
Live from the GraphQL Conf: The State of Distributed GraphQL 2024

Today, we are live from the GraphQL Conf in San Francisco. The conference is packed with talks about the latest and greatest in the GraphQL ecosystem, and we are here to give you a sneak peek into the future of GraphQL.
Over the past few years, it has become clear that GraphQL is not just a very powerful query language for APIs, but also an emerging technology for building APIs on top of distributed systems.
Michael Staib, a member of the technical steering commitee of the GraphQL Foundation and a key contributor to the Composite Schema Specification, just gave a keynote talk about the current state of the specification and what to expect in the future.

In this article, we will take a look at the state of distributed GraphQL in 2024 and explore some of the exciting developments that are happening in this space.
GraphQL was first introduced by Facebook in 2015 as an open-source project, and it quickly gained popularity among developers.
Over the years, GraphQL has evolved into a mature technology with a vibrant ecosystem of tools and libraries. Today, GraphQL is used by companies of all sizes to build APIs for web and mobile applications and is being adopted by more and more organizations from small startups to large enterprises.
One trend that we have seen in recent years is the rise of building distributed systems with GraphQL. Distributed GraphQL allows developers to build APIs that span multiple services and data sources, making it easier to build complex applications that require data from different sources.
What has started with Schema Stitching eventually evolved into Apollo Federation v1, and later on into Federation v2.
But Federation had its limitations, as it was mainly driven by Apollo and did not have a clear specification. There were only the definitions of the relevant directives and everyone had to reverse-engineer the implementation if they wanted to build their own Gateway.
Not having such a specification led to a fragmented ecosystem with implementations that were not or not fully compatible with each other. After all, nobody really knew what the "correct" behavior of a Gateway was supposed to be.
After a lot of discussions and some back and forth, it was decided to create an actual specification for distributed GraphQL under the umbrella of the GraphQL Foundation.
What sounds like a small detail is actually a huge step forward for the GraphQL ecosystem.
You might be thinking that Vendors would benefit from a fragmented ecosystem, as it would allow them to lock in customers with their proprietary solutions.
But the reality is that a fragmented ecosystem is bad for everyone. It's bad for the users, as they have to deal with different implementations that might not be compatible with each other, and it's bad for the vendors, as they cannot easily build integrations with other solutions if no standard exists.
During the sales process, customers often ask about our opinion on the future of distributed GraphQL, and which specification we would recommend to follow.
As such, we're very happy that the Composite Schema Specification was created under the umbrella of the GraphQL Foundation. This will hopefully lead to a more unified ecosystem where different implementations can interoperate with each other.
Let's take a look at some of the key differences and similarities between the Composite Schema Specification and Apollo Federation. You'll be surprised how similar they are, but there are also some notable differences that show how much the ecosystem has matured.
The Composite Schema Specification (CSS) introduces the concept of Entity Resolvers.
Previously in Apollo Federation, you had to define an Entity using the @key directive. For reference, here is how you would define an Entity in Apollo Federation:
The main difference is that in CSS, an entity resolver is just a regular resolver, whereas in Apollo Federation, the Subgraph Framework had to implement the Subgraph Specification, with special fields like _entities and _service.
My opinion:
Exposing an Apollo Federation compatible Subgraph is somewhat cumbersome, because it's not really intuitive to query the _entities field. Having a "real" resolver for entities is definitely an improvement.
On the other hand, the _entities field allowed for an easy way to batch requests to a Subgraph. With the CSS approach, a Gateway/Router would have to use e.g. alias batching to achieve the same result. However, I'm not a big fan of this approach as it can make batching more complicated to implement efficiently in Subgraph frameworks.
Another approach that's being discussed in the composition working group is to introduce a mechanism to send a list of variables. This would have the advantage that the Subgraph could better optimize the query execution, as it's harder to implement efficient execution caching when using alias batching.
As you can see, there are pros and cons to both approaches, and it will be interesting to see how the ecosystem evolves around this topic.
Let's take another look at the previous entity example:
In the Federation example above, it's clear that the id field is both an argument to resolve a Person entity and a field of the Person entity itself. They are semantically equivalent.
With the Composite Schema Specification, we're taking a step back from the @key directive and just define our root resolver.
As such, we need a way to tell both Composition and the Router that the id argument of the personById query is semantically equivalent to the id field of the Person entity.
For the Composition part, it's important that entity keys are semantically equivalent to the fields of the entity itself. For a Router, this is also useful information, as it can optimize the query execution by knowing that it doesn't have to resolve a field if the argument was already provided.
Here's a more complex scenario, showing a nested argument:
In more complex scenarios, it might be more convenient to define a coordinate to describe the relationship between the argument and the entity field.
My opinion:
The @is directive is a great addition to the GraphQL ecosystem. If you're implementing a Gateway/Router, knowing that a field argument is semantically equivalent to a field of an entity can not just help a query planner to optimize the query execution, but also opens up new possibilities. For example we could leverage this information to implement a better caching strategy.
The @shareable, @require, @provides, @external and @override directives are very similar to Apollo Federation
If you're already familiar with Apollo Federation, you'll notice that some of the directives in the Composite Schema Specification are very similar. Namely, the @shareable, @require, @provides, @external and @override directives.
All of them made their way into the CSS, although they are lacking more comprehensive documentation at the moment. As such, it can be assumed that they are essential parts of making distributed GraphQL work.
The @shareable directive is used to mark a field as shareable, meaning that it can be resolved by multiple Subgraphs.
The @require directive was renamed from @requires in Apollo Federation, but it's still used to define dependencies between fields.
To optimize query execution, the @provides directive can tell a Router or Gateway that one resolver can provide other fields. This might be useful to avoid unnecessary fetches.
The @external directive still indicates that a field cannot be resolved by the Subgraph itself.
Finally, the @override directive allows you to move ownership of a field from one Subgraph to another.
My opinion:
It's great to see that the CSS is building on top of some of the concepts of Apollo Federation that have proven to be useful. Not only will this make switching from Apollo Federation to the CSS easier, but it also shows that the CSS is an evolution of the Federation concept and not a completely new approach.
Previously known as @inaccessible in Apollo Federation, the @internal directive is used to mark a field as internal to a Subgraph.
This means that the field can be used "internally" by the Router, e.g. as a key, but it should not be exposed in the public GraphQL Schema.
Example:
In this case, the productSKU field is used as a key to resolve the product field, but it should not be exposed in the public schema. A client could only query the product field.
My opinion:
The @internal directive definitely has its use cases, e.g. when you want to deprecate or remove a field which is still used internally as a key.
What I like as well is that the spec is talking about "public schema". A federated Graph usually consists of two schemas, a client facing schema and a schema containing (potentially) internal information. I think it can be beneficial to have clear naming conventions for these two schemas in the specification.
Regarding the configuration, the specification says the following:
The supergraph is a GraphQL IDL document that contains metadata for the query planner that describes the relationship between type system members and the type system members on subgraphs.
Similar to Apollo Federation, the Composite Schema Specification uses a GraphQL IDL document to describe all information required for a Router to plan and execute distributed GraphQL Queries.
My opinion:
What I like about this approach is that everyone can easily read and understand the configuration. Using GraphQL SDL as a configuration language will make it easy to read and understand for humans.
The drawbacks are that GraphQL SDL is not the most expressive language for configuration, and it can also be slow to parse and validate if we're talking about very large configurations.
At WunderGraph, we've also found that we're able to improve the performance of the Query Planner using Ahead of Time Planning. This means that some of the complex planning logic can be done at build time. However, we found that adding all of this information to the SDL could make it even more complex, very verbose, and generally harder to validate.
For us, storing all of this information in a JSON file has proven to be a much simpler and more efficient approach.
Additional Conversations and Discussions happening around the GraphQL Composite Schema Specification
In addition to the Composite Schema Specification itself, there are some conversations and discussions happening outside of the specification that are worth mentioning. You can find these in the issues section of the specification repository.
We've briefly touched on this topic before, but it's worth mentioning that batching is a challenge with the Composite Schema Specification.
The special _entities field in Apollo Federation allowed for a very easy way to batch load entities from different Subgraphs.
Although a the _Any type feels a bit hacky, it allowed for a simple way to load additional fields for a diverse set of entities.
For example, you could load additional fields for a Product and a Review entity in a single request like so:
What's key here is that the Subgraph can parse and Cache the "query" part of the request, and then execute the query with the provided variables.
With the Composite Schema Specification, this is a bit more complicated.
The Schema of the Subgraph would look like this:
To batch load the Product and Review entity in a single request, you would have to use alias batching like so:
But what if we don't want to load a review? Or what if we want to load multiple products and reviews in a single request?
One technique that's being discussed is to use aliases to batch requests:
That's cumbersome, because now we can only load two products and one review in a single request. What if we want to load 10 products and 5 reviews? Each time, we would "invalidate" the cache of the Subgraph because the content of the query changes. That's not ideal.
Other solutions are being discussed, like introducing a mechanism to send a list of variables. This could look like this:
This would allow the Subgraph to optimize the query execution, but it would introduce a breaking change to the GraphQL Specification. Is it worth it? Or is this a demonstration of the limitations of the Query Language?
Another approach could be to introduce "batching" as a top level concept for Subgraphs. Instead of sending a single request, we could send a list of requests to a Subgraph, like so:
This would certainly work, but it would mean that all Subgraph Frameworks would have to implement this feature in order to be compatible with the Composite Schema Specification. That's not ideal for getting the specification adopted quickly.
Another drawback of this solution is that is requires very sophisticated planning and execution logic in the Subgraph framework to enable efficient batching. If each "query" in the "queries" list is seen as a separate request, the Subgraph would be forced to use parallel execution to resolve the queries together. It would be much more efficient to execute if both queries could trigger a single resolver with multiple inputs, like it was possible with the _entities field in Apollo Federation.
The _entities field allowed for batch processing of diverse entities with a single root field, no aliases, no multiple queries, no complex planning logic required.
Another discussion in the CSS repository is about the name of the specification. Opinions are being raised that the term "Composite Schema" might be too broad and not descriptive enough. Others mention that "GraphQL Federation" is already well known in the community and probably best describes what the specification is about.
My opinion:
The new direction of the specification can be understood as a standardization effort, aligning Apollo Federation with other implementations.
As such, it makes sense to just call it "GraphQL Federation". It's a well known term in the community and it's clear what it's about, simple and to the point.
From the very beginning of building Cosmo , we had the vision of creating an open ecosystem for distributed GraphQL.
This is underscored by the fact that we were the first to provide a fully open-source Full Lifecycle GraphQL Federation Platform in a single monorepo.
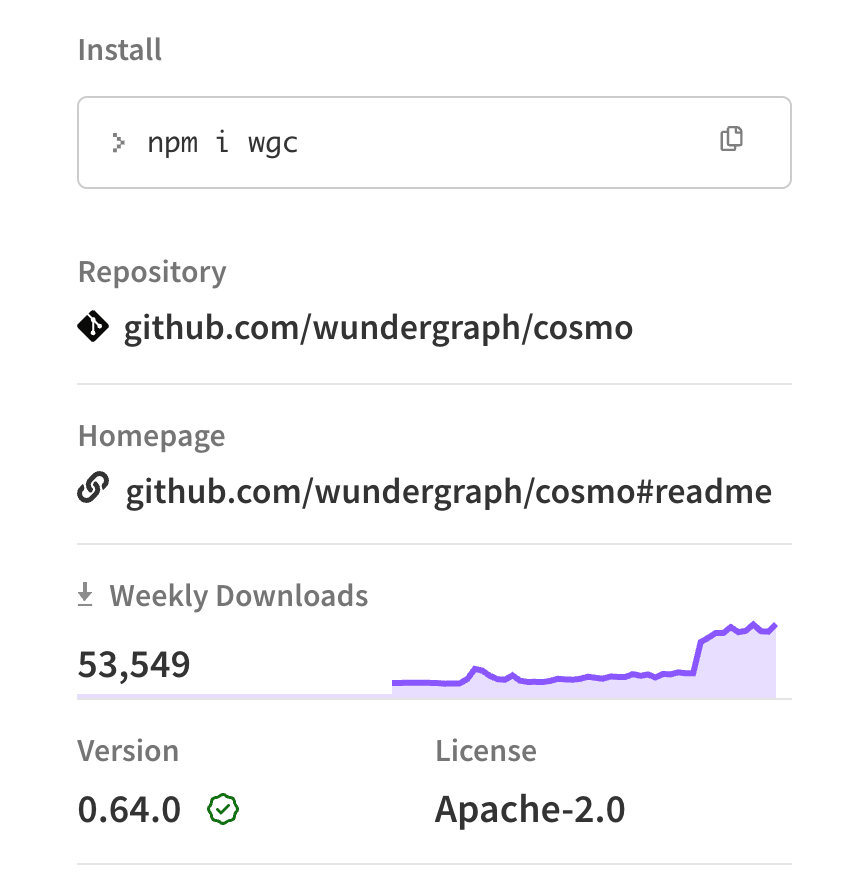
In just under a year, we've seen a steady increase in downloads from less than 1.000 to over 50.000 per week. The growth in npm downloads is a clear indicator that we're on the right track. Thanks to everyone who has supported us on this journey! We're more than happy to have created a vibrant community around Cosmo, with significant contributions from outside of WunderGraph.
To further double down on our initial commitment, we will be among the first to implement the Composite Schema Specification / GraphQL Federation in Cosmo as soon as it reaches a stable state.
The Composite Schema Specification is a huge step forward for the GraphQL ecosystem. Overall, I believe that a common specification for distributed GraphQL will lead to a more unified and stronger ecosystem.
It's also a strong message to the community that they can build on top of a specification that is not controlled by a single vendor, but backed by the GraphQL Foundation.
In addition to the specification itself, I'm excited to see what new business models and opportunities will emerge from a more unified ecosystem. Once solutions can interoperate with each other, we will see more innovation.
Last but not least, I'd like to thank the GraphQL Foundation and all contributors to the Composite Schema Specification for their hard work. It's a huge effort to create a specification like this, but it's very important for the future of (distributed) GraphQL.
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


