
WunderGraph - The Next-Gen API Developer Platform - is Open Source!


Archive Notice
This article is archived and no longer maintained. It announces the open-sourcing of an earlier version of WunderGraph, which is no longer part of the current product. The product details may not reflect the current platform. For current documentation and guidance, see https://wundergraph.com/cosmo
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
It's lift off! Today, we're proud to announce that WunderGraph is now Open Source. We've decided to release it using the Apache 2.0 license and build a great community around the API Developer Toolkit.
Our goal is to build the best possible Developer Experience for working with APIs. We believe that this is only possible if we do it together with the community. If you want to build a successful Dev-Tools business today, you have to be open source and local first. At the same time, you need a sustainable business model, you'll see in the Roadmap section that we've got some great ideas.
It's important to find the sweet spot between open source and SaaS, so that your SaaS doesn't interfere with the open source interests. I'll explain in the Roadmap section why I believe, we're on a great path of getting this right.
If you're just here to check out the repo, that's fine. Have a look at our Monorepo and don't forget to check out the examples . If you'd like to learn a bit about the history of WunderGraph and why we've built it the way we did, you're invited to read on.
I love Monolithic Full-Stack Frameworks. If you want to call a "Service", all you have to do is import a module and call a function. From Authentication to Authorization and File Uploads, everything is handled by the framework, so the Developer doesn't have to think about the "how" and can focus on the "what".
That said, I've never actually worked in a project where a single monolith lived in happy isolation. There are usually dependencies on other systems, and companies tend to decompose Monoliths into smaller services to grow their teams.
WunderGraph allows you to treat a set of distributed services like a Monolith.
That's where WunderGraph comes into play. It's a Framework that allows you to program against multiple services, databases, file storages, etc... as if they were a monolith!
If you treat APIs like Dependencies, Magic happens!
The problem with APIs in distributed systems is that we usually treat APIs like abstract things. What's the most common way to integrate a third party API? You copy a URL from their docs, put an API key into the ENV and make a fetch to their API Endpoint. This might work for 3 Endpoints, but gets messy with hundreds of them.
WunderGraph: API Gateway, Backend For Frontend Framework, Package Manager for APIs.
It might sound ambiguous, but that's because WunderGraph creates its own category.
While building WunderGraph, we realized that there are many ways to describe it, depending on how you look at it.
Here are a few ways to think about WunderGraph:
- It shares a lot of similarities with API Gateways
- It's a framework to rapidly build BFFs (Backends for Frontends)
- It's an API Integration Framework
The one I love the most is "WunderGraph is a Package Manager for APIs". Install and manage API Dependencies, just like npm packages.
Together with WunderHub , team A can "publish" their Products Microservice into the hub, allowing team B to "import" the service and treat it like a module, just like in a Monolith.
That's how we envision API collaboration. To start this off, an open source Framework lays the foundation, but that's really just the beginning. Our backlog is full of crazy ideas.
Enough talk, show me the code!
If you look at the WunderGraph Monorepo , you'll see that we mainly use two languages: Golang and TypeScript
Golang is pragmatic and fast. We use it to implement the Backend/Engine/Gateway of WunderGraph.
TypeScript is our language of choice for the SDK, custom extensions, hooks, etc...
You don't need a SaaS or any external Services to run WunderGraph. It's "local-first" Framework.
While a lot of Serverless frameworks try to emulate their environment on localhost, our focus is always to build a great Developer Experience on you local machine.
You'll probably want to get an idea of how it looks like to use WunderGraph, so let's do a quick Speed-Run.
A new project can be started by using this command:
From there on, it's basically three steps to build your first application.
- Add your API dependencies and configure your API
Everything in WunderGraph is configured using TypeScript. We believe that Configuration as Code has many benefits over user interfaces.
- can be stored in git
- automatically versioned
- integrates easily with CI / CD
- autocompletion
- you don't have to leave your IDE
Now, let's configure our WunderGraph application:
If we now run this application, all listed services get introspected, and we're ready for step 2, defining our first API Operation.
One thing you might have noticed is that we're assigning an "apiNamespace" to each of the APIs. That's like giving each module a name, as you don't want to have naming collisions between modules.
- Define an Operation
We've adopted a pattern from NextJS: File-based Routing. Each file inside the .wundergraph/operations directory is turned into an API Endpoint.
As we've introspected the Database and APIs in the previous step, our IDE helps us with autocompletion to write GraphQL Operations.
The Code generation will pick up this file-change and generate a TypeSafe NextJS client for us. This client handles calling our generated API, authentication and file-uploads.
- Using the generated API
By defining a GraphQL Operation, we've created a JSON-RPC Endpoint with JSON-Schema input validation.
In addition with the NextJS Integration, we're getting a fully TypeSafe client generated that makes it easy to manage the login flows and call our API.
That's it, Speed-Run done. Obviously, we've skipped a lot of topics, like adding custom business logic using hooks, injecting Auth tokens into origin requests, adding mTLS, etc. There are many ways to expand from here...
If you're looking for inspiration on what to build, here are a few pointers:
- Simple Example
- PostgreSQL Example
- PostgreSQL, NextJS, Prisma Example
- WunderGraph Demo with Apollo Federation
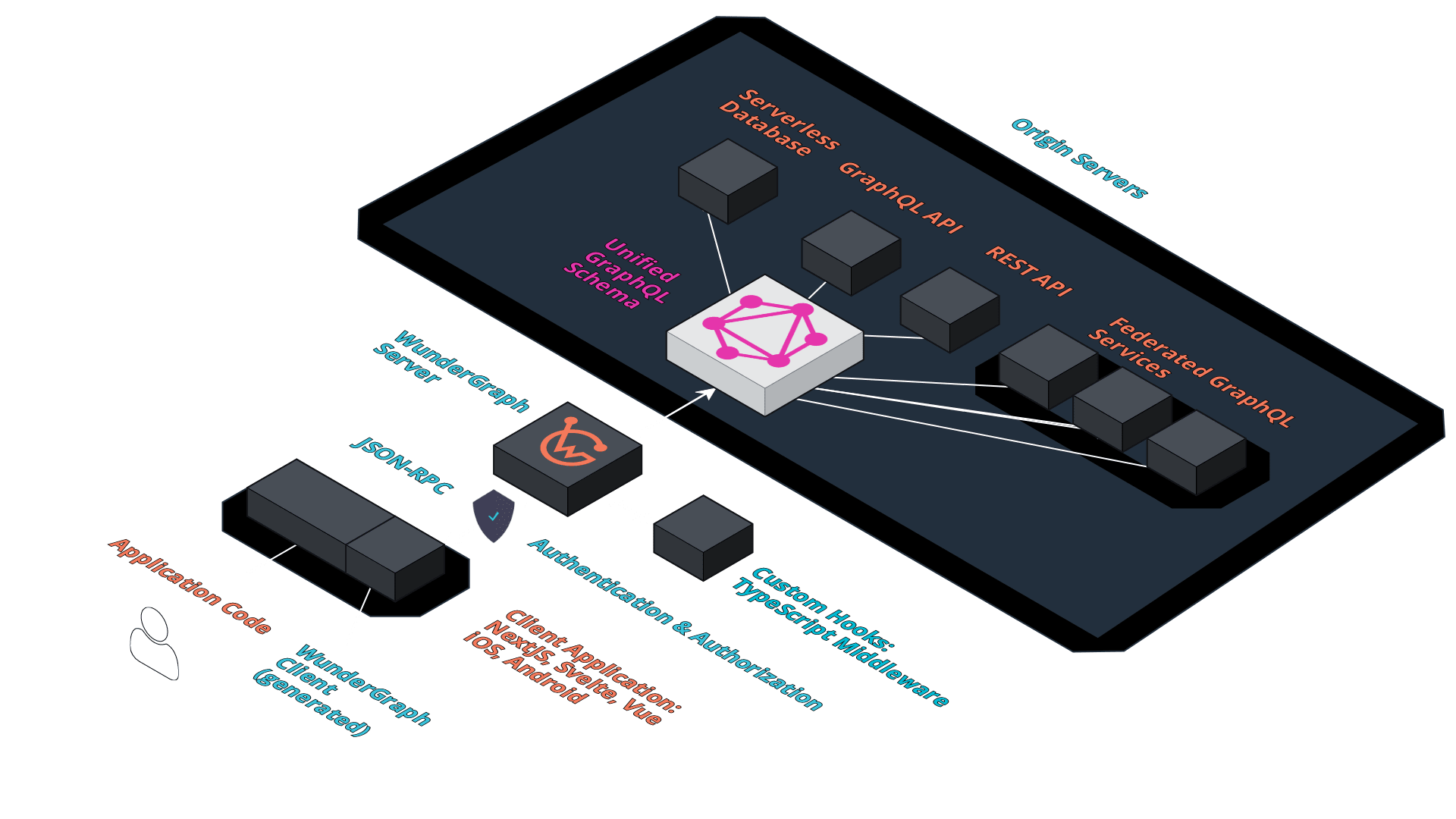
Let's talk a bit about the inner workings of WunderGraph. As we've seen by the example, we're introspecting the API Dependencies and configuring the Gateway using TypeScript. Running the configuration file will produce a config file (JSON). This config file is then picked up by the WunderGraph Server / WunderNode / Gateway.
For each GraphQL Operation defined in the .wundergraph/operations directory, the WunderNode will create a JSON-RPC Endpoint. This JSON-RPC Endpoint is protected with multiple middlewares, like JSON Schema input Validation, Authentication and Authorization, Caching etc...
Once all pre-execution Middleware is passed, the actual GraphQL Operation gets executed.
However, that's not really what's happening. Instead, we're executing a "compiled" Version of the GraphQL Operation. WunderGraph compiles all GraphQL Operations into efficient code on deployment time, so there's no real overhead of GraphQL at runtime. All expensive steps, like Validation, Normalization, etc. happen during development, not in production.
If you've configured one or more Identity Providers, the Gateway will also act as a OpenID Connect Relying Party, making it easy for web, mobile and cli applications to login your users.
The biggest difference from other GraphQL Frameworks and tools is that WunderGraph doesn't expose GraphQL in production. Doing so means that clients are allowed to send any Query to the server they want. This opens up a large attack surface and can lead to unpredictable performance.
We've found that most Applications never change their GraphQL Operations once they've been deployed to production. So, if you're not changing Operations in production, why not lock down the API?
That's exactly what we're doing, as we've put a JSON-RPC API in front of the GraphQL Layer to protect it.
Next, let's have a look at the WunderGraph Architecture, as we'd like to explain some of our decisions.
We've taken an early bet on GraphQL a few years ago as we believed that it's going to be the "Language for API Integrations", a bet which I think is starting to pay off.
Have a look at the following Query:
GraphQL offers such an elegant way of querying and joining data from multiple disparate DataSources. As you might guess, behind the scenes, the underlying Schema was generated from a REST API. The Query is 100% valid GraphQL, no need for custom tooling.
You could now say that the Query above is not clean, and you're right! We should have designed a proper schema for this use case, our GraphQL Schema should not behave like a REST API.
The reality though is that we'll never be able to translate all non-GraphQL APIs to GraphQL. We will never have pure, clean, GraphQL APIs. We will always have to deal with heterogeneous systems if we look beyond the boundaries of a single domain.
This means, we need a way of joining data between services. GraphQL is a great language to do this.
As we've discussed earlier, WunderGraph doesn't expose GraphQL, we're exposing JSON-RPC.
We're doing so for security reasons primarily, but realized that it also comes with a few nice extra benefits. Not having to parse, validate, etc. GraphQL at runtime allows the WunderGraph server to be very fast. We're removing GraphQL from the runtime entirely. All we do is execute a "tree of instructions" to generate a JSON Response.
Not exposing the GraphQL Layer to the client led to another very powerful feature we didn't plan to have. If a client cannot create or modify GraphQL Operations, we're safe to add some logic to the Operations which we would usually never expose to a client.
One such feature makes it possible to "inject" claims into the Variables definition. Here's an example:
Claims are name value pairs of information about the currently logged-in user. WunderGraph gets this information at the end of the login flow. By using the @fromClaim directive, we disallow the user to set the variable values, require them to be authenticated, and automatically set the variable value to their claim value.
This gives us a clean and easy way to implement Authentication and Authorization
In the GraphQL Ecosystem, there exists the concept of "Persisted Queries" and "Automatic Persisted Queries" (APQ). The correct term should be "Persisted Operations" actually, but let's move on.
Persisting a GraphQL Operation on the server is very much like a "Prepared Statement" on your Database. You register a function that takes an input and responds with a specific output.
Some GraphQL frameworks offer this out of the box, but it's more like an implicit feature.
We've decided to make this an explicit functionality. If you think about it, it's kind of obvious.
You register a function on the server that takes a JSON as the input (variables can be represented as JSON), and returns a JSON as the output.
If you parse and analyze a GraphQL Query, you're able to generate a JSON Schema for both the inputs and the response. This is very helpful because it allows us to generate a JSON Schema Validation middleware for the inputs. Additionally, we're able to feed the JSON Schema into a code-generator to generate a TypeSafe API Client.
For us, it was a very obvious choice to use JSON-RPC to expose the API generated from your Operations.
When building Single Page Applications or mobile Apps, you'll realize that it's a problem from a security point of view, if your client is a pure "client-side" client.
E.g. if your client needs to handle an authentication flow, you'd want to not expose your client credentials to the browser. A pure "client-only" client is not able to do this, so flows using PKCE were invented, but it's still not ideal.
We've found that there's a much simpler way of solving this problem: Hybrid Clients
If you spread the client between a Backend for Frontend (BFF) and the frontend, you're able to keep secrets on the server-side part, as well as handle the auth flow on the backend instead on the Frontend.
We can then establish a secure contract between BFF and Frontend, with secure, encrypted cookies. If you'd like to learn more about this topic, the pattern is called "Token Handler".
Serverless doesn't mean that there's no server anymore. The idea is that you don't have to think about running and scaling servers.
The same pattern can be applied to API Gateways. If you look at the architecture diagram, you'll see that there's the "WunderGraph Server / WunderNode" which acts as an API Gateway. But so far, we've never talked much about API Gateways.
We believe that API Management done right completely abstracts away the complexity of the API Gateway, hence the name "Gateway-less".
If you look at other API Developer Tools, they usually start by saying "Let's deploy a Gateway and a Control Plane, and a Dashboard, and a Database for Analytics...".
That's tooling made for Ops people, not Developers. We need API Gateways, but without all this complexity.
With WunderGraph, you should be able to configure your API using a few lines of TypeScript. Then git push to a repository and your app should be in production.
Everything in WunderGraph can be configured using Code. We've found that it's almost impossible to build great UX for configuring API Endpoints, Type Mappings, Custom Middleware, etc., so we didn't even try.
Instead, we've built an amazing TypeScript SDK that allows you to do all the aforementioned tasks.
Once you're done configuring your APIs, you can commit your changes to a git repository and deploy it to your environment of choice via continuous deployment. You'll get versioning for free and can easily roll back changes, try all of this with a user interface.
Another benefit is that you don't have to leave your IDE. You can configure everything in one place.
Imagine you're done with your backend and frontend, but you'd now have to log into a web gui to configure your API Gateway. How do you keep your web gui and the codebase in sync? And why don't we just automate this step? Or completely remove the UI?
Our approach to configuration is Infrastructure as Code, using TypeScript. This means that all Configuration is TypeSafe, hooks need to be configured in a TypeSafe way, custom business logic is TypeSafe, the generated clients are also TypeSafe.
You don't have to guess Types, ever. That's the only Developer Experience that we'd accept ourselves.
Let's now look at some features of WunderGraph.
The GraphQL engine powering WunderGraph is written in Golang . It's used in production by various companies for multiple years now.
At the core of graphql-go-tools is a Query Planner and Execution Engine which allows us to implement any resolver logic. So far, we've implemented DataSources for REST APIs (OpenAPI), GraphQL, Apollo Federation, Databases like PostgreSQL, MySQL, SQLite, SQLServer, MongoDB and more, with Kafka and AsyncAPI coming soon.
Adding a new DataSource is a matter of implementing some interfaces in Go, the heavy lifting is done by the Planner & Execution Framework. It's very abstract and flexible, so we're able to implement any possible datasource.
Additionally, we're able to support any model for Schema Composition. Schema Stitching, Federation, etc..., the sky is the limit.
One feature you've seen in one of the earlier examples is API Namespacing:
If you're introspecting two or more services and want to "automatically" combine them into a single, unified, GraphQL Schema, it's very likely that you'll run into naming collisions.
By introducing API Namespacing, schema composition will never lead to naming collisions, so it can be fully automated.
It's an important feature to enable the "Package Manager for APIs" . Imagine you'd have to rename some types and fields, everytime you're adding a new API to your application. That's not a great Developer Experience.
This is probably one of the coolest features. With a single Query, you're able to join data from multiple DataSources. API composition can be so easy:
Want to only allow an Operation for users of type "superadmin"? Add a directive to the Operation Definition, and you're done.
Sometimes, the default behaviour of WunderGraph is not enough, so you might want to customize it. For that purpose, we've added "Hooks", allowing you to extend your WunderGraph Server using TypeScript.
In this example, we're injecting the user_id into the inputs of an Operation. If you try out this feature, you'll realize that everything is 100% TypeSafe, making it super easy to write hooks.
Additionally, you don't have to manually deploy Hooks as a separate service, they just work by running wunderctl up.
With Hooks, you can customize a lot, have a look at the reference if you'd like to learn more.
A lot of people believe that WunderGraph is a big project/company/team. In reality, for the last few years, WunderGraph was just me, and I didn't even do it full-time.
WunderGraph was my personal side-project for multiple years. As a father of two kids (0.8 and 2.8yo) I wasn't able to take on more risk, so I've had to slowly move it to the point where the Framework was production ready.
I initially thought, if I build something great, people will immediately come and use it. However, the world is noisy, and it was hard to notice WunderGraph.
So I've focused less on adding features, and more on writing about WunderGraph, GraphQL, APIs and such on this blog. This brought WunderGraph a lot more attention, but also meant that I had to leave my Job.
Fortunately, almost at the same time I was able to build a small team around me, we were able to acquire first customers as well as getting the financial security so that we can work full time on this project and even hire a few people in the future.
We're getting compared to companies with hundreds of millions of funding, while on our end, we've never put in a single dollar for development or marketing.
It's incredible what you can achieve if you've got a clear vision of the future. At the same time, it's a struggle to build all of this on the side, with all the other duties, while trying to also be a husband and father.
It's a relief that we can now focus 100% on this project and dedicate our full energy to it.
I'd like to thank a few people who helped me carry the torch when I wasn't able to, or built a bridge when I needed one. Some of you gave me valuable feedback, without others, WunderGraph would have never been possible:
Ahmet Soormally, Martin Buhr, Guido Curcio, Xun Wilson, Keith O' Looney, Karl Baumgarten, Mikael Morvan, Mike Görlich, Alaa Zorkane, Thomas Witt, Sedky, Patric Vormstein, Jack Herrington, Hervé Verdavaine, Kyle Chamberlain, Itamar Perez.I also want to thank everyone on our Discord Community for testing and trying WunderGraph in the early days, providing valuable feedback, and even building on top of WunderGraph.
It brings joy to us when we see that people from the community take WunderGraph and adopt it for SolidJS or even Svelte . Thank you Hervé and Kyle, you're awesome!
As a side note, it's now a lot easier to add your own client generation/implementation to WunderGraph! Have a look at the NextJS client implementation for inspiration. If you're interested, you can contribute your own client to the monorepo.
Open Sourcing the Framework is just the first of many steps on our roadmap. For the future, we're going to use a similar Playbook as Vercel & NextJS.
Before NextJS existed, I was constantly figuring out a better way of doing React, searching a better Starter-Kit and kept updating my Dependencies.
APIs are at the same stage as React pre-NextJS. We're in constant search of better ways to build and deploy APIs.
What's missing is a Framework with the right level of abstraction, combined with a Serverless Hosting solution.
WunderGraph is the Framework, our Gateway-less Cloud offering will be the missing piece.
Git push your changes, and WunderGraph will automatically deploy your APIs, just like Vercel is deploying your Frontend.
The perfect API Developer Experience is when you don't have to worry about API Gateways anymore, Gateway-less API Management is the future.
You shouldn't be configuring a region. Our primary region will be "Earth", with Edge Caching and Custom Middleware, as close to your users as possible.
But most importantly, WunderGraph Cloud will be zero-ops. Git push, done.
The next phase will enable a new way of API Collaboration. We've talked about this before, WunderHub allows you to treat APIs like Dependencies.
In the second phase, we'll enable the true "API Package Manager". Sharing an API with your team, company, or the public will be as easy as "npm publish". API Key and Access Management will be automatically handled.
Imagine a world where you can build apps on top of 3rd party APIs, just by "installing" a bunch of APIs, deployed on Serverless infrastructure, in just a few minutes. We're building it!
Imagine a world where an API consumer can open an Issue on WunderHub to ask for a new feature. Once implemented, they get notified, update their API dependencies and can deploy the new functionality.
We want to enable a world of true API Collaboration. That's our purpose. GitHub changed the way we develop software. We're here to shape the world of API Collaboration.
One initiative worth mentioning here is the GraphQL Composite Schemas Working Group , created by Benjie, the maintainer of PostGraphile/Graphile.
We're a strong believer that GraphQL is a great match to combine, stitch, merge and compose APIs from different DataSources. Having a common spec will help the ecosystem evolve in this direction even further. GraphQL started as a tool to improve Data Fetching, and is now evolving into an API Integration solution.
GraphQL is becoming the Standard for Integrating APIs
We're a big supporter of Benjie's initiative. Once this turns into a great specification, we'd be more than happy to contribute an Open Source Gateway implementation and add it to graphql-go-tools , the Query Planner and Execution Engine backing WunderGraph.
If you want to go fast, go alone. If you want to go far, go together.
WunderGraph would have never been possible if I was on my own all along. Building a startup requires a lot of different skills. It's not enough to be able to build a great tool, you also need the competencies to market your product and build a network, hire the right people and build a business around it.
Being an introvert, networking is not my strength. That's why I'm glad to have Stefan on the team, he's responsible for growth, marketing, partnerships, etc...
Stefan was the first to join the team. He believed in the vision when nobody else did. Since he joined, traffic on our blog is skyrocketing, and we're building partnerships with companies in the billions of market cap.
I found Stefan via YC Co-Founder Matching, a free service from YC, can definitely recommend! It's not just great for finding a Co-Founder but also expanding your network.
On the engineering side of things, we were able to bring in Dustin. I found Dustin at exactly the right time through his Open Source projects on GitHub. Just to name a few, he's built a GraphQL Schema Registry as well as an Open Source GraphQL CDN on top of Cloudflare workers, insert Magic meme.
What I love about Dustin is his relentless care about quality and automation. He created a fantastic Monorepo, fully automated with automated deployments. The WunderGraph SDK is now in a state that I could have never achieved on my own.
I can highly recommend that you create Open Source Software and publish it on GitHub. It's the best way to accelerate your career!
Finally, we're joined by Björn, our COO. Björn brings a lot of C-Level experience to the table, he's going to focus on building the company, financials, legal, HR, etc. so that I can focus 100% on product, engineering, marketing and sales.
I knew Björn for many years and always wanted to work with him together (again).
Together, we're the perfect match to get this from zero to one. I'm glad I was able to bring all of you together and am always impressed by how committed everyone is.
If you're as excited about APIs and API Collaboration as we are, we'd be more than happy to hear from you!
Join our Discord and shoot a message.
If you'd like to join us, here's how you can get on board. We don't have a regular application process, yet. We only want to hire truly committed people who share our beliefs.
This means, you cannot directly apply for a job at this time. We'll get in touch with you if we believe you're a great match.
The best way to get our attention is by being active on our discord, and by contributing to our Open Source project . You can also build Examples and share them with the community.
Doing so helps us to get to know you, and you get to know us. Collaborating on Open Source is a great way of building a relationship. It gives both parties a chance to see if we want to work together.
If you'd like to get updates on open roles, make sure to follow our WunderGraph Twitter Account .
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


