
7 Key Lessons I Learned While Building Backends-for-Frontends

Prithwish Nath
Editor's note: This post is about the BFF pattern and the lessons that hold up regardless of stack. If you're building GraphQL federation rather than a BFF, that's what Cosmo is for. SoundCloud, who pioneered the BFF pattern , now runs federation on Cosmo.
TL;DR
A backend-for-frontend (BFF) is a server-side API built for one specific client, not a shared gateway for all of them. Build one BFF per client experience, push caching, auth, and error normalization into the BFF layer, and lean on integration tests with mocked downstreams. Expect some code duplication across BFFs, and treat it as the price of team autonomy rather than a problem to solve. The pattern pays off when you support several client platforms with different needs. For GraphQL federation across many teams, a federation router like Cosmo is the better fit.

A Backend-for-Frontend (BFF) is a specialized server-side API that serves as an intermediary between the frontend (client-side) applications and various downstream APIs, aggregating and transforming data as needed before delivering it to the frontend.
Why build BFFs? They’re a façade — shielding your frontend from the complexities of dealing directly with diverse (and potentially inconsistent) data sources — making your frontend codebase more focused, more maintainable.
You’ve read Sam Newman’s famous blog post , and a bunch of other resources on BFFs, I’m sure, and while those give you a great idea on what the pattern is and why it’s useful, it’s not immediately obvious how best to build a BFF. Or the mistakes you’re likely to make along the way. For do’s and don’ts on implementation, see 5 best practices for Backends-for-Frontends.
So, without further ado, here are some gotchas, tips and tricks, and general developer advice about Backends-for-Frontends drawn from my firsthand experience in building them for data-heavy apps. The stuff I wish I’d known when I was just starting out.
Let’s dive right in. Hope these are useful!
I’ve found that it’s incredibly easy to play it safe and end up building an API gateway instead of a proper BFF.
API gateways are conceptually simple, and they’re fairly attractive. Put a HTTP-based abstraction in front of multiple downstream services, insulating the client(s) from changes when these downstream services change — easy, right? Not exactly.
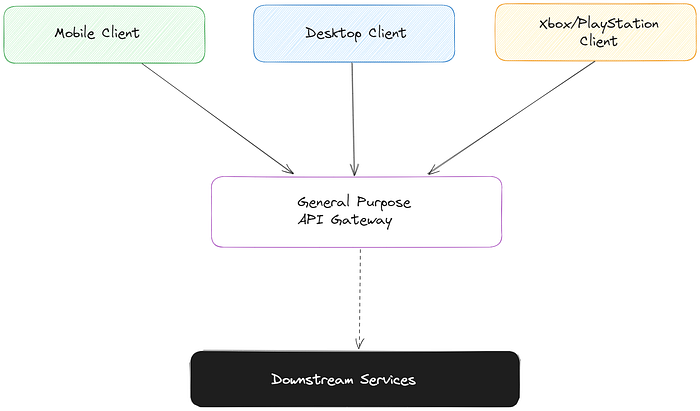
As your app grows, a pure API Gateway approach inevitably turns into an all-encompassing monolithic API for multiple clients and experiences, and any new feature (on any of your supported clients) will have to ensure compatibility with this one API before shipping anything at all. Plus, this is yet another giant responsibility — and one with muddy ownership to boot. Does the backend team work on this? Do you create a new team altogether? Either way, the frontend teams have to interface with this team every time they need to either consume or modify downstream APIs.
More friction, less fun.
Backends-for-Frontends differ from API gateways in being specifically built for one client/user experience, with one BFF per client/user experience.
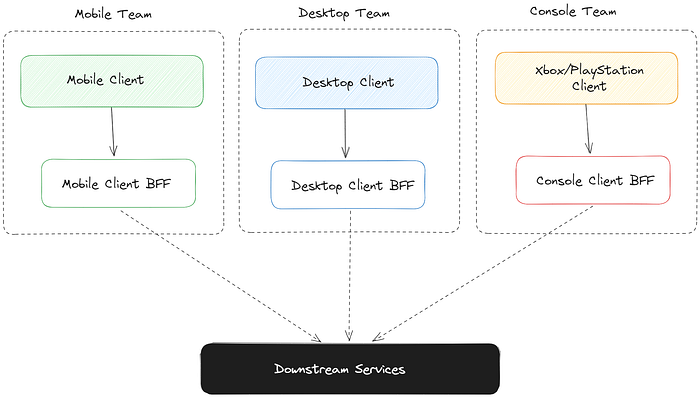
Does your product consist of a React desktop app, an Android/iOS app, and an app for Xbox/PlayStation? With the BFF pattern you won’t have three clients talking to one API gateway that takes on multiple responsibilities, but instead:
- One “backend” purpose built for each one of them, owned by each client team.
- Each being smaller and less complex than an API gateway, and easier to maintain because there is an inherent separation of concerns that this pattern promotes.
- Each doing exactly what the UI for its particular client needs — and nothing else.
The idea is simple: since you own both the client and the “server” components, you can always create the perfect “backend”, with a function that when called, returns exactly the data needed, in exactly the right format. One of these client + BFF teams doesn’t even have to worry about how downstream resources work.
Building production-ready BFFs requires you to reinvent the wheel for a bunch of parts — request routing and dispatching, API aggregation and orchestration, data transformation/formatting, middleware, caching, logging and error handling, security… and that’s not even considering the actual BFF API design.
There’s no established spec, or even a consensus among the community as to how you actually build and bring together all of these layers.
A BFF framework handles that boilerplate for you — config-as-code dependency composition, typed operations, caching, auth hooks, and testing utilities — so you can focus on the API your client actually needs.
The BFF layer is the perfect place to relieve some of the burden on both your client and your backend services, making their code much more simple. It’s usually a good idea to bring in ancillary concerns like caching, auth, and normalized error handling to the BFF.
Again, this comes back to a BFF having the benefit of knowing its client perfectly. Since we know exactly the data, auth techniques, and caching requirements/strategies we’ll need for a given client (and the format of it) we can offload these operations to the BFF.
A BFF knows the exact aggregations a client will need, so we can place a reverse proxy in front of the BFF to store a copy of the needed view-specific response in its cache, and serve it to subsequent clients who request the same aggregation. We could also produce data models/aggregates that are expensive operations, ahead of time.
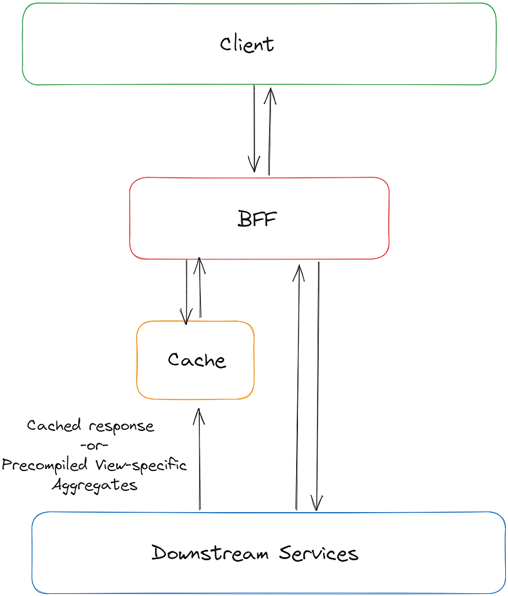
A common technique is to hash each BFF operation into a persisted query that only responds to requests carrying a valid hash, then generate an Entity Tag (ETag) for each response. Compare that ETag on each subsequent request — if it matches, nothing has changed and the client’s cached version is still valid. This opens up very fast stale-while-revalidate strategies on the client, without manually setting expiry times for each aggregation.
Auth often involves integrating with external identity providers, user directories, or Single Sign-On (SSO) systems. This is a functionality that is a perfect fit for the BFF layer for a bunch of reasons that go beyond just simplifying the frontend/backend codebases:
- Each client (or more accurately, user experience) may have unique authentication requirements. By implementing auth in the BFF, you can tailor authentication logic to match the specific needs/standards of each client. This allows for fine-grained, context-aware auth.
- It makes much more sense to have auth implemented in the BFF, than on yet another Nginx server further upstream that you’ll have to test, deploy, and maintain independently.
- Plus, having auth in a BFF is just another layer of security since a BFF inherently hides all backend architecture/implementation from the client.
- If your app needs to support auth using multiple credentials — classic username/password, external OAuth providers like Google/GitHub, 2FA/MFA, etc. — the BFF can integrate multiple identity providers, mapping it to a unified interface for your client.
- The BFF can also implement granular access control based on user roles — commonly known as Role Based Access Control (RBAC). RBAC implemented in the BFF simplifies the maintenance and updates of access control rules since the authorization logic resides in a centralized location.
The BFF essentially acts as a mediator of requests, and given the sheer volume of inbound and outbound traffic it handles, makes for an excellent place to implement logging. You’ll have centralized logging regardless of which client made the request.
Plus, since so much of the data handled by a BFF is aggregates, logging at this level can actually surface performance-related issues, helping out both frontend and backend devs.
But it’s more than just that. The real value added by logging in the BFF layer is context. BFFs possess valuable contextual information about each request. They can extract crucial details like the user’s identity, the type of frontend application used, the API endpoints accessed, and the parameters sent. You could actually enrich logs with this crucial context, making debugging orders of magnitude easier.
Finally, since the BFF serves as a security barrier between frontend and backend services, logging here would also allow the detection of potentially malicious patterns in incoming requests.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
BFFs are an aggregator of requests on the server layer, sending multiple requests to one or more downstream services, gathering all the responses asynchronously, stitching them together when it’s all ready, and sending them back to the client application.
But these downstream services can fail in wildly different ways, and they may return errors very differently, too. Some might throw a generic HTTP 500 (and you might not want that), some throw HTTP 200 OK but include error data in the body, and some don’t even return JSON at all but XML/HTML.
The BFF essentially being a translation layer between the frontend and domain services, is well equipped for translating and mapping these disparate errors/error messages — and critically, doing so with normalized error states.
Here’s an example. In a conventional REST API, a request that fails validation would get you back a 4xx or 5xx HTTP status code, but what if one of your domain services is a GraphQL API?
Let’s say this mutation request fails (obviously, because the input is missing a name).
But this will always get you a 200 status code regardless, with the response payload containing specific error information. If you pass on this responsibility to the client, the required error-handling logic (with proper UI/UX feedback) is going to make it bloated and harder to maintain.
This is where the BFF comes into play. The BFF can be responsible for handling the GraphQL response from the backend, and then normalizing any potential errors into a consistent format that the client application can interpret and display unambiguously.
You could now return this as an HTTP 400 Bad Request, with specific information about malformed syntax or missing required data. The BFF acts as the intermediary that normalizes your downstream error responses, providing its client with the necessary information to understand the outcome of its requests, and handling errors in a standardized manner.
And you could do much, much more with it — adding a canonical timeout period, for example. Or adding custom headers whenever necessary.
BFFs aggregate and orchestrate data from multiple downstream services, before passing on a final response to the client, so it’s obvious that it would be a great place to test and validate data against an agreed-upon API specification, and the format its client needs.
But it’s also a great place to test specific use cases that might be difficult to achieve with real backend data. For example, simulating error responses, edge cases, resource-constrained or degraded service scenarios. Relying solely on real backend data for testing can lead to bottlenecks and inconsistencies, so mocking that data in the BFF allows developers to proceed with testing even if the actual backend systems are not fully developed or accessible.
But mocking data can come in handy for more than just testing. It also means that you’re going to have a much faster time to market, as frontend teams won’t have to wait on a backend team to deliver the updated API they need. They could just mock the response during development.
The frontend and backend teams only have to agree on an API contract together, and if the domain services/business logic are not ready yet, the client teams can just mock out the data on their own BFF layer. A monolithic backend team serving the needs of competing frontend teams will never be the bottleneck.
As Sam Newman mentions in his seminal post about the BFF pattern, some duplication is inevitable with BFFs. The more BFFs (and user experiences) you have, the more overlap between their codebases — duplicated code for the aggregation if some user experiences are similar enough, duplicated code for interfacing with common downstream services, and duplicated code when some user experiences have a common auth or caching strategy, for example.
While our first instinct as developers would be to see this duplication as an opportunity to DRY things up , that inevitably leads us back to the inefficient, monolithic general-purpose HTTP abstraction again. So that’s a no.
But leaving in duplication might actually be advantageous. Once again, it boils down to agility and team autonomy. BFFs work best when they are purpose-built and tightly coupled to a user experience. If each client + BFF team has total control over their domain, they can ship faster, take more risks, and try out new things whenever they want, without having to consider the impact of their decisions on other teams.
If you were to merge back this duplication into an abstraction, this would no longer be the case. Multiple teams/apps would now depend on a shared service, and you would not be able to move fast because no matter who owned responsibility for the shared service/library now, they’d frequently have to work around other teams and come up with strategies for breaking changes, latency requirements, and more. You’d just have created another bottleneck.
That’s not to say you should never, ever create a shared service out of duplicated functionality — these could be opportunities for collaboration among teams that could lead to new features and improvements, or shared bugs being found and fixed much faster.
Like everything in software development: observe, understand the tradeoffs, and make an informed decision, rather than prematurely optimizing for abstractions just because that’s what you were taught in school.
A BFF is purpose-built for a specific client, and so each BFF will need detailed accompanying API documentation that covers all of the BFF’s available endpoints, their corresponding HTTP methods, the expected request and response payloads, aggregate/data models, error handling, input validation, and guidelines for usage.
Documentation needs to be a living resource, maintained and updated regularly as the BFF evolves. Any changes made to the BFF should be reflected promptly in the documentation. The only thing worse than no documentation is bad or outdated documentation, as that only leads to misunderstandings, inefficiencies, and show-stopping bugs.
If you don’t get ahead of documentation for a BFF, you’re going to move fast and break things, sure, until you only break things.
The points discussed here should help you design and build production-ready BFFs that meet the demands of modern web applications.
When should you build BFFs? The ideal scenario would be when you have to support multiple client platforms, each with unique needs and constraints. Adopting the BFF pattern could also solve organizational issues with communication, much like GraphQL could, except BFFs have the edge when shifting the data responsibility to the client isn’t an option (bundle size concerns, API consumers needing to learn a new paradigm, security issues, etc.)
A BFF framework can help with the boilerplate — shared types between client and server, server-side aggregation without bloating the client bundle — but the pattern itself is what matters most.
Frequently Asked Questions (FAQ)
A backend-for-frontend is a server-side API built for a single client or user experience. It sits between that client and the downstream services, aggregating and reshaping data into the exact format the client needs. You run one BFF per client rather than one shared API for all of them.
An API gateway is a single shared abstraction that sits in front of many services for every client. A BFF is scoped to one client experience and owned by that client's team. A gateway tends to grow into a monolithic API that every client must stay compatible with, while a BFF stays small and does only what its one client needs.
Build a BFF when you support multiple client platforms with different data and interaction needs, such as a web app, a mobile app, and a console app. It also helps when frontend and backend teams keep colliding over one shared API. If you only have a single client, a BFF usually adds more overhead than it removes.
Caching, authentication, and error normalization are a good fit for the BFF because it knows its client's exact needs. The BFF can cache view-specific responses, integrate multiple identity providers behind one interface, and turn inconsistent downstream errors into a single consistent format the client can handle.
Yes, and that is usually fine. Multiple BFFs will share some aggregation, auth, and caching logic. Merging that back into a shared service recreates the monolithic gateway you were trying to avoid and slows every team down. Some duplication is the price of team autonomy and faster shipping.
No. A BFF is a per-client API layer. GraphQL federation composes many backend subgraphs into one graph served through a router, which suits large organizations with many teams. If that is your situation, a federation router like Cosmo fits better than hand-built BFFs.


