
99% Smaller GraphQL Queries with AST Minification

TL;DR
Cosmo Router makes federated GraphQL faster by sending much smaller generated queries to subgraphs. AST minification reduces repeated selection sets, lowers parser overhead, and improved benchmark performance without requiring changes to subgraph code.
Make it work, make it right, make it fast. You've probably heard this mantra before.
In the context of GraphQL Federation Routers, this means that you should first be able to process some Queries. Next, you should make sure that all possible Queries and Schemas can be processed correctly, and that results match your expectations. Finally, you should optimize the performance of the overall system including Routers and Subgraphs.
This article is for platform engineers and API owners running GraphQL federation at scale who are hitting parser bottlenecks in subgraphs.
Key results:- Cosmo subgraph queries up to ~50% smaller than Apollo Router for complex workloads.
- Up to 99% reduction in query text size on a 1.4M-character internal case (to ~10K).
- Observed P95 latency ~25% lower and throughput ~21% higher vs Apollo-generated queries in GraphQL Faker benchmarks.
Improving the performance of a GraphQL Federation Router is a continuous process.
Some optimizations are easy to spot, e.g. through profiling or monitoring.
Others require a much deeper understanding of the problem space and are harder to achieve. Most teams instinctively focus query optimization efforts on the router itself, but as we'll show, the real bottleneck often hides in the subgraph parser.
In this article, we'll talk about one such hard to find optimization: AST Minification. We'll demonstrate how Cosmo Router allows your Subgraphs to process Requests up to 25% faster compared to Apollo Router. What's interesting about this optimization is that it's not that much about the Router performance itself, but about the difference in how Apollo and Cosmo Router plan Queries.
We've discovered that with our new approach, Cosmo Router generates up to ~50% smaller Subgraph Queries compared to Apollo Router, which results in a performance improvement of up to 25% without changing a single line of code in the Subgraph.
Companion reading for planning and execution
AST minification is one lever; these posts cover adjacent bottlenecks and how we measure them:
- How Normalization Affects Query Plan Caching in Federation — why canonical query shapes matter before the planner even runs.
- Dataloader 3.0: Solving the N+1 Problem — batching entity fetches so execution does not undo router-side wins.
- From 26 minutes to 20 seconds: Optimizing Large GraphQL Operations in Go — profiling huge operations end to end when the subgraph is the slow path.
Let's unroll the story of how we ended up here.
We keep getting asked by prospective customers how Cosmo Router compares to Apollo Router in terms of performance.
To understand the problem, we need to look at the different stages of a GraphQL Federation Request. We can split the process into three main stages:
- Parsing
- Planning
- Execution
The Router needs to parse the incoming Query. Once the JSON is parsed, the Router needs to parse the GraphQL Document.
The document needs to be Normalized and Validated. After all of these steps, the Router can start planning the Query.
Planning is probably the most complex part. It's the process of analyzing the AST (Abstract Syntax Tree) of the Document and generating Subqueries for the Subgraphs. There are a lot of parameters that need to be considered during this process. For example, directives like @external, @requires, or @provides can influence the planning process.
Another complex topic is the handling of abstract types like unions and interfaces. When a field is required on an abstract type, but not all Subgraphs provide this field, the Planner needs to rewrite the Query to get the field from a Subgraph that provides it. As a consequence, the Planner needs to "rewrite" the Selection Set in this case, which gets complicated with Fragments. The nature of Fragments is that they can be used in multiple places in the Query, so the Planner needs to take one of the possible paths. It can inline all Fragments and treat the whole Query like a single Tree with duplicated Nodes, or it can try to keep the Fragments and "rewrite" them in a way that's valid across all occurrences in the Query. We'll talk more about this topic later in the article. I think it's pretty clear that the planning process is a complex computational problem.
Once the planning phase is done, the Router can start executing the Plan.
Execution is the process of sending one or more Subqueries to the Subgraphs, some of which might depend on the results of other Subqueries, and then merging the results back together to form the final Response. It's a complex process, and we've talked about it in detail in previous articles.
Now that you understand the three main stages of a GraphQL Federation Request, let's drill down into the core problem: The Subgraph as the performance bottleneck. Or more specifically, the parsing Phase of the Subgraph.
Parsing, Normalization and Validation are expensive, especially for large Queries, but there are ways to optimize these steps, e.g. by introducing one or more caches.
Planning is even more expensive, but it can be optimized as well, and the results of the planning phase can be cached as well.
The execution phase is mostly I/O-bound, so there are physical limits to how much you can optimize it.
But there are some factors that can have a big impact on the performance of the execution phase, e.g. the number of Subgraph Requests.
If you optimize the parsing and planning phase, cache all the intermediate results that can be cached, and minimize the number of Subgraph Requests, what's left is the performance of the Subgraph itself.
In our extensive research, we've discovered that the performance of GraphQL Parsers in Subgraphs is the limiting factor of the overall performance.
You might be surprised by this statement, because you'd probably expect that the Database or Network I/O is responsible for the bulk of the time spent processing a Query.
GraphQL is implemented in a variety of programming languages, and the performance of the Parser is usually not the main focus of the implementation.
The reason for this is that GraphQL Frameworks are usually built with a focus on monolithic implementations. In a monolithic implementation, or monograph, Queries are usually user-defined and not generated by a Router.
As I've explained above, rewriting Queries to satisfy the requirements of GraphQL Federation can make them quite bloated.
The use case that led us to the discovery of the Subgraph Parser as the limiting factor was a prospecting customer who wanted to break apart a monolithic GraphQL Server into multiple Subgraphs.
They had extensive experience with GraphQL and were heavy users of Abstract Types and Fragments, perfect conditions for the problem to manifest.
They've shown us a Query and the corresponding Subgraph Queries generated by Apollo Router, Cosmo Router, and a Flame Graph of the whole request. The Flame Graph showed that the Subgraph Parser was the limiting factor of the overall performance.
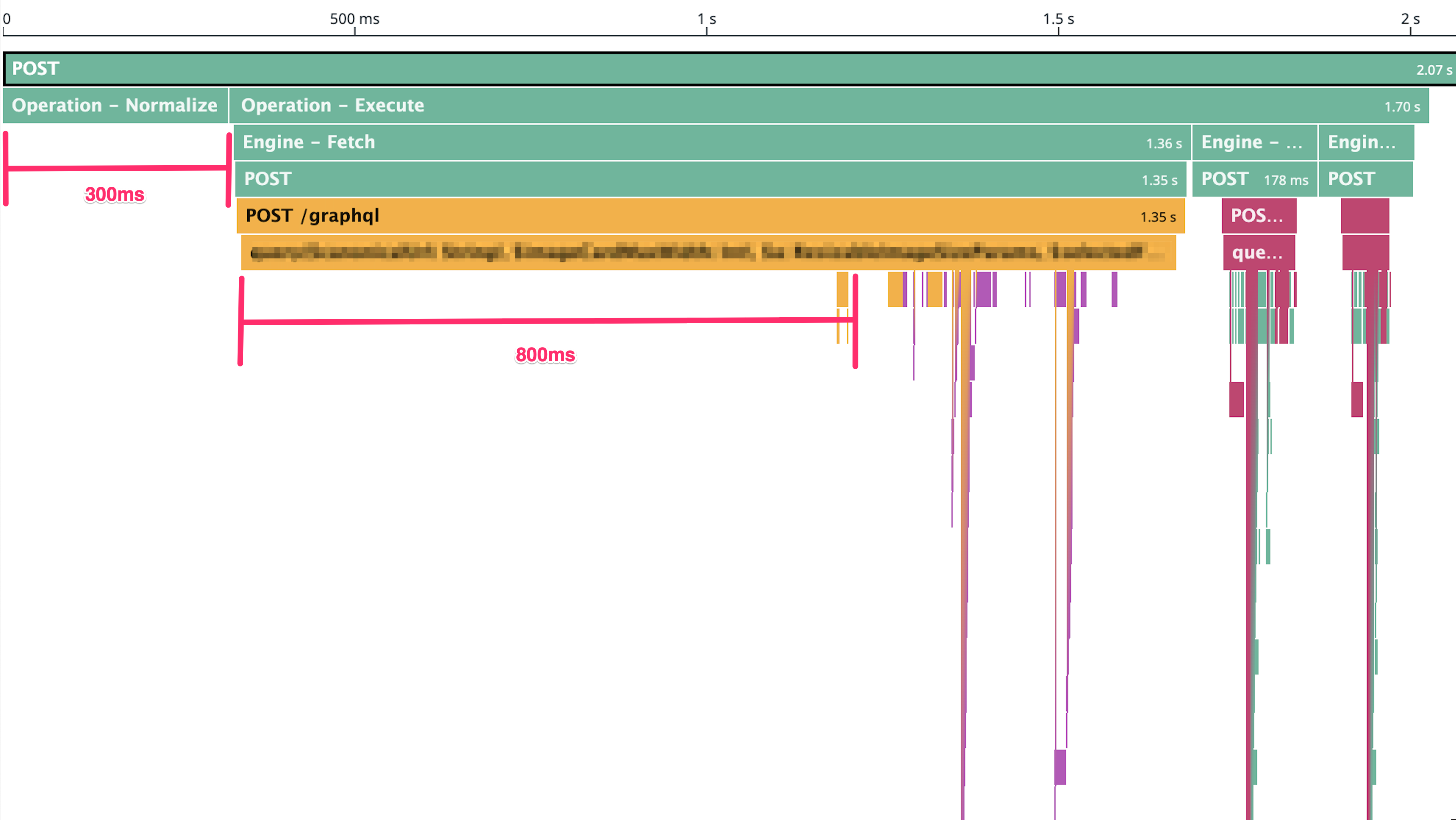
Let's analyze the Flame Graph. The client makes a single POST Request to the Router. The Router then makes 3 Subgraph Requests sequentially.
Overall, the request takes ~2 seconds. The Graph shows that the Router spends roughly 300ms to Normalize the incoming Query. It then makes a very complex request to the first Subgraph, which shows "no activity" for at least 800ms. The other two subsequent Subgraph Requests are much smaller and don't seem suspicious.
We've already introduced a cache for the Normalization step, so that problem is solved. But for the Subgraph Parser, we needed a different solution: AST Minification.
I'd like to underline 40% of the overall request time is spent in the Subgraph Parser. The first Subgraph takes 1350ms in total, and 800ms of that time is spent in the Parser, that's ~60% of the time spent in the Subgraph.
Why does it take so long you might ask?
For this particular Query, the Planner generated a Subgraph Query with ~1.4M of GraphQL Query Text. It simply takes a long time to parse, normalize, and validate such a large Document.
For the same Query, Apollo Router generated a Subgraph Query with just about 20K, which is 75 times smaller.
Before we talk about the solution, I'd like to explain the different approaches in Query Planning of Apollo and Cosmo Router, and how we not just ended up with a less bloated Query, but actually 50% smaller Queries and 25% faster Subgraph Requests.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
We're not aware of the internals of how Apollo Router/Gateway plans Queries, but we can look at the generated Subgraph Queries to get an idea of how it works, and how it differs from Cosmo Router.
Let's say you've got a client that sends the following Query to the Router.
We're assuming that the Company is using GraphQL in a very advanced way. They use Relay Client to colocate Fragments with Components, and they use a lot of Abstract Types and Interfaces:
For simplicity, let's assume that all requested fields can be resolved by a single Subgraph.
Here's "roughly" how Apollo Router would plan this Query:
That's 688 characters in total.
Note that the Apollo Query Planner leaves the structure of the Query mostly untouched. It only adds some __typename fields to the Fragments to help resolve the Abstract Types.
The Cosmo Query Router on the other hand handles the Query differently.
In the first stage, the Router normalizes the Query and inlines all Fragments.
Here's how the normalized Query looks like:
Note that Cosmo is adding the __typename fields to the Fragments as well, but at the same level as the inline Fragments.
At this stage, we're counting 578 characters.
In the next stage, we're applying a technique called "AST Minification".
First, we're sorting all Selection Sets alphabetically. Next, we're "searching" for common Selection Sets in the Query and extracting them into Fragments to reduce duplication.
Here's the final Query that Cosmo Router sends to the Subgraph:
Our final Query is 356 characters long, which is ~48% smaller than how Apollo Router planned the Query.
The AST Minification Algorithm is very naive, yet it's very effective in reducing the size of the Query.
Here's how it works:
- Normalize the Query
- Inline all Fragments
- Deduplicate Fields in Selection Sets
- Sort all Selection Sets alphabetically
- Sort all Selection Sets in a stable way
- Fields first, then Inline Fragments
- Sort Fields alphabetically
- Sort Fields with the same Name by Alias
- Sort all Directives on Fields and Inline Fragments
- Sort all Arguments on Fields and Directives
- Sort all Selection Sets in a stable way
- Traverse the AST and create a Hash for each Selection Set
- Print the Enclosing Typename into the Hash function
- Print the Selection Set into the Hash function
- Store the Hash, Depth of the Selection Set, a Counter (1) and a Reference to the Selection Set in a Map
- If the Hash already exists, increment the Counter and append the Reference to the Selection Set
- If the Depth of the Selection Set is greater than the Depth stored in the Map, update the Depth to the higher value
- Create a list of "Replacements" with all Selection Sets that have a Counter > 1
- Sort all Replacements by Depth, highest first
- If the Depth is the same, sort alphabetically by Enclosing Typename to ensure stable sorting (makes the algorithm deterministic and easier to test)
- Apply the Replacements Depth-first
- For each Replacement, create a Fragment and make a deep copy of the Selection Set
- Copy the Directives from the Field or Inline Fragment to the Fragment
- Fragment names start with "A", "B", "C", ..., "AA", "AB", ...
- For each Selection Set to replace, create an Inline Fragment with the Fragment Name and replace the Selection Set with the Inline Fragment
In simple terms, the algorithm is looking for common Selection Sets in the Query and extracts them into Fragments.
A few very important points to mention:
It's very important to print the enclosing Typename into the Hash function. It's possible to have the exact same Selection Set on different Types.
Fragments have a Type Condition, so they can only be applied to a specific Type, but Selection Sets can be applied to multiple Types.
You achieve the most significant reduction in Query size when you replace Depth-first, meaning that you replace the leaves of the AST first.
For each Selection Set that we replace, we make a deep copy of all Selections and move them into a Fragment, replacing the Selection Set with an Inline Fragment with the same Type Condition as the Fragment.
If we would replace the Selection Sets top-down, we would replace orphaned Selection Sets after the first replacement, because we're making a deep copy on each replacement.
We've applied this algorithm to the use case that we've mentioned earlier, and the results look as follows:
The original Query of Cosmo Router was ~1.4M in size.
After AST Minification, the Query size was reduced to ~10K, which is a reduction of more than 99%.
The Query that Apollo Router generated was ~20K in size.
We made an experiment and applied the Cosmo AST Minification Algorithm to the Apollo Query, and the result was ~13K in size, which is an improvement of 35%.
We've also applied the Cosmo Normalization Algorithm to the Apollo Query, inlining all Fragments and deduplicating Fields.
The result was ~1.8M.
It seems that the Apollo Query Planner overall generates a more complex Query than Cosmo Router, which might result in more work for the Subgraphs.
If we're honest, without AST Minification, the Cosmo approach to Query Planning has a significant disadvantage.
However, with the algorithm in place, the outcome was more than we've expected.
We were hoping to get the Query size down to a similar size as Apollo Router, but we've ended up with a Query that's 50% smaller.
The question that remains is: Does the smaller Query size have a significant impact on the performance of the Subgraph? Does the additional complexity and overhead outweigh the benefits of a smaller Query?
To answer this question, we've conducted a series of experiments with a tool called "GraphQL Faker".
GraphQL Faker is a tool that generates a Mock GraphQL Server based on a Schema.
It's using GraphQL.js under the hood, one of the most widely used GraphQL Implementations in JavaScript.
First, we wanted to get a baseline of the performance of GraphQL Faker.
The total performance is not that important, we're only interested in the relative performance of the different Queries.
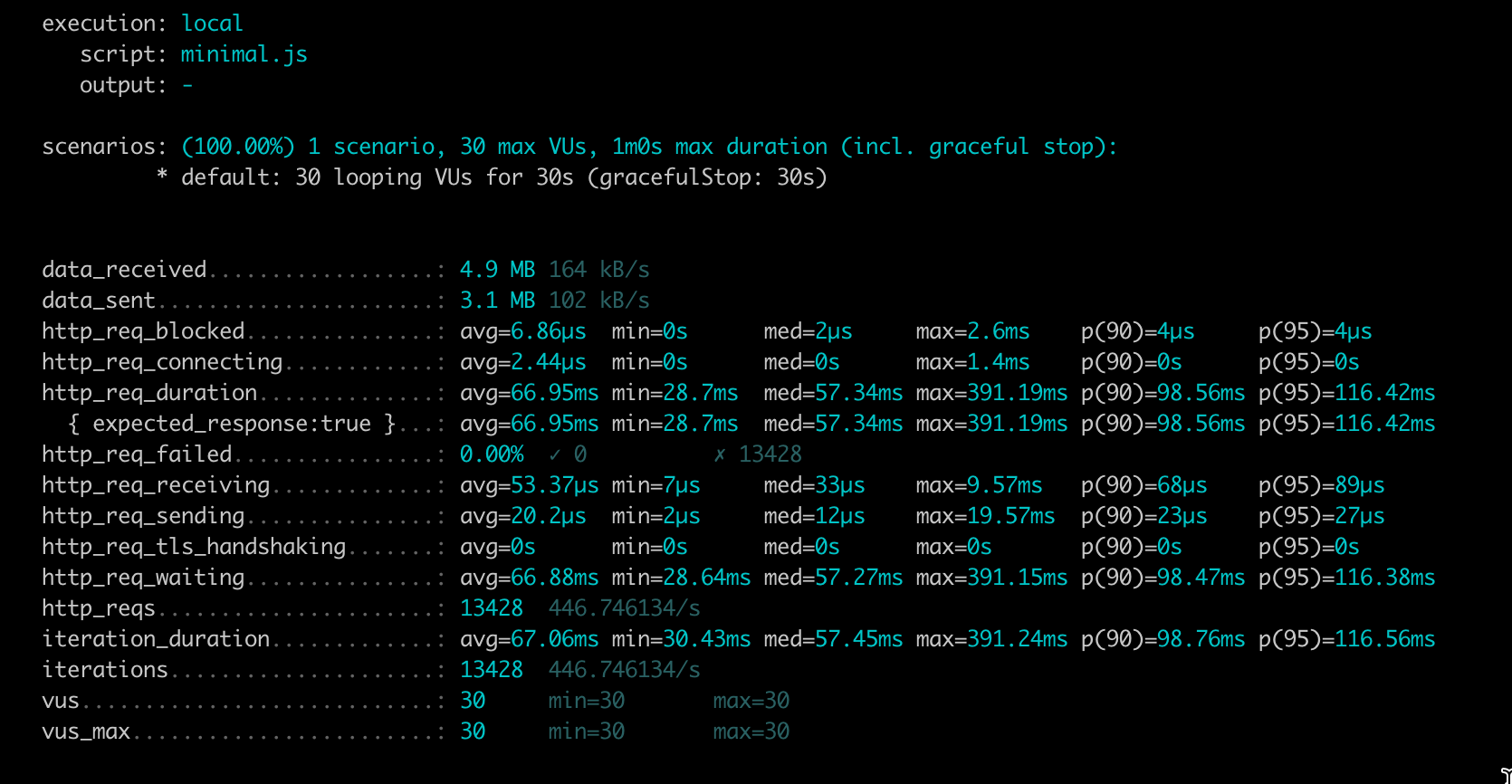
P95 is 116ms, throughput is 446 Requests per second.
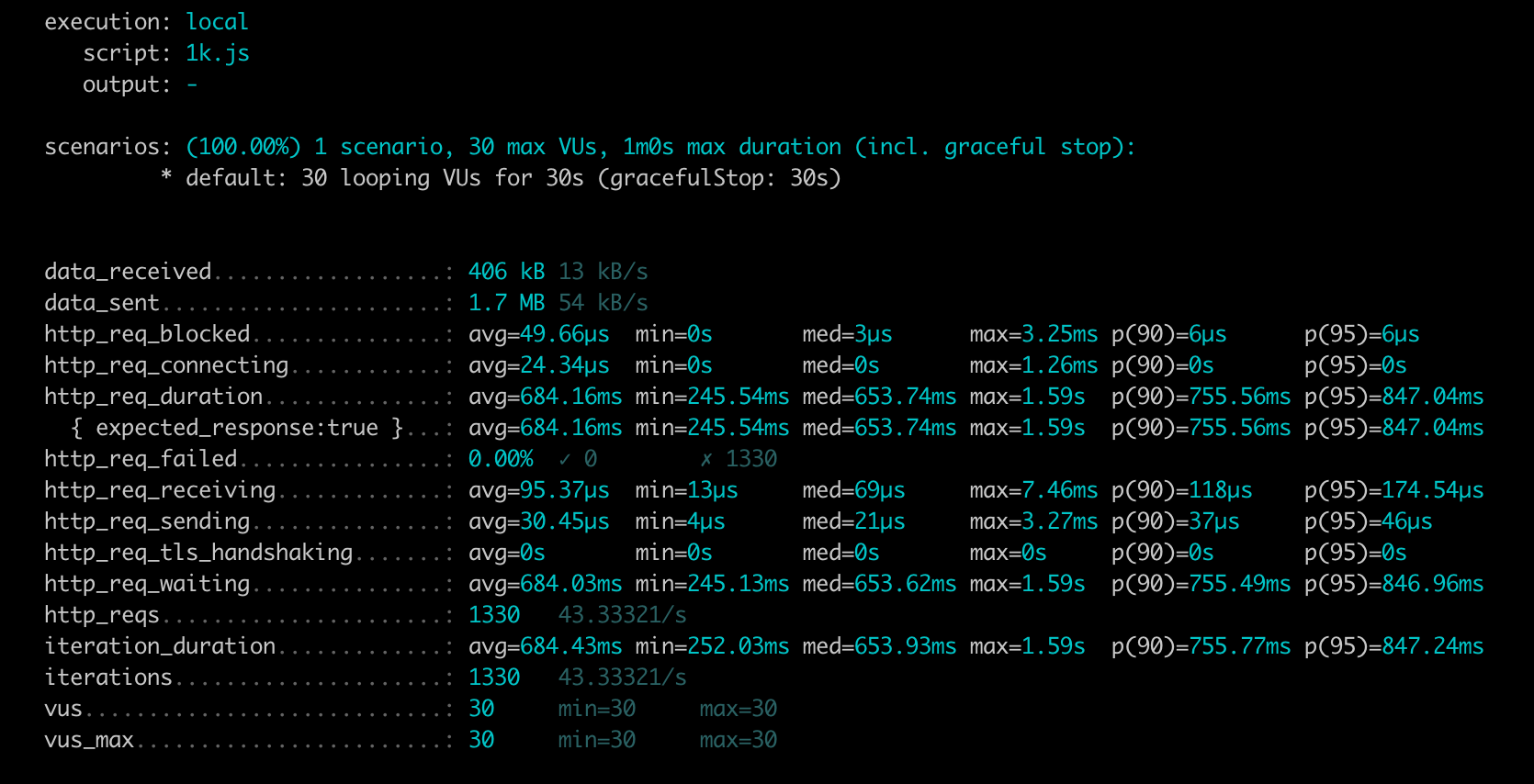
P95 is 846ms, throughput is 43 Requests per second.
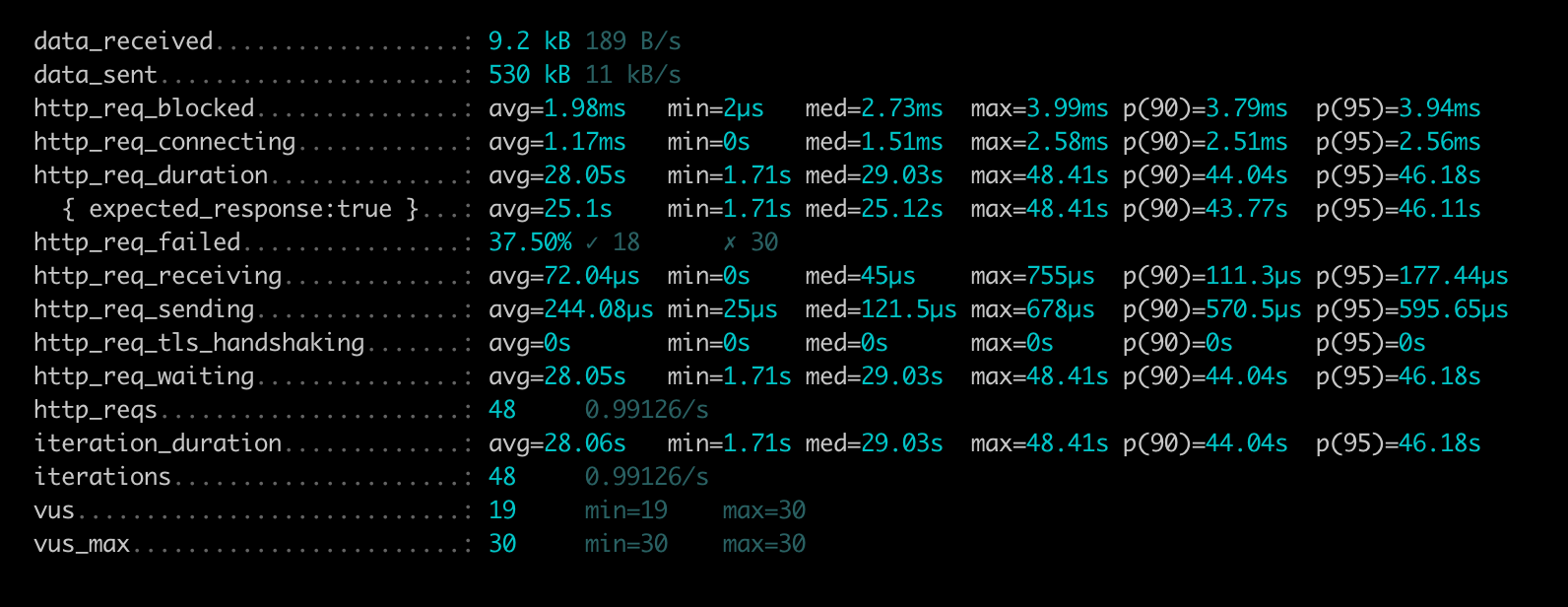
P95 is 46s, throughput is 0.99 Requests per second.
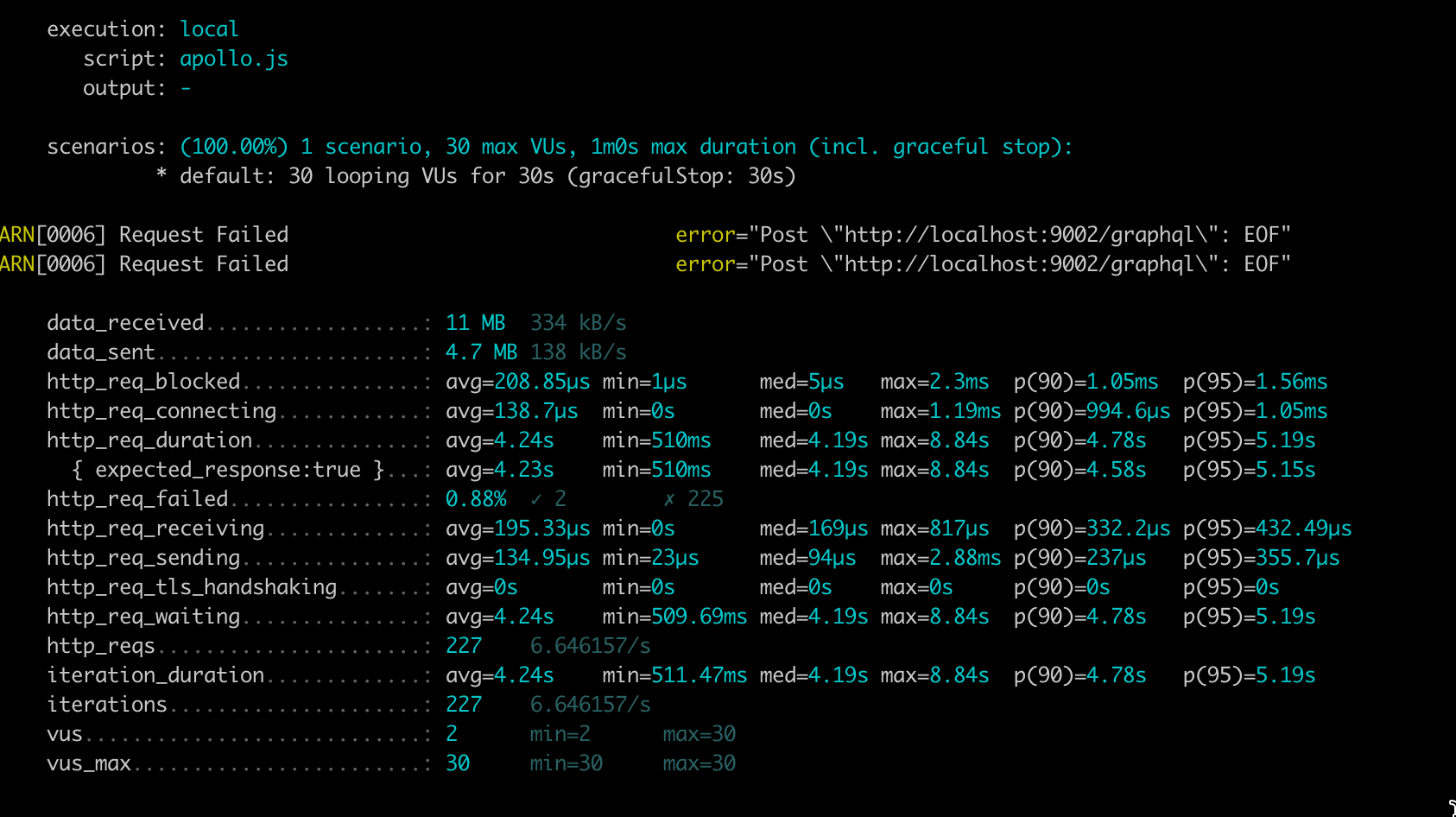
P95 is 5.19s, throughput is 6.64 Requests per second.
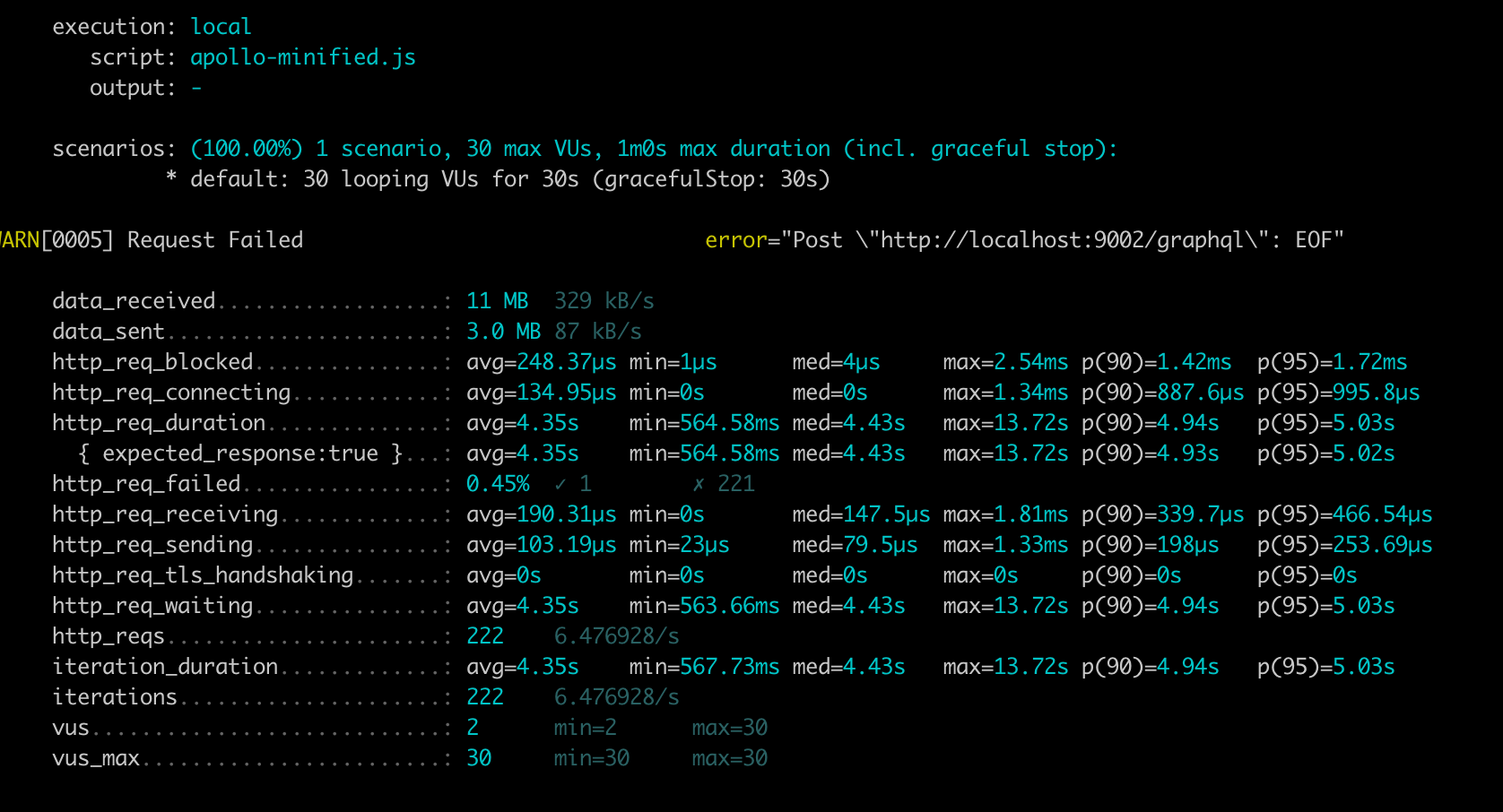
P95 is 5.03s, throughput is 6.47 Requests per second.
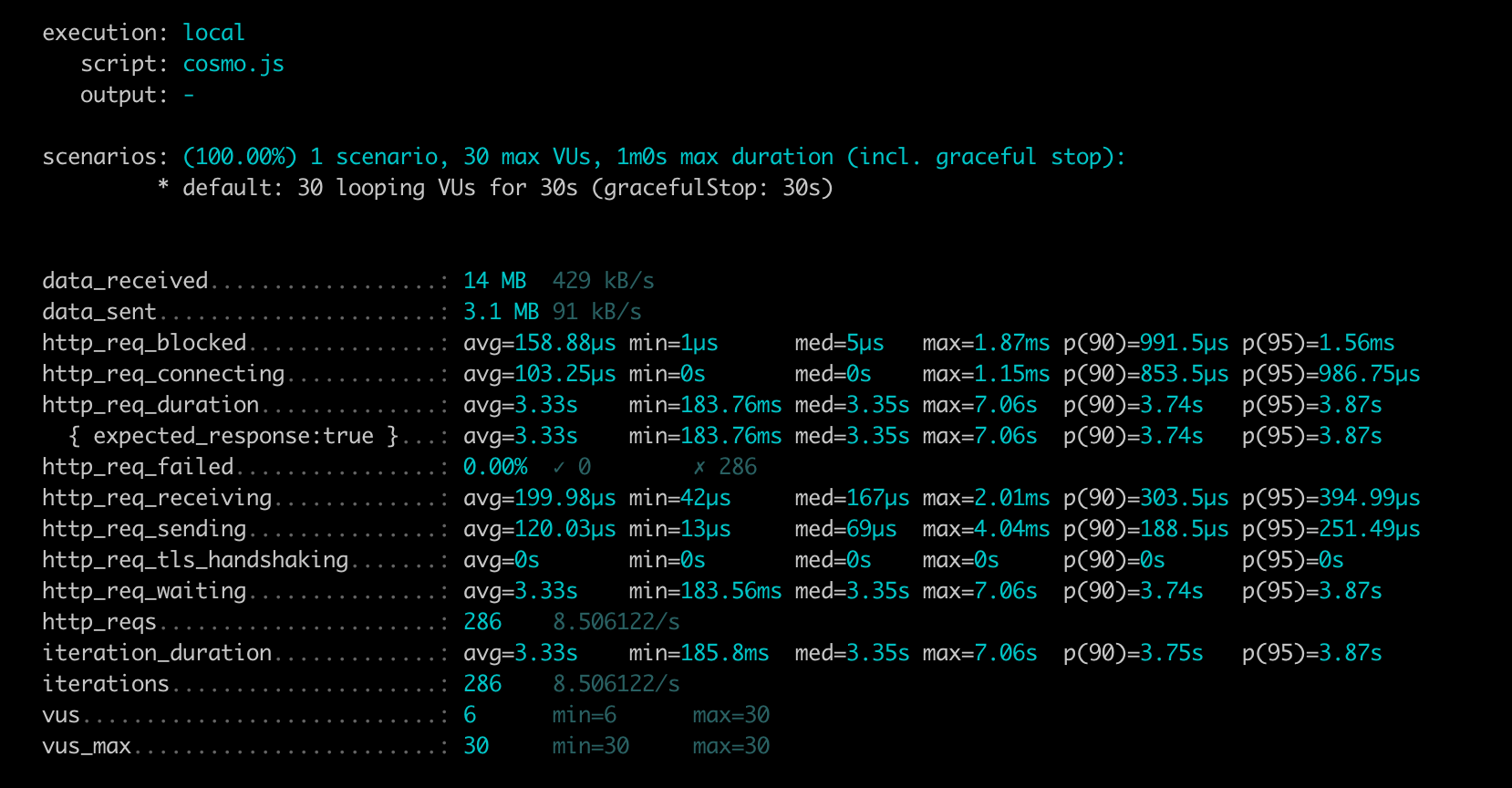
P95 is 3.87s, throughput is 8.50 Requests per second.
The baseline Benchmarks show that the performance of GraphQL Faker degrades significantly with an increasing number of fields.
What's interesting is that even if we're asking for the same field 1000 times, performance is extremely bad, even though we're not requesting more data compared to the query with 100 fields.
This indicates that performance of GraphQL Servers might correlate with the size of the Query, and not necessarily with the amount of data that's requested.
Furthermore, the Benchmark shows that the Cosmo Query has a 25% lower P95 compared to the Apollo Query, while the throughput is 21% higher.
Nothing comes without a cost. The AST Minification Algorithm is not free.
It's adding complexity to the Query Planner code, and it's adding overhead to the Planning Phase.
To handle the complexity, we've ensured that the Algorithm is stable and deterministic.
This doesn't just allow us to test the Algorithm in a predictable way, but we can also use Normalization to verify that the Minified Query is the same as the original Query.
Minification exports commonly used Selection Sets into Fragments, and Normalization inlines them back into the Query. This made it very easy to ensure that the Algorithm is lossless.
We've also measured the overhead of the Algorithm.
To minify a Query with 1.4M of GraphQL Query Text down to 10K, it takes about 40ms.
Compared to the time saved in the Subgraph, this is acceptable as we're saving almost 800ms of Subgraph Parser time. That said, the result of the Planning Phase is cached, so the overhead is only paid once per uncached unique Query. With Persisted Operations, you should almost never pay this cost.
We've already shared our work with our users, and one of the first questions was if we could make the Algorithm more sophisticated.
If you've paid attention, you might have noticed that the Algorithm is very naive. In case there are two Selection Sets that are "almost" the same, the Algorithm will not recognize this opportunity to extract two partial Selection Sets into a single Fragment.
We think that our "naive" approach perfectly hits the sweet spot between complexity and performance. It's very likely that a more sophisticated Algorithm will reduce the Query size even further, but this might come at the cost of exponentially increasing the overhead of the Minification process.
The implementation is open-source , so feel free to experiment with it and let us know if you can improve it.
In addition to just reducing the Query size, we're also looking into additional ways to optimize Subgraph performance.
One of the ideas we've got from one of our users is to introduce APQ (Automatic Persisted Queries) for Subgraphs.
APQ might be known more from the Client side, where the Client sends a Hash of the Query to the Server instead of the Query itself. This allows the Server to cache the parsed and normalized Query.
We're thinking about introducing a similar mechanism for the communication between the Router and the Subgraphs.
However, this comes with some challenges. Subgraph Frameworks might implement the Mechanism slightly differently, and the Router always needs to assume that the Subgraph doesn't have a populated cache for APQ.
In case of a cache miss, the Router needs to send two Requests to the Subgraph. Overall, APQ might improve the performance of the Subgraph further, but it also makes the system more complex.
It's probably a good idea to expore APQ, but the mechanism doesn't replace the need for optimal Query Planning and AST Minification.
Not all Frameworks support APQ, even when it's supported, you still need to parse, normalize, and validate a lot of Queries when Subgraph caches are cold, e.g. after a restart, new deployment, or cache eviction.
Depending on the performance of your Subgraph Framework, you might achieve up to 25% more performance from your Subgraphs. Some Subgraph Frameworks might even benefit more, depending on their performance characteristics.
What this means for you is that you can reduce your spend on Subgraph Infrastructure by 25%.
In addition, your users will love up to 21% faster Response Times, and we all know that faster Response Times lead to better User Experiences, higher Conversion Rates, and ultimately more Revenue. If you're looking for a good reason to make the switch to Cosmo, this might be it.
As we've shown in this article, there are fundamental differences in how different Routers plan Federated GraphQL Queries.
Planning is a very complex topic, and you've learned that the shape of the planned Query can have a significant impact on the performance of the overall System.
I hope you've enjoyed this article and learned something new. If you're interested in the work we're doing at WunderGraph, we're hiring for various positions to build the ultimate GraphQL Platform.
Frequently Asked Questions (FAQ)
It’s a planning step that normalizes queries, sorts selections, and extracts repeated selection sets into fragments. This shrinks subgraph queries, easing parser work and improving end-to-end performance.
The article shows Cosmo inlines fragments, deduplicates and sorts selections, then reuses common sets via fragments, producing smaller subgraph queries. Apollo mostly preserves the original fragment structure and adds __typename fields.
Cosmo generated up to ~50% smaller subgraph queries and achieved up to 25% faster subgraph execution. In the benchmark, Cosmo’s query had ~25% lower P95 (3.87s vs 5.19s) and ~21% higher throughput (8.50 vs 6.64 RPS).
The subgraph parser is identified as the limiting factor, with large planned queries spending significant time in parse/normalize/validate. Reducing query size directly cuts that parser cost.
Minifying a ~1.4M-character query to ~10K took ~40ms, and the result is cached so it’s usually paid once per unique query. Correctness is checked by re-normalizing (inlining) to verify the minified and original forms are equivalent.
No—APQ is discussed as future work that may help, but caches can be cold and implementations vary. The post states optimal planning and AST minification are still needed.
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


