
Dataloader 3.0: A new algorithm to solve the N+1 Problem

State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
While implementing Cosmo Router, an open-source replacement for Apollo Router, we ran into the problem of keeping our code for solving the N+1 Problem maintainable. Implementing a Router for federated GraphQL services heavily relies on the ability to batch nested GraphQL Queries to reduce the number of requests to the subgraphs.
To solve this problem, we developed a new algorithm that solves the N+1 Problem in way that's much more efficient and easier to maintain than our previous solution, which was based on the DataLoader pattern that's commonly used in the GraphQL community. Instead of resolving depth-first, we load the data breadth-first, which allows us to reduce concurrency from O(N^2) to O(1) and improve performance by up to 5x while reducing code complexity.
If you're interested in checking out the code, you can find it on GitHub .
I also gave a talk about this topic at GraphQL Conf 2023, which you can watch here:
The N+1 Problem is a common problem in GraphQL that occurs when you have a list of items and you need to fetch additional data for each item in the list. Let's look at an example to illustrate this problem:
First, we define four subgraphs:
Next, we define a query that fetches the top products and their reviews:
So where does the N+1 Problem got its name from? The +1 refers to the first request to fetch the topProducts from the Products subgraph. The N refers to the number of additional requests that are required to fetch the associated data for each product. Let's go through the steps of resolving this Query to see what this means in practice.
Let's assume the topProducts field returns 3 products. We have to make 3 additional requests to fetch the stock for each product from the Inventory subgraph. We also have to make 3 additional requests to fetch the reviews for each product from the Reviews subgraph. We simply assume that each product has 3 reviews. For each review, we have to make 1 additional request to fetch the author from the Accounts subgraph. So in total, we have to make 1 + 3 + 3 + 3 * 3 = 16 requests to resolve this query.
If you look closely, you can see that the number of requests grows exponentially with the depth of a Query, and the number of items in a list, where nested lists make the problem even worse, like in our example where each product has a list of reviews. What if each review had a list of comments, and each comment had a list of likes? You can see where this is going.
The DataLoader pattern is a common solution to solve the N+1 Problem in GraphQL. It's based on the idea of batching requests within lists to reduce the number of requests. What's great about GraphQL is that it allows us to batch requests by design. With REST APIs, you have to explicitly implement batch endpoints, but with GraphQL, you can easily combine multiple requests into a single request.
Furthermore, Federation makes batching even simpler because the well known _entities field to fetch "Entities" supports a list of representations as input. This means, fetching entities by their keys allows you to batch requests by default. All we need to do is to make sure that we actually batch requests within lists together to leverage this feature, which is exactly what the DataLoader pattern does. By using the DataLoader pattern, we can reduce the number of requests from 16 to 4, one request to load the topProducts, one to load the stock info, one to load the reviews, and one to load the authors.
Let's look at an example to illustrate how the DataLoader pattern works:
If we add the necessary key fields, those are the fields that are used to fetch entities by their keys, our GraphQL Query from above looks like this:
The first step is to fetch the topProducts from the Products subgraph. Here's how the Query looks like:
Let's assume the Products subgraph returns 3 products, this is how our response could look like:
We will now walk through all products and load the associated data for each product. Let's do this for the first product.
This is how our "input" looks like:
We now need to fetch the stock for this product from the Inventory subgraph.
While this query works, it doesn't allow us to batch together the two other sibling products. Let's change the query to allow for batching by using variables instead of embedding the representations directly into the query:
This Query will be exactly the same for all products. The only difference will be the value of the $representations variable. This allows us to implement a simplified version of the DataLoader pattern.
Here's how it can look like: It's a function that takes the Query and a list of representations as input. The function will then hash the Query, and combine all the representations for the same Query into a single request. If there are duplicate representations, we will deduplicate them before building the variables object. It will make a request for each unique Query and return the "unbatched" results to each caller.
Great! We've now implemented a simplified version of the DataLoader pattern and leveraged it to load the stock for each product. Let's now also load the reviews.
Run this through our load function and we've got reviews for each product. Let's assume each product has 3 reviews. This is how the response could look like:
We now need to fetch the author for this review from the Accounts subgraph.
Again, we do this for all siblings and batch together the requests for the same Query. Finally, we're done loading all the data and can render the JSON response according to the GraphQL specification and return it to the client.
At surface level, the DataLoader pattern seems like a great solution to solve the N+1 Problem. After all, it dramatically reduces the number of requests from 16 to 4, so how could it be bad?
There are two main problem with the DataLoader pattern.
First, it's making a trade-off between performance and code complexity. While we reduce the number of requests, we increase the complexity of our code quite a bit. While this is not visible in a single threaded environment like Node.js, multi-threaded environments like Go or Rust will have a hard time to use this pattern efficiently. I'll come back to this later.
Second, while the DataLoader pattern reduces the number of requests, it exponentially increases the concurrency of our code. With each layer of nesting, and each item in a list, we exponentially increase the number of concurrent requests that are being made to the "DataLoader".
This comes down to a fundamental flaw in the DataLoader pattern. In order to be able to batch together the requests of multiple sibling fields, all sibling fields have to "join" the batch at the same time. This means, we have to concurrently walk through all sibling fields and have them call the DataLoader load function at the same time. Once all sibling fields have joined that batch, they are blocked until the batch is resolved.
But this gets even worse with nested lists. For our root list, we have to branch out into 3 concurrent operations to load the data for all 3 products using the DataLoader pattern. So we've got a concurrency of 4 if we also count the root field. But as we're not only loading the stock info but also the reviews for each product, we have to add another 3 concurrent operations for each product. With that, we're at a concurrency of 7. But we're not done yet. As we discussed, we assume to get back 3 reviews for each product. To load the author for each review, we therefore need to branch out into 9 concurrent operations for each review. With that, we're at a concurrency of 16.
To illustrate this problem, here's a visualization from the talk. The numbers are slightly different but the problem remains the same.
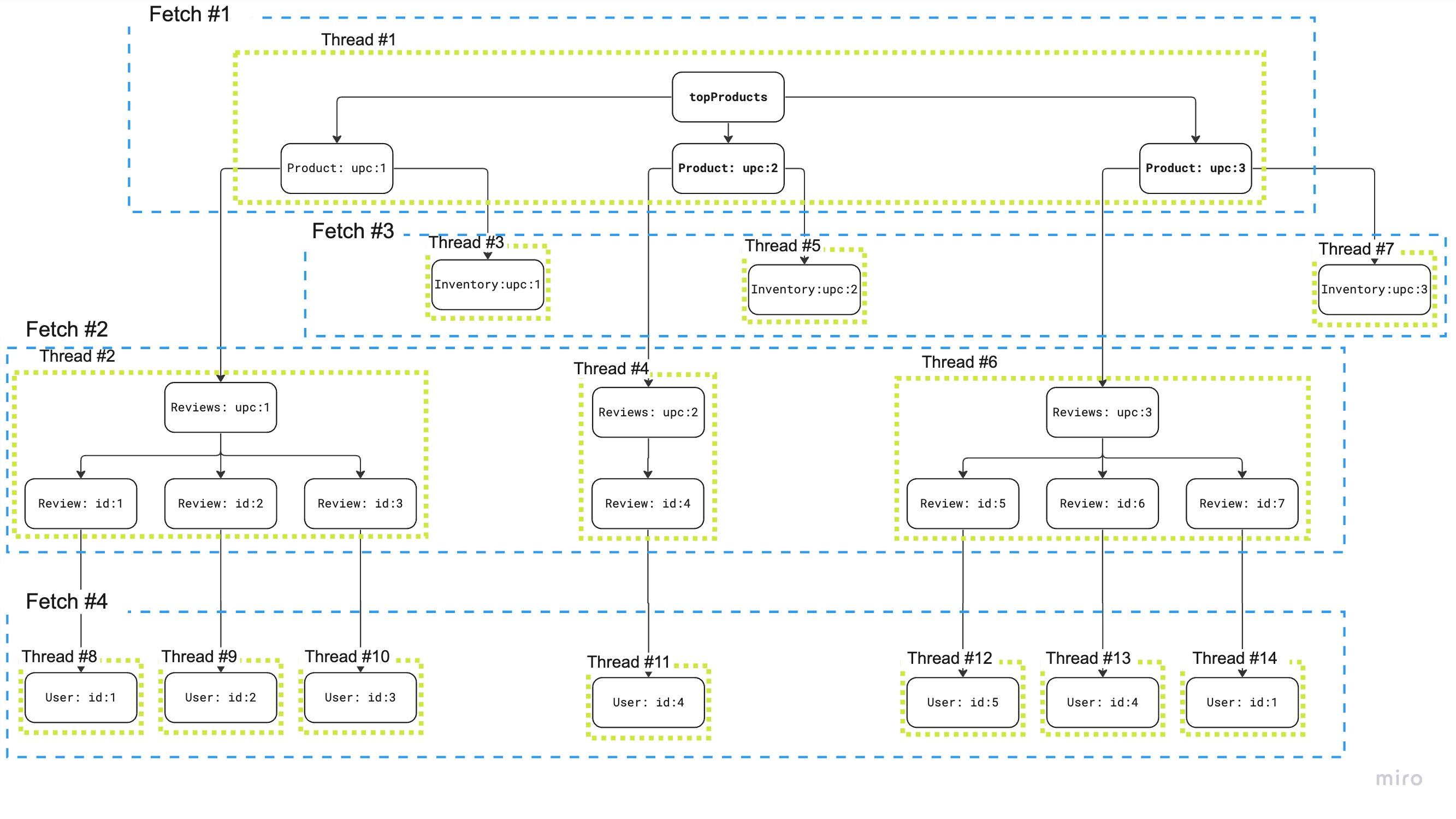
As you can see, batching relies on being able to concurrently call the load function for all sibling fields.
Like I mentioned before, there's not just the additional cost of concurrency, but for non-single threaded environments like Go, Rust, Java, etc., having to resolve sibling fields concurrently comes with another challenge.
Federation, but also other composite GraphQL styles allow you to define dependencies between fields. This means, you can define that a field @requires another field to be resolved before it can be resolved itself. E.g. you can have a user object that contains an id field. With the id field you can fetch the street and house number of the user. Once you have those two, you can fetch the full address of the user, which relies on the other two fields.
In the worst case scenario, the following could happen. You have a list of sibling user objects. For each of them you batch-load the street and house number. You do this concurrently. Once this is done, you have to merge the results with the original user objects. Next, you walk through each user object again, concurrently, and batch-load the full address.
By adding concurrency to this operation, we have to synchronize the results, we need to make sure that we're not concurrently reading and writing the same objects, or we have to copy all the objects when we branch out into concurrent operations, and then ensure that once we merge the results, we're not concurrently writing to the same objects.
Either way, we might have to copy a lot of objects, we might have to synchronize concurrent operations, or even use locks and mutexes to ensure that we're not concurrently reading and writing the same objects. All of this might add not just complexity to our code, but can also have a negative impact on performance.
If you've got experience with heavily concurrent code, you might be aware that debugging concurrent code is hard. If the debugger jumps between threads, it's hard to follow the execution flow of your code. This is where printing to the console actually becomes a useful debugging tool again.
That being said, wouldn't it be great if we could get rid of all this concurrency? What if we could write simple synchronous code that's free of locks, mutexes, threads and other concurrency primitives? And that's exactly what we did!
Most if not all GraphQL servers resolve fields depth-first. This means, they resolve a field and all its subfields before they resolve the next sibling field. So, in a list of items, they exhaustively resolve one item after another. If we're talking about trees, they resolve the left outermost branch until they reach the leaf node, then they resolve the next branch, and so on, until they reach the right outermost branch.
This feels natural because it's how we would "print" a JSON into a buffer. You open the first curly brace, print the first field, open another curly brace to start an object, print the contents of the object, close the curly brace, and so on.
So how do we can get rid of the necessity to resolve sibling fields concurrently to enable batching? The solution is to split the resolver into two parts. First, we walk through the "Query Plan" breadth-first, load all the data we need from the subgraphs, and merge the results into a single JSON object. Second, we walk through the merged JSON object depth-first and print the response JSON into a buffer according to the GraphQL Query from the client.
As this might be a bit abstract, let's walk through an example step by step.
First, we load the topProducts from the Products subgraph, just like we did before. The response still looks like this:
Next, we walk "breadth-first" into the list of products. This gets us what we call "items", a list of objects.
We've now got a list of products, so we can load the stock info for all products at once. Let's recap the Query we need to load the stock info:
We can simply call this Operation with our list of items as input, excluding the name field of course. Other than that, you can see that we don't need the DataLoader pattern anymore. We don't need concurrency to batch together requests for sibling fields. All we do is to call the Inventory subgraph with a list of product representations as input.
The result to this operation is exactly the same as before:
Let's merge it with the items we've got from the Products subgraph:
The merge algorithm is pretty simple. Based on the position of the product in the list, we merge the stock info from the _entities response into the product object.
We repeat this process for the reviews. Let's assume we've got 3 reviews for each product. This would return an array of entities with 3 reviews each.
Let's do the same thing we did before and merge the reviews into each of the product items.
Very nice! We've fetched the products, stock info and reviews for each product. How do we now resolve the author field for each review?
The first step is to walk breadth-first into the list of reviews. Our "items" will then look like this:
It's just a list of reviews, great. Next, we walk into the authors, using breadth-first again, which brings us to a list of users.
We can now load the name field for all users at once, no concurrency, just a single request to the Accounts subgraph.
The result might look like this:
Let's merge it with the list of users:
Now all we have to do is walk "up" the tree and merge the resolved items into their parent objects. There's one important thing to note here. When we walk into a list of items within an item, we need to note which child indexes belong to which parent item. It's possible that we have lists of unequal length within a list of items, so we would screw up the order if we didn't keep track of the child indexes.
So if we walk up the tree and merge the users into the reviews, our items would look like this:
Nine reviews in total with the author info merged into each review. Finally, we walk up the tree one last time and merge the reviews into the products. Our resulting object will then look like this:
And that's it! We've now loaded all the data we need to render the final response JSON. As we might have loaded unnecessary data, like for example required fields, and we're not taking into consideration aliases, this is a required step to ensure that our response JSON has exactly the shape that the client requested.
This was a look at the algorithm from a very low altitude. Let's zoom out a bit and look at this algorithm from a higher level.
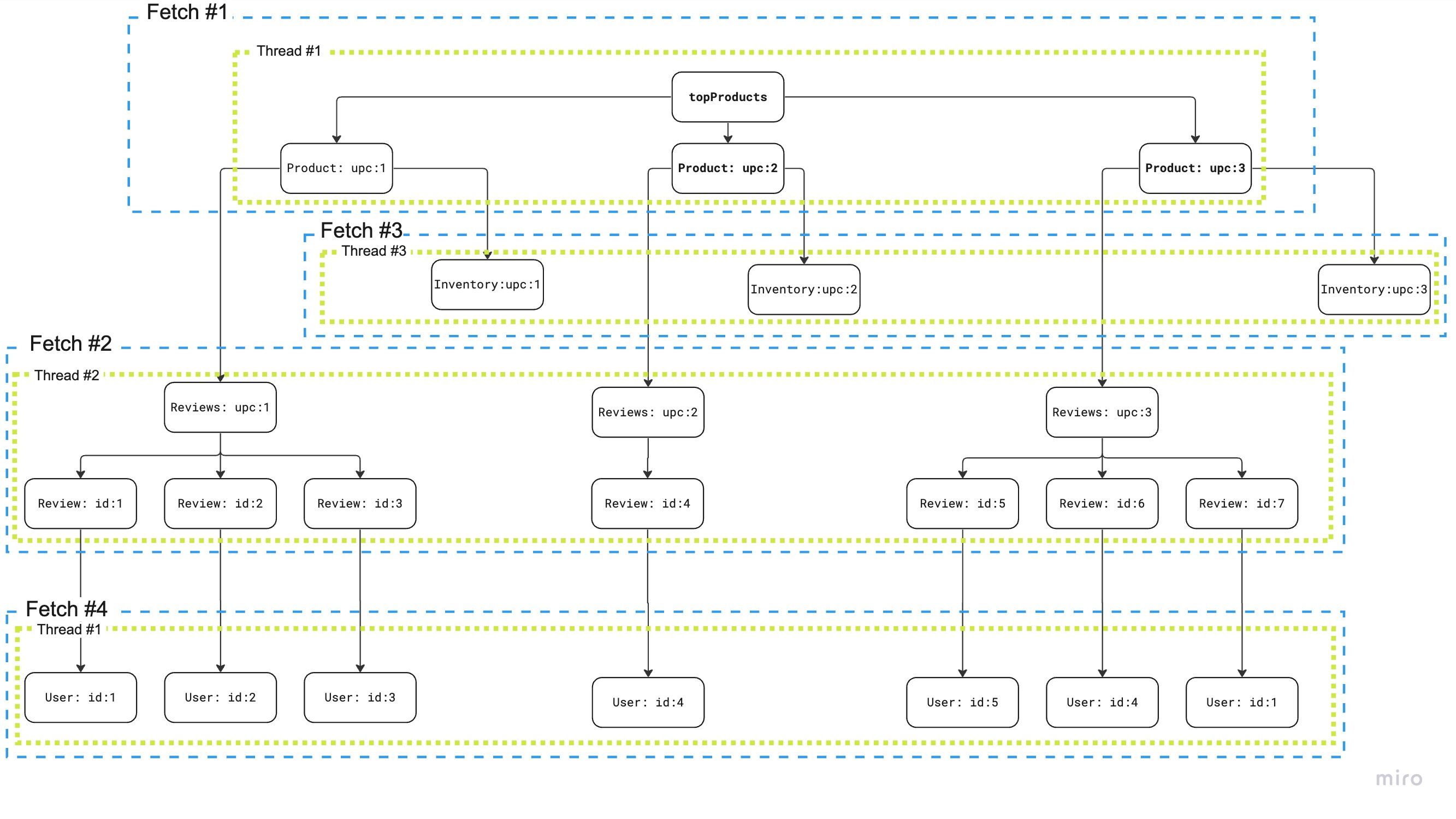
You'll notice two things in this visualization. It shows 3 threads instead of one. This is because we're parallelizing fetching the stock info and the reviews. This is possible because they are at the same level in the tree and only depend on the products. The second thing you'll notice is that other than the parallelization of the two above mentioned operations, we're not using any concurrency at all.
The key difference of resolving fields breadth-first instead of depth-first is that we can always automatically batch together requests for sibling fields, as we always have a list of items (siblings) instead of visiting each item (sibling) branch by branch (depth-first) concurrently.
Speaking of concurrency and parallelization, we've made another important observation regarding parallel fetches at the same level in the tree, like we did for the stock info and the reviews.
During our research, we've initially tried to parallelize the two batches and immediately merge the results into the items. This turned out to be a bad idea as it would require us to synchronize the merging, e.g. using a mutex. This made the code more complex and had negative impact on performance.
Instead, we found a better solution. When we render the inputs for each of the batches, we only read from the items, so it is safe to do this concurrently. Instead of immediately merging the results into the items, we pre-allocate one result set for each batch to temporarily store the results for each batch. We then wait for all parallelized batches to finish and merge the results from the result sets into the items in the main thread. This way, we don't have to synchronize at all and can go completely lock-free, although we're leveraging concurrency for fetching the batches.
Now that we've looked at the algorithm in detail, let's talk about the benefits of breadth-first data loading.
- We got rid of our DataLoader implementation
- We don't have concurrency except for concurrent fetches at the same level in the tree
- We don't have to synchronize concurrent operations
- We don't have to use locks or mutexes
We can easily debug our code again, and the whole implementation is a lot easier to understand and maintain. In fact, our initial implementation was not entirely complete, but we were able to quickly fix and extend it as the code was easy to reason about.
As a side effect, although this wasn't our primary goal, we've seen improvements in performance of up to 5x compared to our previous implementation using the DataLoader pattern. In fact, the performance gap increases with the number of items in lists and the level of nesting, which perfectly illustrates the problem with the DataLoader pattern.
The DataLoader pattern is a great solution to solve the N+1 Problem. It's a great solution to improve the N+1 Problem, but as we've seen, it has its limitations and can become a bottleneck.
As we're building a Router for federated GraphQL, it's crucial to keep our code maintainable and the performance overhead low. Being able to reduce the concurrency of our code is a huge benefit, especially when we're able to reduce the concurrency from O(N^2) to O(1).
So does this really just affect federated GraphQL Routers, or GraphQL Gateways, or even GraphQL servers in general?
I think we should all be aware of the trade-offs we're making when using the DataLoader pattern. There are frameworks like Grafast that take completely new approaches to resolving GraphQL Operations. It's a good time to question the status quo and see if we can take these learnings and apply them to our own GraphQL server and frameworks.
Should GraphQL frameworks consider implementing breadth-first data loading? Should you consider implementing batch-loading as a first class citizen in your GraphQL server? I don't know the answer, but I think it's right to ask these questions. I'd love to hear your thoughts on this topic.
Once again, the implementation is open source and available on GitHub .
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


