
Is gRPC Really Better for Microservices Than GraphQL?

TL;DR
Neither is universally better. Use gRPC for service-to-service, GraphQL for client-facing APIs, and WunderGraph Cosmo Connect to bridge them into one federated API.
We're the builders of Cosmo, a complete open source platform to manage Federated GraphQL APIs. One part of the platform is Cosmo Router, the GraphQL API Gateway that routes requests from clients to Subgraphs, implementing the GraphQL Federation contract.
The Router is a Go application that can be built from source or run as a Docker container. Most of our users prefer to use our published Docker images instead of modifying the source code for customizations.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
Microservices require efficient communication to succeed, but as systems scale and distribute across the globe, ensuring seamless data exchange becomes a critical challenge. gRPC and GraphQL have emerged as leading solutions, each bringing its unique philosophy and strengths to address modern microservices' demands.
This blog will explore whether gRPC, emphasizing raw performance, or GraphQL, with its flexible querying capabilities, is better suited for microservices. Or is there a 'right' choice? We'll compare the performance, flexibility, scalability, and real-time capabilities of gRPC and GraphQL to help you choose the right tool for your microservices architecture.
While the title frames this as a “gRPC vs GraphQL” decision, most modern teams end up with a polyglot API architecture where the right answer is “gRPC and GraphQL” plus the right tooling to connect them.
First, where did this technology come from?
gRPC is a modern RPC framework developed by Google in 2015 to facilitate fast, reliable communication in distributed systems. Its bidirectional streaming and support for multiple languages make it an ideal foundation for performance-critical microservices architectures. Additionally, it enables seamless backend-to-backend communication in polyglot environments by generating language-specific stubs.
GraphQL, developed by Facebook in 2012 and open-sourced in 2015, is a query-driven API framework that prioritizes flexibility in data retrieval. By offering a single endpoint and dynamic query capabilities, GraphQL empowers developers to request exactly the data they need, reducing over-fetching and under-fetching.
| Feature | gRPC | GraphQL |
|---|---|---|
| Query Style | Predefined service contracts | Dynamic, client-driven queries |
| Data Fetching Efficiency | Can lead to over-fetching | Minimizes over and under-fetching |
| Example Use Cases | Backend-to-Backend Communication | Complex UIs that require precise data fetching |
gRPC enforces predefined service contracts. While this ensures consistency, it can lead to over-fetching. For instance, a client requesting a user's name might receive an entire user profile. Updating API definitions is often required to change data needs. Additionally, gRPC lacks a built-in mechanism for aggregating data from multiple services.
GraphQL excels in flexible data fetching because clients can request only the data they need. Additionally, Federation provides a built-in, out of the box solution for aggregating data from multiple sources. GraphQL simplifies client-side development by allowing dynamic queries, especially when components need different subsets of data.
For example, if you wanted to fetch all the available data for a user, you could query:
And you would expect the following response:
If you only needed the name and email of the user, you could query:
This smaller response would be returned:
Or if you needed something nested, like whether or not the user wants notifications, you could query:
You could expect the response to look like this:
These examples highlight the GraphQL's flexibility, allowing clients to fetch only what they need. This adaptability minimizes over and under fetching and makes GraphQL particularly effective with precise data requirements.
Building on this flexibility, teams can use GraphQL Federation to manage and scale subgraphs independently. These subgraphs are composed into a unified schema that streamlines data aggregation and enables scalability across decentralized teams and systems with diverse data needs.
The diagram below demonstrates how GraphQL Federation simplifies data aggregation by breaking the initial query into subqueries. A subquery is a smaller query derived from the original query but focused on retrieving specific data from specific graphs. The subqueries are then sent to the respective subgraphs, which will process their part of the query and return the data required to the router. The router combines the data and sends a unified response back to the client.
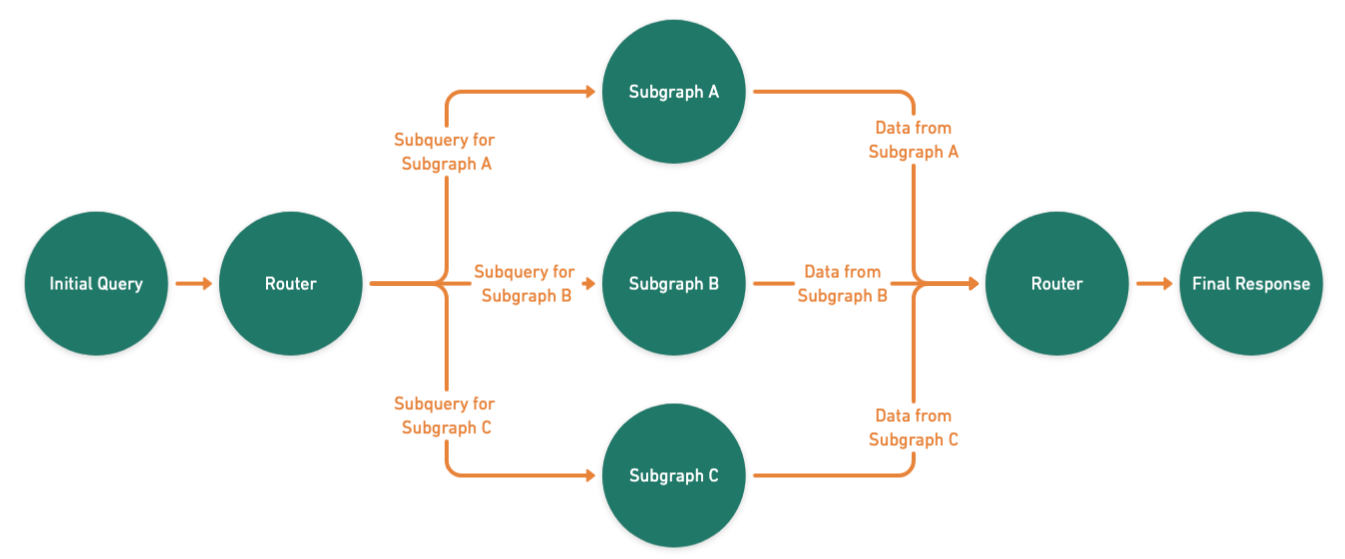
- Router: This is the entry point for queries. It analyzes the federated schema to determine which subgraphs are responsible for specific fields in the query. The router parses the query, delegates the subqueries, and then assembles the response.
- Subgraph: Independent services that represent specific domains or data sources in the overall architecture. Each subgraph contributes only the data it is responsible for in response to its subquery.
- Federated Schema: This single, consolidated schema defines how data from all subgraphs is structured. It enables the router to interpret the relationships between the subgraphs and efficiently resolve queries.
| Feature | gRPC | GraphQL |
|---|---|---|
| Serialization | Binary for smaller, faster data transfer | JSON, human-readable but has a higher overhead |
| Protocol | Requires HTTP/2 | Protocol-agnostic |
| Example Use Case | Real-time analytics, IoT | Applications requiring flexible data exploration, like dashboards or developer tools |
gRPC requires HTTP/2 for its low-latency communications and binary serialization (via Protocol Buffers ). Protocol Buffers allow you to define data structures once and use the generated code to easily serialize and deserialize that data for transmission over networks or storage. This significantly reduces the size of data transmitted and speeds up the serialization/deserialization process. These features make gRPC ideal for environments requiring high throughput, such as real-time analytics, streaming, and IoT communication.
GraphQL is protocol-agnostic, commonly used over HTTP/1.1 or HTTP/2 when available. While it benefits from HTTP/2 features to enhance performance, its flexibility allows it to operate over any transport protocol (like WebSockets). This flexibility makes GraphQL ideal for applications with varying client types (e.g., mobile, web) and use cases where adaptable APIs matter more than raw performance.
| Feature | gRPC | GraphQL |
|---|---|---|
| Real-Time Mechanism | Native support for bidirectional streaming | Subscriptions via WebSockets or SSE |
| Efficiency | Extremely efficient for high-frequency updates | Less efficient than gRPC for high throughput |
| Example Use Case | Server to server communication | Chat apps, live dashboards |
gRPC's native support for bidirectional streaming, combined with its use of Protocol Buffers, make it highly efficient for real-time server-to-server communication. This efficiency is important in scenarios like managing distributed systems and handling microservice interactions.
As shown in the diagram below, gRPC leverages Protocol Buffers to serialize requests into compact binary messages that are then sent over HTTP/2. The server then deserializes these messages and processes them accordingly. HTTP/2 supports multiplexed streams, which allows both the client and server to send and receive messages continuously. The following diagram provides a detailed view of how data flows through gRPC’s lifecycle.
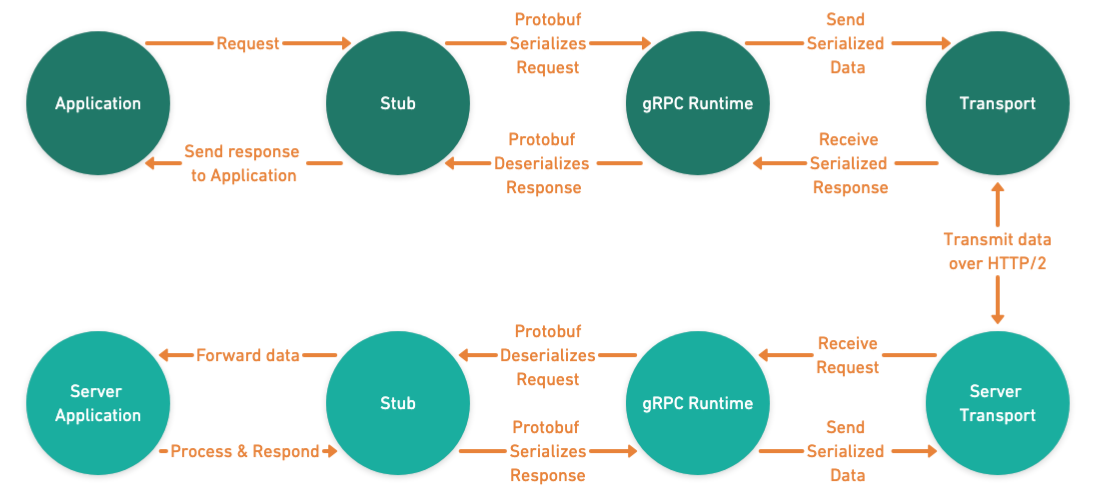
- Application: The entry point for sending or receiving messages
- Stub: This generated code proxy simplifies the developers interaction with gRPC runtime by abstracting serialization and deserialization.
- gRPC Runtime: This handles retries, deadlines, stream management while ensuring that data is efficiently transported.
- Transport: This layer leverages HTTP/2 for multiplexed, secure, and low-latency communications.
GraphQL subscriptions allow real-time updates over WebSockets, which work well for most applications but may be less efficient in high-throughput scenarios. However, tools like WunderGraph's Event-Driven Federated Subscriptions (EDFS) are available to enhance GraphQL's real-time capabilities. EDFS uses an automated, event-driven approach to simplify real-time data synchronization.
Your team's expertise, existing ecosystem, and workflow also play a role in determining whether gRPC or GraphQL is more suitable for your project.
gRPC offers robust tooling for schema generation and integration, relying on Protocol Buffers for serialization. Its strict service contracts ensure consistent, high-performance communication between services. These features will likely appeal to backend-heavy teams with expertise in schema management and communication protocols.
However, gRPC’s steep learning curve can pose challenges, especially for teams unfamiliar with its ecosystem. Managing .proto files to prevent service disruptions requires careful coordination, and debugging binary payloads requires specialized tools like grpcurl or gRPC Tracing, which may slow adoption.
Despite these obstacles, structured training programs and detailed documentation can help teams fully leverage gRPC's potential. For high-throughput environments, such as real-time analytics or machine learning pipelines, gRPC provides a disciplined and scalable framework that ensures low latency and high reliability.
GraphQL thrives in cross-functional teams that prioritize flexibility and rapid iteration. Its dynamic querying capabilities simplify data fetching for diverse UI components, which can reduce the over and under-fetching issues common in traditional REST APIs. This makes GraphQL well-suited for applications with evolving user interfaces, where different components require varying data subsets.
The framework also benefits from a mature ecosystem. For example, WunderGraph offers features such as schema validation, query monitoring, and federated composition checks. Federation empowers decentralized teams to manage subgraphs independently while maintaining a unified API. GraphQL's testing ecosystem also simplifies QA processes with tools like Apollo MockedProvider for isolating components and Jest for snapshot testing. Using query performance benchmarks helps ensure APIs perform efficiently under load, even as data requirements evolve.
GraphQL's flexibility comes with the risk of schema sprawl. As teams add more fields and subgraphs over time, the schema can become overly complex, making it difficult to maintain and govern. Without adequate oversight, subgraphs can become unmanageable. To mitigate these risks, teams will need to establish clear schema design principles, conduct regular schema reviews, and implement automated validation. These practices ensure the schema remains scalable, maintainable, and aligned with the system's evolving needs.
GraphQL’s user-friendly tooling and collaborative workflows provide an ideal solution for teams with diverse and fast-moving requirements, streamlining development and enhancing the overall developer experience.
Both gRPC and GraphQL offer significant advantages to microservices architecture, but neither is perfect. Below are some key associated issues, as well as practical strategies for overcoming them.
While gRPC excels in backend-to-backend communication, integrating it with browser-based clients poses challenges due to the lack of native support for HTTP/2's low-level streaming in browser environments. Although modern browsers support HTTP/2 at the networking level, they don’t directly provide the necessary APIs to handle gRPC’s HTTP/2 framing.
- Workaround: gRPC-Web resolves this by providing a proxy or library that translates gRPC calls into standard HTTP requests.
- Impact: Adding additional proxies and libraries to bridge that gap can add complexity to the system. While it does add complexity, this is a commonly used, stable solution.
gRPC uses Protocol Buffers to define and serialize data. However, this introduces a new schema definition language that developers need to learn. Combined with gRPC’s advanced features, this can slow down teams unfamiliar with RPC frameworks.
- Workaround: Invest in comprehensive training and provide clear, accessible documentation.
- Impact: Initial onboarding may slow development, but it sets the foundation for efficient long-term use.
gRPC’s binary-encoded payloads may make debugging more challenging than working with JSON. Standard tools, like browser DevTools, offer limited insight into Protocol Buffer data.
- Workaround: Specialized tools like
grpcurlcan help inspect and troubleshoot gRPC messages. Enabling logging middleware or reflection endpoints can aid in catching and analyzing data in a more readable format. - Impact: Debugging requires additional expertise and tools, potentially extending the time needed to resolve issues
GraphQL’s single endpoint design can make traditional network-layer caching less effective. Dynamic queries can further complicate this.
- Workaround: Implement schema-driven caching solutions like those offered by WunderGraph.
- Impact: Without optimized caching, server load may increase, leading to slower response times under heavy traffic.
Although GraphQL minimizes over-fetching on the client side, large or complex queries can sometimes lead to server-side over-fetching, particularly if the schema is not well-designed or queries are not being carefully monitored.
- Workaround: Establish clear query optimization guidelines, design the schema to align with data requirements, and implement query governance to prevent inefficient queries. Regularly monitor query performance to identify and address potential issues.
- Impact: Inefficient queries can degrade performance, especially in high-traffic environments.
While GraphQL simplifies client-side data fetching, managing its schema effectively is critical to avoid sprawl.
- Workaround: Employ the schema registry tools WunderGraph offers to monitor and govern schema evolution. Automating schema validation in CI/CD pipelines helps catch breaking changes early, while regular reviews of query usage patterns can provide valuable insights for optimization and reducing server load.
- Impact: Proper governance minimizes maintenance challenges and ensures a stable, scalable system as the application grows.
The flexibility of GraphQL can be a double-edged sword. Without taking appropriate precautions, APIs are susceptible to introspection abuse, exposing unintended fields, or over-querying.
- Workaround: Enforce query complexity limits, disable introspection in production, and use robust authentication mechanisms.
- Impact: Without safeguards, APIs become vulnerable to exploitation.
gRPC: Its binary serialization via Protocol Buffers and HTTP/2 communication significantly reduces data transmission size and latency. This makes it perfect for performance-critical systems like real-time analytics, video streaming, or financial services. GraphQL supports various formats, but its typical JSON-based workflows are not as performance-focused as gRPC's binary protocol.
GraphQL: Its dynamic, query-driven approach allows clients to fetch the data they need in a single query, reducing API roundtrips and improving efficiency for client-driven applications. However, gRPC can also be used effectively in client-driven systems, especially when performance is critical, though it requires more upfront planning due to its predefined service contracts.
gRPC: Its predefined service contracts ensure efficient, low-latency interactions between services, which is ideal for architectures requiring backend service-to-service communication. gRPC also supports subscriptions natively, which simplifies real-time communication on the backend. GraphQL’s flexibility is excellent for frontend-driven use cases, but its subscriptions depend on additional support from the router or subgraph framework.
GraphQL: When utilizing Federation, GraphQL can efficiently aggregate data from multiple services and consolidate the results into a unified response. While gRPC lacks built-in aggregation features, similar functionality can be achieved by building a custom aggregator service. This approach allows you to replicate a federated architecture, though it requires significantly more development effort and careful orchestration to manage dependencies between services.
gRPC: With native client-side, server-side, and bidirectional streaming support, gRPC handles real-time data more efficiently than GraphQL’s WebSocket-based subscriptions. For high-frequency updates like live video feeds, telemetry data, or stock market updates, gRPC’s performance is unmatched.
GraphQL: GraphQL Federation enables teams to manage their subgraphs independently, fostering rapid iteration and scalability while avoiding bottlenecks in a centralized API. gRPC doesn’t offer such built-in modularity for large-scale, team-based development. That being said, gRPC can also support large-scale systems if teams coordinate effectively using .proto files and implement robust versioning strategies to maintain consistency and avoid schema conflicts.
gRPC: Its compact binary format significantly reduces the size of transmitted data, which is vital for handling large datasets in systems like machine learning pipelines or high-throughput messaging services. GraphQL’s text-based JSON payloads may introduce unnecessary overhead in the same scenario.
GraphQL: Data-fetching is simplified for frontend components by allowing targeted queries to specific subgraphs, reducing duplication and improving performance. In contrast, gRPC's predefined service contracts may require additional work and maintenance to meet the particular needs of a complex UI.
gRPC or GraphQL: Both frameworks excel at cross-language communication. gRPC offers robust backend support with its generated stubs, while GraphQL's flexible, HTTP-based design adapts well to polyglot environments.
GraphQL: Its single unified endpoint abstracts service complexity, and provides a seamless, efficient integration experience for external developers. However, gRPC can also serve third-party developers who have strong backend expertise and need high-performance APIs, though its learning curve and stricter service contracts may necessitate additional onboarding and support.
Most teams do not operate in a pure "gRPC vs. GraphQL" world. In practice, they end up with a polyglot API strategy, choosing different protocols for different jobs. REST often remains in place for existing systems, gRPC is used for high-performance service-to-service communication, and GraphQL becomes the flexible layer for client-facing experiences.
GraphQL is not necessarily a replacement for REST or gRPC. In many architectures, it works best as a unifying layer that sits above multiple backend protocols and gives clients a single API surface. The real challenge is connecting those systems without forcing every backend team to adopt GraphQL servers or GraphQL-specific frameworks.
This is where Cosmo Connect fits. Cosmo Connect is designed to let teams use GraphQL Federation without requiring backend teams to run GraphQL servers. Instead, teams define an Apollo-compatible subgraph schema, compile it into a protobuf definition, and implement it using their preferred gRPC stack while the router handles query planning and batching.
Cosmo Connect also supports wrapping existing APIs, including REST and SOAP, which reduces the need for large rewrites during migration. The result is a federated GraphQL layer that can sit in front of mixed backend systems while preserving language flexibility and team autonomy.
A practical way to describe it is:
- Use gRPC where low latency, strict contracts, and efficient service-to-service communication matter most.
- Use GraphQL where clients need flexible data access through a single endpoint.
- Use Cosmo Connect to bridge GraphQL Federation with gRPC services and existing APIs, so backend teams can keep their current implementation model while platform teams still deliver one federated graph.
The architecture follows a pattern of:

Imagine a team building a real-time analytics platform. The ingestion, scoring, and aggregation services communicate internally over gRPC because they need efficient network communication, independent scaling, and clear service boundaries. At the same time, product teams want one GraphQL endpoint for dashboards, admin tooling, and partner-facing applications.
With Cosmo Connect, the platform team can define subgraph schemas for those domains and compile them into protobuf definitions that backend services implement over gRPC. Those services can then be built in languages such as Go, Java, C#, Python, Rust, or others that support gRPC, without requiring each team to run a GraphQL server.
The Cosmo Router then accepts a GraphQL query, plans it across the relevant subgraphs, translates those operations into gRPC calls across the network, and composes the results into a single response for the client. That gives the organization a polyglot API strategy: gRPC where performance matters, REST where it already exists, and GraphQL where flexibility and a unified client experience matter most. This is a notable differentiator for teams that want federation without GraphQL servers everywhere.
In practice, the best answer is often not gRPC or GraphQL, but gRPC for service-to-service communication, GraphQL for client-facing APIs, and Cosmo Connect to unify them in a federated architecture.
Selecting between gRPC and GraphQL depends on which framework better addresses the unique challenges of your project. gRPC excels in speed and low-latency backend communication, making it perfect for performance-critical systems. Meanwhile, GraphQL's flexible querying and streamlined data delivery shine in client-driven applications with intricate requirements.
Regardless of your choice, success depends on investing in the proper tooling, adequate training, and governance practices. Open collaboration between team members and stakeholders will help you design a scalable microservices architecture that meets your goals and adapts to future demands.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
If you like the problems we're solving and want to learn more about Cosmo Router, check out our GitHub repository and take a look at our open positions if you're interested in joining our team.
Frequently Asked Questions (FAQ)
Use gRPC when raw performance, low-latency communication, and efficient binary serialization are top priorities, such as in real-time analytics, IoT, or backend-to-backend service communication. gRPC excels with Protocol Buffers over HTTP/2, providing fast, compact, and reliable message exchange.
GraphQL Federation allows teams to manage subgraphs that compose into a unified schema independently. This enables a central Router to resolve a single query by delegating subqueries to the relevant subgraphs, then returning a unified response, thereby reducing the need for custom aggregation logic.
Yes. gRPC supports native bidirectional streaming over HTTP/2 using Protocol Buffers, which is more efficient for high-throughput, real-time updates. While GraphQL supports subscriptions via WebSockets or SSE, it may introduce more overhead and is less optimized for streaming at scale.
Absolutely. Many teams, including WunderGraph, use a hybrid approach: gRPC powers efficient backend communication, while GraphQL Federation provides a single, flexible API layer for clients. This combines performance and developer experience in one scalable system.
gRPC has a steeper learning curve, limited browser support, and more complex debugging due to binary payloads. GraphQL requires governance to avoid schema sprawl, and caching or query complexity can be difficult to manage without the right tools. Both require training and tooling to succeed at scale.
Yes. GraphQL’s dynamic, client-driven queries let UIs fetch exactly the data they need, avoiding over-fetching and under-fetching. This makes it especially effective for dashboards, developer tools, and apps with diverse or evolving data needs.
Content Manager
Brendan Bondurant is the Content Manager at WunderGraph, owning technical content across GraphQL Federation, API tooling, and developer experience. He partners with leadership on product and company messaging and works cross functionally to align positioning, terminology, and content strategy across channels.


