
Refactoring Monoliths to Microservices with the BFF and Strangler Patterns

Prithwish Nath
Archive Notice
This article is archived and no longer maintained. It describes an earlier approach using WunderGraph as a Backend-for-Frontend layer to support monolith to microservices migrations. The architecture, APIs, and implementation details may not reflect current best practices or the current WunderGraph product. For current documentation and guidance, see WunderGraph Cosmo
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
How do you effectively migrate away from monoliths without getting stuck in Adapter Hell? Let’s talk about the synergy between BFFs and the Strangler pattern, featuring WunderGraph.
The idea of having loosely-coupled services as the primitive building blocks of a system — as opposed to monolithic development — isn’t exactly a hot take. Microservices offer modularity, independent scalability, and the ability to change, fix, and adopt new things as and when needed.
The problem, of course, is the word developers universally hate — a rewrite. Monoliths can contain years worth of accumulated code. How do you even begin to untangle the patchwork of bug fixes, legacy workarounds, intricately woven dependencies, and duplicated code that probably doesn’t belong?
Full, painful, lengthy rewrites done in one go have too much potential for both financial and strategic mistakes that can sink your company (see: Netscape 6). You need something that can help you migrate from monolithic architectures to microservices in a slightly less disastrous way.
So what’s to be done? Let’s talk about the combined power of two strategies: the Backend for Frontend (BFF) and the Strangler pattern, the formidable synergy that exists between the two, and then build and migrate a full-stack app from a monolithic to a microservices-based backend using the combination.
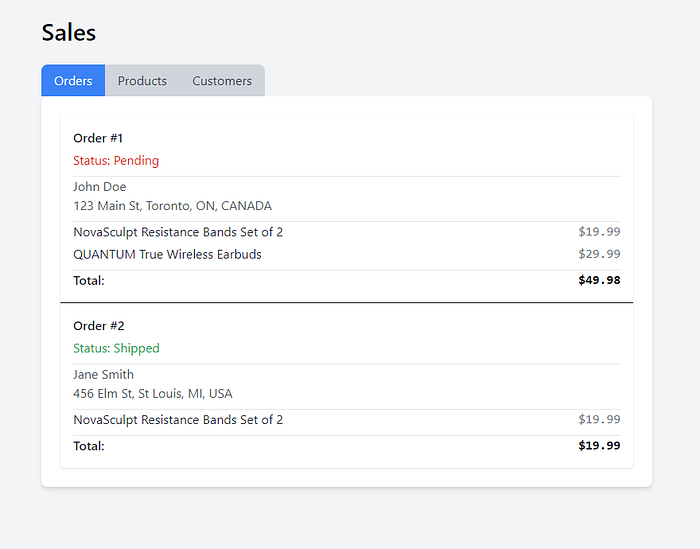
The app we’ll build and migrate to demonstrate this combination.
[the huge strangler figs that] grow into fantastic and beautiful shapes, meanwhile strangling and killing the tree that was their host.
- Martin Fowler, The Strangler Application
Basically, you throw an intermediary interface/proxy in front of the old monolith. While it starts out as a pass-through for incoming requests to the monolith, over time this new interface would route all of the old monolith’s functionality to new microservices, as they are implemented, one at a time. It would grow around the old monolith — “strangling” the older architecture — which you can then safely decommission, having moved over entirely to the microservices.
The idea is incremental adoption. You reduce the risks inherent with a ‘Big Bang’ rewrite, retaining the possibility to deliver new features while refactoring the older monolith. You have a new system in production right off the bat — even if it’s just a proxy initially — and with incremental development you get feedback ASAP, and can course correct accordingly.
But that’s still not an optimal solution, I’d say. Any such rewrite would always need considerable rewiring to go along with it. The issue is twofold, actually:
- Even with the perfect starting point — a modular monolith, with clearly defined boundaries between its components (read here) — each and every single chunk/component of the old monolith you “strangle” in favor of a fancy new microservice will first need a communication bridge built between the old and new systems.
- Obviously, you’d also have to redirect frontend calls from the old monolith to the new microservices — each and every single occurrence of this in client code — and then stitch together the response.
In a real-world scenario, an app of this scale would have dozens — even hundreds — of such rewiring.
Welcome to Adapter Hell.
Turns out, the two issues we’ve just talked about are exactly the things the Backends-for-Frontends (BFF) pattern can solve.
In the BFF pattern — first popularized by SoundCloud, and detailed by Sam Newman in this blog post — separate backend services are created for different frontend clients (or user experiences) to cater to their specific needs. Each backend service is tailor made for a specific frontend, encapsulating client-specific logic, and optimizing data aggregation, performance, and security for that specific client, while enabling independent development and scaling.
With the BFF server being the only ‘backend’ as far as your client is concerned, you hide the real backend completely from the client. Your client apps are no longer making direct calls to downstream services. It is their much faster dedicated server layer (the BFF) which is doing so to fetch, aggregate, and cache data needed by the client.
You can see where I’m going with this.
This means you’d be free to use the Strangler pattern on your monolith, extracting out functionality to the new microservice incrementally — while a BFF server is your Strangler’s proxy. No exhausting changes, rerouting, or adapters will ever be needed for your frontend.
The BFF layer would call either the microservice or the monolith to get the data the client needs, while the latter remains blissfully unaware of the changes going on behind the scenes. This would go on until, eventually, all data is obtained via calls to microservices, and then the monolith can safely be decommissioned.
Let’s take a look at an example migration to demonstrate this. We’ll be using WunderGraph — a BFF framework , to consolidate our data dependencies (initially, the public API offered by our monolith, and then, when that monolith is broken out into three microservices) into an unified API that we can query and mutate using GraphQL or TypeScript operations.
We’ll start with a monolithic API, set up a BFF server for our NextJS client that uses it, and then migrate that monolith to microservices without a single change in our NextJS app. Our BFF will absorb the changes, shielding the client from underlying changes completely.
So this is our API, a service that provides product, customer, and order information. Let’s stick to serving static data for the purposes of this guide.
Pretty self explanatory. Next, let’s create an OpenAPI spec for this. There are tools that can automate this for you, but if you’d like to skip ahead, here’s mine . It’s far too verbose to be included within the article itself.
💡 An OpenAPI/Swagger specification is a human-readable description of your RESTful API. This is just a JSON or YAML file describing the servers an API uses, its authentication methods, what each endpoint does, the format for the params/request body each needs, and the schema for the response each returns.
Our API here is a data dependency — WunderGraph works by introspecting these (by reading their OpenAPI specs), and consolidating them all into a single, unified virtual graph, that you can then define operations on, and serve the results via JSON-over-RPC. Now that your backend is up and running, let’s create a BFF server with WunderGraph, and set up a NextJS frontend too, while we’re at it.
We’ll use WunderGraph’s CLI tool for this.
`> npx create-wundergraph-app my-project -E nextjs
npm install`
This sets up a basic NextJS 13 project (the tried-and-true pages router), TailwindCSS for styling, and a .wundergraph directory in your project root that contains config, operations you’ll define, and the unified, typesafe API we’ll eventually generate.
But first, we’ll deal with the BFF API.
Notice this NextJS project needs npm start to get going. Check out the package.json file to know why.
The wunderctl is the WunderGraph CLI. Let’s quickly explain what these commands do:
wunderctl up— Starts the WunderGraph BFF serverwunderctl generate— WunderGraph uses code generation to create typesafe APIs from your config-as-code. This is executed automatically as part ofwunderctl up, but you can run it as and when needed, too.run-p— This isn’t part of WunderGraph itself; this is the npm-run-all package being used to run these scripts (dev,backend,wundergraph, andopen) in parallel.
Anyway, try out npm start, and if you see an example/splash page with data from the SpaceX API, everything’s working correctly. Now, let’s configure our API dependency as config-as-code.
Get rid of the SpaceX API, and include this in its place. Notice the apis dependency array. Any data dependency (OpenAPI REST, GraphQL, Federations, PostgreSQL databases, etc.) you introspect with WunderGraph will need to be defined as a variable, then included in that dependency array.
Next, we’ll create data Operations using GraphQL, that’ll use this API. Note that the WunderGraph SDK namespaces these based on the data source you defined in wundergraph.config.ts
With WunderGraph, you’re only using GraphQL to define these queries/mutations at build time. No GraphQL endpoint is ever exposed. These operations you just defined will be served as hashed, persisted queries, as JSON-over-RPC at runtime, mounted and accessible at a unique endpoint, like:
http://localhost:9991/operations/AllOrdersAnd then you could just fetch data using that endpoint. If you’re using React, NextJS, SolidJS, or a data fetching library like SWR or react-query, though, WunderGraph generates a typesafe client for you anyway.
Our UI/UX design is dead simple. A tabbed display — one for each of the three kinds of information we’ll need.
This is where we’ll see the typesafe data-fetching hooks WunderGraph generates for us, after we’ve defined our operations. This is using Vercel’s SWR under the hood (and can be modified to use react-query if you wish), and all you have to do is pass in the name of the operation (and inputs, if any) you’ve created.
That’s it, you’re done!
So that’s what your app looks like on Week 0, with a monolithic backend API being consumed by a BFF for the NextJS frontend.
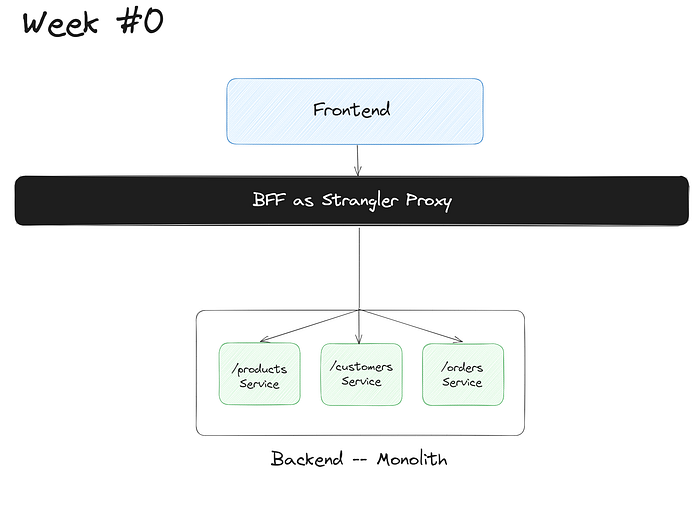
Now, let’s look at what exactly changes when you migrate to microservices. Here’s where you’d use the Strangler pattern to break up that monolith into microservices.
Let’s say, by Week 1, you still have the existing monolithic API, but with just products as a microservice. What would that look like? What changes would you need?
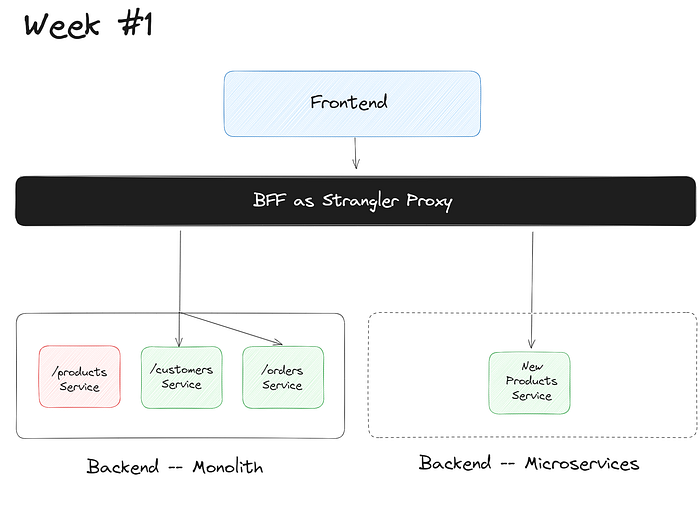
The Express.js app for this microservice is pretty simple — all you’d need to do is extract out the code for this service, and create its own OpenAPI specification.
On the BFF layer, this is a new data dependency, so you’d have to add it to your wundergraph.config.ts, as before.
Of course, since WunderGraph operations are namespaced, you’d have to change the GraphQL Operation for AllProducts.graphql to reflect the new data dependency.
What about on the frontend? What changes would you need there?
This is why the Backends-for-Frontends pattern synergizes perfectly with the Strangler pattern. Your BFF server has eliminated all direct calls from the frontend to the backend, insulating your NextJS client from any change to any downstream service or data dependency.
And of course, now you’d continue with the migration, and by, say, Week 4…
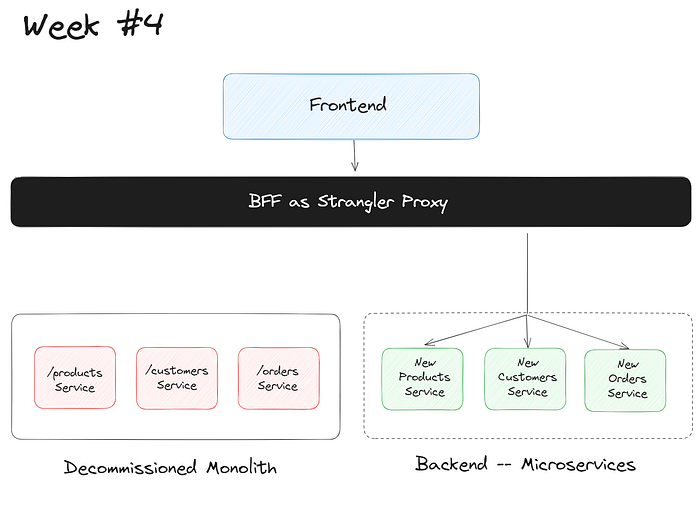
Developers are terrible with time estimates.
…you’d have three microservices — products, customers, and orders — all with their own OpenAPI specs (1 2 3 ) that’ll be consumed by WunderGraph like so:
Three data sources — microservices — to replace the old monolithic API.
Next, make the necessary namespacing changes for the new GraphQL operations (you already have AllProducts.graphql by now) :
And you’re done! As said before, your NextJS frontend code remains wholly unchanged.
Congratulations, you’ve successfully migrated your monolithic API to a microservices architecture, bypassing the drawbacks and risks of the Strangler pattern by using a Backend-for-Frontend server.
Refactoring a monolithic app to microservices requires more than just technical prowess and elbow grease. Every developer ever has felt the urge of a full rewrite to make things better, but that’s just way too much financial and strategic risk.
The Strangler pattern helps by providing a roadmap for incremental adoption. With its gradual and adaptive approach, it helps mitigate the inherent risks of migration by allowing seamless integration of new services while retiring legacy components organically. But there’s still so much rewiring needed.
The Backend-for-Frontends (BFF) pattern is exactly the missing piece here, allowing you to decouple the frontend from the backend in a way that’s meaningful enough to shield the former from any changes taking place in the latter — cutting down on the need for complex rerouting and adapters, making it the perfect compliment to the Strangler pattern.


