 times more complex than the one defining a URL. If we factor in both variables, it's obvious that there must be a lot more experience and expertise in parsing URLs than parsing GraphQL operations.
But why is this even a problem? Recently, a friend of mine analyzed some popular libraries to see how fast they are in parsing GraphQL queries. It made me happy to see that my own library was performing quite well . At the same time, I was surprised that some libraries didn't accept the test Operations while other were able to parse them.
What does this mean for us? The person who performed the benchmarks hand-picked a number of GraphQL libraries and ran a few benchmarks. This was enough to find some bugs. What if we picked all GraphQL libraries and frameworks and test them against numerous GraphQL Operations?
Keep in mind that we're still talking about simply parsing the Operations. What if we add building a valid AST into the equation? What if we add executing the Operations as well? We almost forgot about validating Operations, a topic in itself.
A few years ago, there was a small group of people who started an amazing open source project: CATS The GraphQL Compatibility Acceptance Test . It's quite a mouthful, but the idea is brilliant. The idea was to build a tool so that different GraphQL implementations can prove that they work as intended. Unfortunately, the project's last commit is from 2018.
Alright, parsing a URL seems simple and well understood. Parsing GraphQL Operations is a nightmare. You should not trust any GraphQL library without heavy testing, including fuzzing.
We're all humans. Building a GraphQL library is complex. I'm the owner of an implementation written in Go . It's no easy, it's a lot of code. A lot of code means, a lot of potential for bugs.
And don't get me wrong, this is not about hand-written parsers vs. generated parsers from a grammar. Turning a string into an AST is just one small piece of the puzzle. There's plenty of opportunities left for bugs.
You don't have to normalize a URL. If you can parse it in your language of choice, it's valid, otherwise it's not.
A different story with GraphQL. Here's an example:
A lot of foo! Let's normalize the Query.
That's a lot less foo, nice! I could have made it more complicated with more fragments, nesting, etc... What's the point?
How can we prove that all libraries and frameworks normalize the Query correctly? What happens if something goes wrong here? It might give an attacker an opportunity to ask for fields which he/she is not allowed to use. Maybe there's a hidden field and by wrapping it with a weird inline fragment @skip combo, we're able to query it.
As long as we're not able to prove that it's impossible, I'd consider it's possible, prove me wrong!
To summarize: No Normalization for URLs. More nightmares for GraphQL.
I've implemented GraphQL Operation validation myself. One of the unit test files is more than 1000 LOC . What I've done is, I copied the complete structure from the GraphQL Specification one by one and turned it into unit tests. There are various ways how this could go wrong. Copy & paste Errors, general misunderstanding, implementing the logic to make the tests green while the logic is still wrong. There are a lot of pitfalls you could fall into.
Other libraries and frameworks are probably taking different approaches. You could also copy the tests from the reference implementation , but that's also no guarantee that the logic is 100% correct.
Again, as we don't have a project like CATS anymore, we're not really able to prove if our implementations are correct. I hope, everybody is doing their best to get it right.
Until then, don't trust any GraphQL validation library if you haven't tested it yourself. Use many Operations for testing.
Summary: If a standard library can parse your URL, it's valid. If your library of choice validates a GraphQL Operation, you should still be cautious, especially when you're dealing with PII (personally identifiable information).
At this point, we've probably passed a few bugs already by passing our request through the parser, normalization and validation. The real trouble is still ahead of us, executing the Operation.
When executing a GraphQL Operation, it's not only the frameworks' responsibility to do the right thing. At this point, it's also a great chance for the framework user to mess up. This has to do with the way GraphQL is designed. A GraphQL Operation can walk from node to node, wherever it wants, it you don't do anything about it. So, the range of possible attacks goes from simple denial of service attacks to more sophisticated approaches that return data which should not be returned. For that reason, we'll give this section a bit more structure.
If you want to rate-limit a REST API user, all you have to do is store their IP in an in memory story, e.g. Redis, and rate limit them with you algorithm of choice, e.g. a sophisticated window rate limiter. Each request counts as one request, this sounds stupid but matters in the context of GraphQL.
With GraphQL on the other hand, you cannot apply the same pattern. One single Operation is enough to bring the GraphQL Server to a halt.
Here are a few examples of how to build a denial of service attack with GraphQL:
Moving back and forth, forever.
Simply ask for a lot of foos:
How about exploiting N+1 problems?
Each layer of nesting asks for more nested data, hence exponential growth of execution complexity.
A few things you should consider:
Usually, GraphQL operations come in the form of a JSON over an HTTP POST request. This JSON could look like this:
The first thing you should do is to limit the amount of JSON bytes you're accepting. How large can your larges Operations be? A few Kilobytes? Megabytes?
Next, when parsing the Operation, how many Nodes are too many Nodes? Do you accept any amount of Nodes in a Query? If you have analytics running on your system, maybe take the larges Query, add a margin on top and set the limit there?
Talking about the maximum number of Nodes when parsing an Operation. Does your framework of choice actually allow you to limit the number of Nodes it'll read?
Next, let's talk about the options you have when the Operation is parsed.
You can calculate the "complexity" of the Operation. You could "walk" through the AST and apply some sort of algorithm to detect the complexity of the Operation. One way to define complexity is for example the nesting.
Here's a Query with nesting of 1:
This Query has nesting of 2:
This algorithm is a good start. However, it has some downsides. Nesting alone is not a good indicator of complexity.
To better understand the complexity, you'd have to look at the possible number of nodes, a field can return. This is similar to EXPLAIN ANALYZE in SQL. It gives you some estimates on what the Query Planner thinks, how the Query will be executed. Keep in mind that these estimations can go completely wrong.
So, estimating is not bad, but you should also look at the real number of returned nodes during execution.
Companies with public GraphQL APIs, like e.g. GitHub, have implemented quite sophisticated rate limiting algorithms. They take into account the number of nodes returned by each field and give you some limits based on their calculations.
Here's an example Query from their explanation:
There's one important thing we can learn from them in terms of GraphQL Schema design. If you have a field that returns a list, make sure there is a mandatory argument to limit the number of items returned, e.g. first, last, skip, etc... Only then, it's actually possible to calculate the complexity before executing the Operation.
Additionally, you'd also want to think about the user experience of your API. It's going to be a poor user experience if GraphQL Operations randomly fail because there's too much data coming back from a list field for some instances.
At the end of the post, we'll pick up this topic again and talk about an even better approach, an approach that works well for both the API provider and the consumer.
This one should be quite known, but it should still be part of the list.
Let's have a look at a simple resolver using graphql-js:
A Query for this resolver might look like this:
In case of a badly written implementation of db.loadHumanByID, the SQL statement could look like this:
In case of the "happy" path, the SQL statement will be rendered like this:
Now, let's try a simple attack:
In case of our attack, the SQL statement looks slightly different:
As 1=1 is always true, this would return all users. You might have noticed that the function can only return a single user, not a list of users, but for illustration purposes, I think it's clear that we have to deal with the issue.
What can we do about this?
Be liberal in what you accept, and conservative in what you send. [Postels Law]
The solution to the problem is not really GraphQL-specific. You should always validate the inputs. For database access, use prepared statements or an ORM that abstracts away the database layer so that you're not able to inject arbitrary logic into the statement by design.
Either way, don't trust user inputs. It's not enough to check if it's a string.
Another attack vector is incomplete authentication logic. There might be different Query-Paths to traverse to the same object, you have to make sure that every path is covered.
Here's an example schema to illustrate the problem:
In the resolver for the field me, you extract the user ID from the context object and resolve the user. So far, there's no issue with this schema.
Later on, the product owner wants a new feature, so a new team member adds a new field to the Query type:
With this change, you have to make sure that the field userByID is also protected by an authentication middleware. It might sound trivial but are you 100% sure that your GraphQL doesn't contain a single access path that is unprotected?
We'll pick this item up at the end of the post because there's a simple way to fix the issue.
Traversal attacks are very simple to exploit while hard to spot. Looking at the previous example, let's say you should only be allowed to view your friends id and name;
A simple Query to get the current user looks like this:
As we inject the user ID into the me resolver ourselves, there's not much an attacker can do.
What about this Query?
With this Query, we're loading all friends and their friends. How can we prevent the user from "traversing" this path?
The question in this case is, do you protect the edge (friends) or the node (User)? At first glance, it looks like protecting the edge is the right way to do it.
So, whenever we enter the field "friends", we check if the parent object (User) is the currently authenticated user. This would work for the Query above, but it has a few drawbacks.
One of which is, if you only protect edges, you'd have to protect all of them. Here's another Query that would not be protected by this approach, but it's not the only issue.
If you haven't protected the userByID field, we could simply guess user IDs and collect their data. Heading over to the next section, you'll see why protecting the edges is not a good idea.
Your GraphQL Server Framework might implement the Relay Global Object Identification specification. This spec is an extension to your GraphQL schema to make it compatible with the Relay client, the client developed and used by Facebook.
What's the problem with this spec? Let's have a closer look at what it allows us to do:
The Relay spec defines that each Node in a Graph must be accessible through a globally unique identifier. Usually, this ID is the base64 encoded combination of the __typename and the id fields of a node. With the node returned, you're able to use fragments to ask for specific node fields.
This means, even if your Server is completely secure, by enabling the Relay Extension, you're opening up another attack vector.
At this point, it should be clear that protecting the edges is a cat and mouse game which is not in favor of you.
A better solution to solve the problem is by protecting the node itself. So, whenever we enter the resolver for the type User, we should check if the currently authenticated user is allowed to request the fields.
As you can see, you have to make decisions very early on when designing your GraphQL Schema as well as the Database Schema to be able to protect nodes properly. Whenever you enter a node, you must be able to answer the question if the currently logged in user is allowed to see a field or not.
So, the question arises if this logic should really sit in the resolver. If you ask the creators of GraphQL, their answer would be "no". As they've already solved the problem in a layer below the resolvers, the data access layer or their "Entity (Ent) Framework", they didn't address the issue with GraphQL. This is also the reason why authorization is completely missing from GraphQL.
That being said, solving the problem a layer below it not the only valid solution. If done right, it can be completely fine to solve the problem from within the resolvers.
Before we move on, you should have a look at the excellent entgo framework and its architecture. Even if you're not going to use Golang to build your API layer, you can see how much thought and experience went into the design of the framework. Instead of scattering authorization logic across your resolvers, you're able to define policies at the data layer and there's no way to circumvent them. The access policy is part of the data model. You don't have to use a framework like entgo, but keep in mind that you'd then have to solve this complex problem on your own.
Again, we'll revisit this vulnerability later to find a much simpler solution.
A lot of GraphQL servers are also API Gateways or Proxies to other APIs. Injecting GraphQL arguments into sub-requests is another possible threat we have to deal with.
Let's recall the schema from above:
Let's imagine this Schema is implemented using a REST API with the GraphQL API as an API Gateway in front. The resolver for the userByID field could look like this:
Now, let's not fetch the user but two of their friends! Here's the Query (totally valid):
This results in the following GET requests:
Why is this possible? The ID Scalar should be serialized as a string . While "7" is a valid string, "7/friends/1" is also.
To solve the problem, you have to validate the input. As the GraphQL type system is only validating if the input is a number or a string, you need to go one step further. If you're accepting strings as input, e.g. because you're using a UUID or GUID, you have to make sure you've validated them before usage.
How can we fix it?
Again, we need to validate the inputs. WunderGraph offers you a simple way to configure JSON Schema validation for all inputs. This is possible, because WunderGraph is keeping your Operations entirely on the server. But we'll come to that later.
Anybody else should make sure to validate any input before using it from your resolvers.
GraphQL Introspection is amazing! It's the ability of the GraphQL to tell clients everything about the GraphQL Schema. Tools like GraphiQL and GraphQL Playground use the introspection Query to then be able to give the user autocompletion functionalities. Without Introspection and the Schema, tools like these wouldn't exist. At the same time, introspection also has a few downsides.
The GraphQL schema can contain sensitive information. There's a possibility that your GraphQL schema is leaking internal information or fields that are only used internally. Maybe one of your teams is working on a new MVP which is not yet launched. Your competitors might be scraping your GraphQL API using the introspection Query. Whenever there's a change in the schema, they could immediately see this using a diff.
What can we do about this? Most guides advise you to disable the Introspection Query in Production. That is, you'll allow it during development but disallow introspection Queries when deploying to production.
However, due to the friendliness of some GraphQL framework implementations, including the graphql-js reference implementation, disabling introspection doesn't really solve the issue . Keep in mind that every implementation depending on the graphql-js reference is also affected by this.
So, if disabling introspection doesn't help, what else can we do about it? If your API is only used by your internal staff, you can the execution of introspection Queries with an authentication middleware. This way, you would add a layer of authentication in front of the GraphQL execution. Obviously, this only works for APIs that always require authentication because otherwise users would not be able to make a single request.
If you're building an app that can be used by users without authentication, the proposed solution doesn't work.
To sum up, by disabling introspection at runtime, you're making it a bit more complicated to introspect the schema, but with most frameworks it's still possible.
The next vulnerability will also take advantage of this issue. The ultimate catch-all solution will be presented at the end.
There are a number of services and tools like e.g. Postgraphile or Hasura that Generate APIs from a database schema. The promise is simple, point the tool at the Database, and you'll get a fully functional GraphQL Server.
As we've previously discussed, it's not easy and sometimes impossible (so far) to fully disable introspection at runtime.
Generated GraphQL APIs usually follow a common structure to generate their CRUD resolvers. This means, it's quite easy to spot if we're dealing with a custom-made use-case driven API or a generated API. Why is this an issue?
If we're not able to disable introspection we're leaking information of our complete database schema to the public. It's already a questionable approach if you want to have tight coupling between client and server, which is the case if we're generating the API from the database schema. That being said, in terms of security, this means we're exposing our whole Database schema to the public.
By exposing your Database schema to the public, you're giving attackers a lot of information to find vulnerabilities, try SQL injections, etc...
I know it's a repetitive schema but we're also going to address this issue at the end.
This issue is not directly a GraphQL vulnerability but a general threat for HTTP-based applications with Cookie- or Session-based authentication mechanisms.
If you're using frameworks like NextJS, Cookie-based auth is quite common (and convenient) so it's worth covering as well.
Imagine, we're building an app that allows users to send money to other users. A mutation to send money could look like this:
What can go wrong?
If we're building a Single Page Application (SPA) on app.example.com with an API on a different domain (api.example.com), the first thing you'd have to do to make this setup working is to configure CORS. Make sure to only allow your SPA domain and don't use wildcards!
The next thing that could go wrong is to properly configure the SameSite properties for the API domain, the one setting the Cookies. You'd want to use SameSite lax or strict, depending on the user experience. For Queries, it could make sense to use lax, which means we're able to use Queries from a trusted domain, e.g. a different subdomain. For Mutations, strict would definitely be the best option as we only want to accept those from the origin. SameSite none would allow any website to make requests to our API domain, independent of their origin.
If you combine a bad CORS configuration with the wrong SameSite Cookie settings, you're in trouble.
Finally, attackers could find a way to construct a link to our website that leads already authenticated users to make a transaction that they don't really want to do. To protect against this issue, you should add a CSRF middleware around mutations. WunderGraph does this out of the box. For each mutation endpoint, we configure a CSRF middleware. Additionally, we generate our clients in a way so that they automatically handle CSRF. As a developer using WunderGraph, you don't have to do anything.
This is another common issue with GraphQL APIs. GraphQL has a nice and expressive way of returning errors . However, some frameworks are by default just a bit too informative.
Here's an example of a response from an API that is automatically generated on top of a database:
This error message is quite expressive, it seems like it's coming from a SQL database and it's about a violation of a unique key constraint.
While helpful to the developer of the application, it's actually giving way too much information to the API consumer.
This message could be written to the logs if any. It seems like an app user is trying to create content with an ID that already existed.
In a properly designed GraphQL API, this actually doesn't have to be an error at all. A better way to design this API would be to return a union that covers all possible cases, like e.g. success, conflict, etc... But that's just a general problem with generated APIs.
In any case, if generated or not, There should always be a middleware at the very top of your HTTP Server that catches verbose errors like this and removes them from the reponse. If possible, don't just use the generic "errors" response object. Instead, make use of the expressive type system and define types for all possible outcomes of an operation.
REST APIs have a rich system of HTTP status codes to indicate the result of an operation. GraphQL allows you to use Interface and Union type definitions so that API consumers can easily handle API responses. It's very hard to programmatically analyze an error message. It's just a string which could change any time.
By creating Union and Interface types for responses, you can cover all outcomes of an operation explicitly. An API consumer is then able to switch case over the __typename field and properly handle the "known error".
Another long blog post comes to an end. Let's recap! We've covered 13 of the most common GraphQL vulnerabilities.
Here's a Checklist if you want to go through all of them.
- Parsing Vulnerabilities
- Normalization Issues
- Operation Validation Errors
- Denial of Service Attacks
- GraphQL SQL Injections
- Authentication Vulnerabilities
- GraphQL Authorization Traversal Attacks
- Relay Global Object Identification Vulnerability
- GraphQL Gateway / Proxying Vulnerability
- GraphQL Introspection Vulnerability
- Generated GraphQL APIs Vulnerability
- GraphQL CSRF Vulnerability
- GraphQL Excessive Errors Vulnerability
That's a lot of issues to solve before going to production. Please don't take this lightly. If you look at HackerOne , you can see the issue is real.
So, we want to get the benefits of GraphQL, but going through this whole list is just way too much work. Is there a better way of doing GraphQL? Is there a way of doing GraphQL differently so that we're not affected by all the issues.
The answer to this question is Yes! All you have to do is to adjust your view on GraphQL.
Most of us are using GraphQL APIs internally. This means, the developers who use the GraphQL API are in the same organization as the people who provide the API. Additionally, I'm assuming that we're not changing our GraphQL Operations at runtime.
All this boils down to the root cause of the problem.
Allowing API clients to send GraphQL Operations over HTTP is the root cause of all evil.
All this is completely avoidable, adds no value and only creates harm. It's absolutely fine to allow developers within a secured environment to send arbitrary GraphQL Operations. However, most apps don't change their GraphQL Operations in production, so why allow it at all?
Let's have a look at the Architecture you're most familiar with.
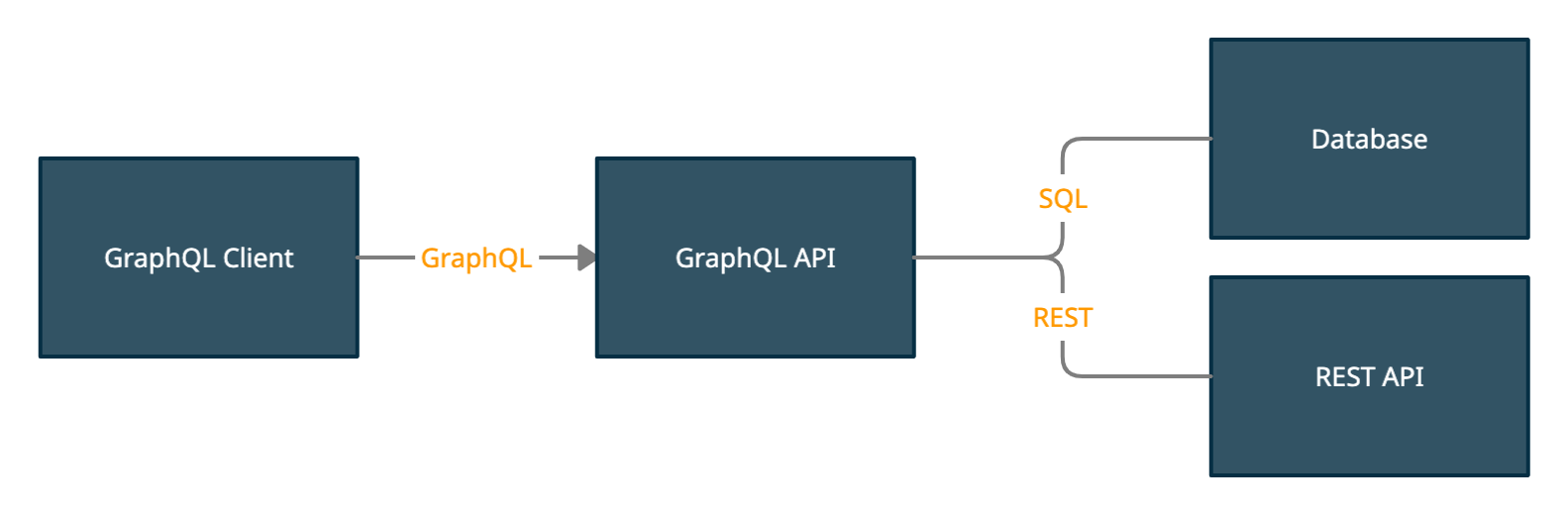
A GraphQL client talks GraphQL to a GraphQL Server.
Now, let's make a small change to the architecture to fix all 13 problems.
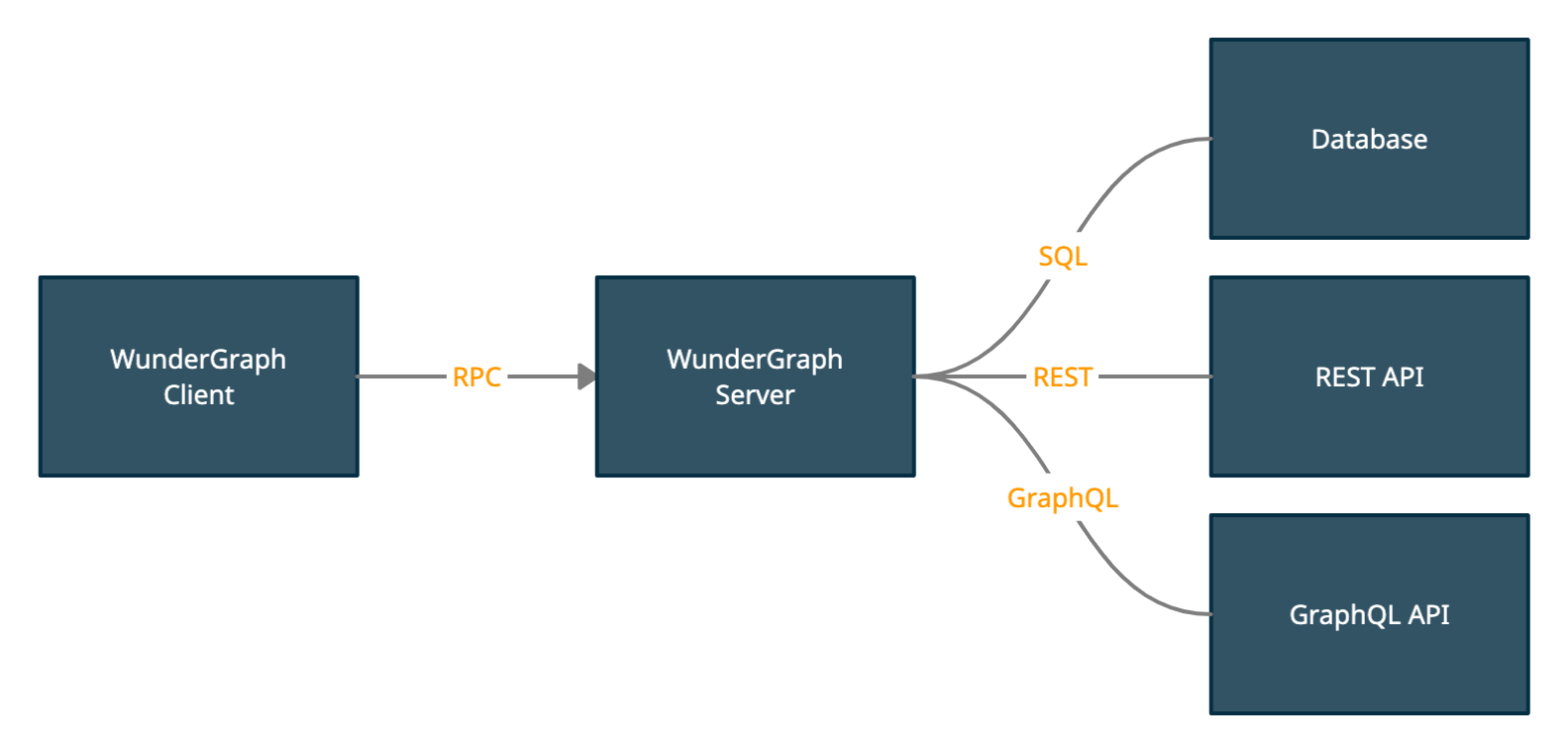
Instead of talking GraphQL between Client and Server, we're talking RPC, JSON-RPC more specifically. The Server then handles Authentication, Authorization, Caching, etc... for us and forwards Requests to the origin servers.
We haven't invented this though. It's not something new. Companies like Facebook, Medium, Twitter, and others are doing it.
What we've done is not just make it possible and fix the problems listed above. We've created an easy-to-use developer experience. We've assembled everything in one place. You don't have to install numerous dependencies.
Let's break down the solution a bit more, so you can fully understand how we're able to solve all the vulnerabilities.
The most secure code is the code that doesn't have to run at all. Every code has bugs. To fix bugs, we have to write more code, which means, we're introducing even more bugs.
So, how can we replace GraphQL with RPC over the wire?
During development, the developers define all Operations that are required for the Application. At the time when the app is ready to be deployed, we'll parse, normalize and validate all Operations. We'll then generate JSON-RPC Endpoints for each Operation.
As mentioned, we've normalized the Operations. This allows us to treat all inputs (the variables) like a JSON object. We can then parse the variable types and get a JSON Schema for the input. Additionally, we can parse the response schema of the GraphQL Query. This gives us a second JSON Schema. These two will be quite handy later.
By doing all this, it's happening automatically, we'll get two things:
- A number of JSON-RPC Endpoints
- JSON Schema definitions for the inputs and response objects of all Endpoints
By doing this at "deployment time", we don't have to do it during the execution again. We're able to "pre-compile" an execution tree. All that's left at runtime is to inject the variables and execute the tree.
We've borrowed this idea from SQL Database Systems, it's quite similar to "Prepared Statements".
Ok, this means we've solved three problems.
Unfortunately, we've also introduced a new problem! There are no easy to use clients that could make use of our JSON-RPC API.
Luckily, we've extracted two JSON-Schemas per Endpoint. If we feed those into a code-generator, we're able to generate fully type-safe clients in any language.
These clients are not only very small, but also super efficient as they don't have to do much.
So, in the end, we've not only solved three problems but also made our application more performant.
As another side effect, you're also able to generate forms from these JSON Schema definitions. It's fully integrated into WunderGraph.
Most GraphQL DOS vulnerabilities come from the fact that attackers can easily create complex nested Queries that ask for too much data.
As we've discussed above, we've just replaced GraphQL with RPC. This means, no dynamic GraphQL Operations. For each operation, we're able to configure a specific rate limit or quote. We can then rate limit our users easily, just like we did it with REST APIs.
We've extracted a JSON Schema for each RPC Endpoint. This JSON Schema can be adjusted to your desire to allow you to validate all inputs. Have a look at our documentation and how you can use the @jsonSchema directive to configure the JSON Schema for each Operation.
Here's an example of how to apply a Regex pattern for a message input:
The issue with Authentication was that you have to make sure that every possible Query path is covered by an authentication Middleware.
Introducing the RPC layer locks down all possible Query paths by default. Additionally, you're able to lock down all Operations behind an authentication middleware by default. If you want to expose an Operation to the public, you have to do so explicitly.
From an attackers' perspective, traversal attacks are only possible if there's something they can "traverse". By protecting the GraphQL layer with the RPC layer, this feature is removed from the public facing API. The biggest threat is now the developer itself, as they could accidentally expose too much data.
Recalling the issue from above, the problem with the Relay spec comes from two angles. One is incomplete Authentication protection, the other one is protecting edges when protecting nodes would be the correct way to do it.
The Relay specification allowed you to query any Node with the globally unique object identifier. This gives developers (and the Relay client) a powerful tool but is also another issue to solve.
You might see some repetitiveness here, but the Relay Vulnerability is also covered by the RPC facade.
This is one of the more complicated issues to solve. If we're using user inputs as variables for sub-requests, we have to make sure that these variables are exactly what we expect and not trying to exploit an underlying system.
To help mitigate these issues, we've made it very easy to define a JSON Schema definition for variables . This way, you're able to define a Regex pattern or other rules to verify the inputs before injecting them into subsequent requests, database Queries, etc...
The type system of GraphQL is absolutely great and very helpful, especially for making the lives of API consumers easier. However, when it comes to interpreting a GraphQL request, there are still a few gaps that we're trying to fix.
As we've seen in the description of the issue, disabling GraphQL introspection might not be as easy as it seems, depending on the framework you're using.
That said, Introspection is relying on the GraphQL layer. If you look at how Introspection works, it's just another GraphQL Query, even if it's a special one, with quite a lot of nesting.
Should I repeat myself again and tell you that by not exposing GraphQL, you're affected by this issue anymore?
Keep in mind that we're still allowing Introspection during development. Tools like GraphiQL will keep working, just not in production, or at least not with a special authentication token.
If the GraphQL API is a 1:1 copy of your database schema, you're exposing internals of your architecture via GraphQL Introspection. But then again, we've already solved this issue.
The way to mitigate this issue is by properly configuring CORS and SameSite settings on your API. Then, add a CSRF middleware to the API layer. This adds an encrypted CSRF cookie on a per user basis. Once the user is logged in, hand them over their csrf token. Finally, if the user wants to invoke a mutation, they must present their CSRF token in a special header which can then be validated by the CSRF Middleware. If there's anything going wrong, or the user logs out, delete the CSRF cookie to block all mutations until there's a valid user session again.
All this might sound a bit complicated, especially the interaction between client and server, sending CSRF tokens and Headers back and forth.
That's why we've added all this to WunderGraph by default. All mutations are automatically protected. On the server-side, we've go all the middlewares in place. The client is auto-generated, so it knows exactly how to deal with the CSRF tokens and Headers.
This issue is probably one of the bigger threats while easy to fix. After resolving an Operation, right before sending back the response to the client, make sure to strip out all sensitive information from the errors object.
This is especially important if you're proxying to other services. Don't just pipe through everything you've got from the upstream. If you're calling into a REST API and the response code is non 200, don't just return the response as a generic error object.
Additionally, think about your API as a product. What should the user experience of you "product" look like in case of an error? Help your users understand the error and what they can do about it, at least for "known good errors". In case of "bad errors", those unexpected ones, don't be too specific to your users, they might not be friendly.
Alright, you've seen that by changing our architecture and evolving our understanding of GraphQL, we're able to mitigate almost all of the issues that are coming from GraphQL itself. What's left is the biggest vulnerability of all systems, the people who build them, us, the developers!
If the process of debugging means, we're removing bugs, what should we call it when we write code?
Okay, we're almost done. We've left out one small group of APIs. We've been talking about private APIs for almost the entire article, but we did it for a good reason, probably 99% of the APIs are private.
But what about parter and public APIs? What if we don't want to put an RPC layer in front of our API? What if we want to directly expose GraphQL to our API consumers?
Companies like Shopify and GitHub are doing this. What can we learn from them?
Shopify currently has 1273 reports solved . They've paid in bounties $1.656.873 to hackers with a range of $500-$50.000 per bounty.
Twitter resolved a total of 1364 issues with a total of $1.424.389.
Snapchat only paid out $439.067 with 389 reports resolved.
GitLab paid an astounding $1.743.639 with a total of 845 issues resolved.
These bounties are not just related to GraphQL, but all the companies listed above can be found on the list of reported GraphQL issues.
There's a total of 70 reports on GraphQL with lot's of bounties paid out. If you search on other bug bounty websites, you'll probably find more.
Companies like GitHub have people who build specialized infrastructure to better understand how their GraphQL API is being used. I was pleased to meet the amazing Claire Knight and listen to her talk on the last GraphQL Summit, it's been quite some time...
I've presented you all this data to be able to make two points.
First, do you really need to expose your GraphQL API? If not, excellent! You're able to apply all the solutions from this article.
If, by all means, you absolutely want to expose a GraphQL API, make sure you have the expertise it takes to do so. You should have security experts in house or at least hire them, you should be doing regular audits and do pen-testing. Don't take this easy!
Do you have questions or want to discuss APIs, GraphQL and Security? Meet us on Discord
We're also happy to jump on a call with you and give you a Demo. Book now a free meeting!
Are you interested in how the GraphQL-to-RPC concept works in reality? Have a look at our one minute Quickstart and try out the concepts discussed in this article.
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


