
When to use GraphQL vs Federation vs tRPC vs REST vs gRPC vs AsyncAPI vs WebHooks
This is not your typical comparison article that praises one technology over others. Instead, it will give you a framework to make technology decisions based on use cases and requirements.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
Every week, we talk to developers from companies of all sizes and industries, from StartUps with 5 developers to large enterprises with 1000s of developers. What this allows us to do is to see patterns and trends across the industry. Some companies are more mature in their API journey and have strong opinions on what to use, while others are just starting to formalize their API strategy and are looking for guidance.
My goal is to give you a high-level overview of the most popular API styles, how companies are using them, and why they are choosing one over the other.
Let's start with a brief overview:
REST stands for Representational State Transfer and is a software architectural style that defines a set of constraints to be used for creating web services. RESTful systems typically communicate over HTTP, using verbs such as GET, POST, PUT, DELETE, and PATCH. REST APIs are stateless, meaning that each request from a client to a server must contain all the information necessary to understand the request.
GraphQL is a query language for APIs and a runtime for executing those queries by using a type system you define for your data. GraphQL was developed by Facebook in 2012 and open-sourced in 2015. With GraphQL, clients can request exactly the data they need, leveraging Fragments to define data requirements per UI component.
GraphQL Federation is an extension of GraphQL that allows you to compose multiple GraphQL services into a single schema. This is particularly useful when you have multiple teams working on different parts of the API. Each team can own their part of the schema and expose it as a service that can be composed into a single schema. Federation allows organizations to scale their API development by giving teams autonomy while employing centralized governance.
tRPC is a TypeScript-first API framework that allows you to define your API using TypeScript types. The mindset behind tRPC is to leverage TypeScript's type system to define the API contract between the client and the server. There's no compile-time step or code generation involved, allowing developers to iterate quickly while catching errors through TypeScript's type system.
gRPC is a high-performance, open-source universal RPC framework that was developed by Google. gRPC uses Protocol Buffers as the interface definition language and provides features such as bidirectional streaming, flow control, and blocking or non-blocking bindings. The RPC API style is particularly popular in the microservices world, where performance and scalability are critical.
GraphQL vs gRPC in microservices
When both styles show up behind the gateway, trade-offs stop being theoretical. Is gRPC really better for microservices than GraphQL? goes into detail so you can decide when RPC rigidity beats GraphQL flexibility.
WebHooks are a way for one application to provide events or status updates to another application in real-time. WebHooks allow you to build event-driven architectures and integrate systems in a loosely coupled way. WebHooks are particularly useful when you want to trigger actions based on events that happen in another system, but they also come with challenges around reliability and scalability.
AsyncAPI is a specification for defining event-driven APIs. It is similar to OpenAPI, but instead of defining RESTful APIs, it allows you to define event-driven APIs. AsyncAPI allows you to define the events that your API produces and consumes, including the payload structure, message format, and protocol details.
In this comparison, we're making the distinction between WebHooks and AsyncAPI to clearly separate Pub/Sub and Streams from WebHooks.
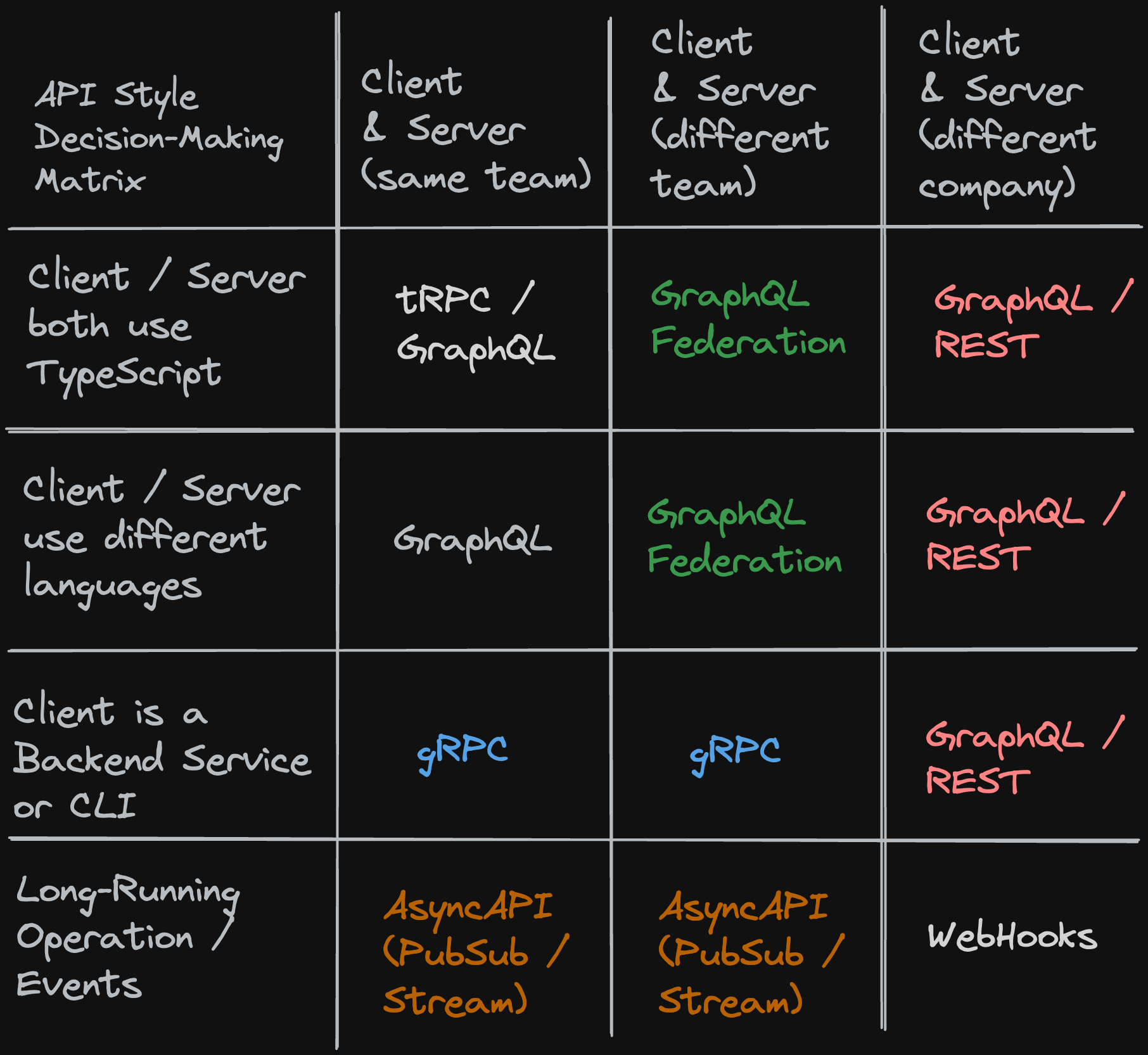
As mentioned earlier, we're not going to start with a technology-first approach, but rather with a use-case and requirements-first approach, ensuring that the technology choice aligns with the business goals and constraints, and not the other way around.
When should I use tRPC vs GraphQL if my team uses TypeScript for both client and server?In this scenario, you have a single team that is responsible for both the web client and the server. The team is proficient in TypeScript and writes both the client and server code in TypeScript.
For a long time, GraphQL was the default choice for this scenario, but tRPC emerged as a strong contender. tRPC allows you to define your API using TypeScript types and provides a seamless developer experience for TypeScript developers.
However, things took a turn when some very smart folks in the GraphQL community figured out how to leverage TypeScript Language Server Plugins to provide a similar developer experience to tRPC. I'm speaking of the graphql.tada project. We're a proud sponsor of this project alongside BigCommerce, The Guild, and BeatGig.
From the description of the project:
In short, with gql.tada and GraphQLSP you get on-the-fly, automatically typed GraphQL documents with full editor feedback, auto-completion, and type hints!
It might look like tRPC is simpler to use and easier to get started with, but there's actually not much of a difference between implementing a tRPC handler and a GraphQL resolver. In fact, with frameworks like Grats , you can define your GraphQL schema just by using TypeScript types. Combine that with gql.tada, and you have a very similar developer experience to tRPC.
tRPC vs GraphQL (TypeScript teams)
If your team is weighing RPC ergonomics against public-schema flexibility, tRPC vs GraphQL: the simplicity trade-off spells out where each style stops being a good default—before you paint yourself into a monorepo-only corner.
But that's not the only reason why you might choose GraphQL over tRPC. How likely is it that you'll need to expose your API to third-party developers? If the answer is "very likely", then GraphQL might be a better choice as tRPC is not designed for this use case. It's possible to generate an OpenAPI spec from your tRPC API, but it's not the primary use case.
Another reason to choose GraphQL over tRPC is the potential use of Fragments. Fragments allow you to define data requirements per UI component, which can be particularly useful in complex UIs with many components that need different data. With tRPC, you define RPC calls and attach them to components, which means that it's not possible to define data requirements per component, which leads to over-fetching and tight coupling between UI components and RPC calls, whereas with GraphQL, Fragments allow you to decouple defining data requirements from fetching data.
Finally, how likely is it that you'll have to split your team into multiple teams, or that you'll have to split your API into multiple services? In both cases, GraphQL provides a clear path forward, while tRPC really shines when you have a single team with a single monorepo.
Keep in mind that nothing is set in stone, and the purpose of software is to be changed. A lot of small teams are very productive and happy with tRPC. In the case that you feel like you're growing out of the comfort zone of tRPC, you can always add a REST or GraphQL API alongside the tRPC interface.
If you want to build an API that's not tied to a specific API style, you can build an internal "service layer" that abstracts away the business logic from the API style. In some frameworks, this is called a "service object" or "service class", others call it "controller". With this approach, you can switch out the API style or even expose multiple API styles side by side without changing the business logic. In fact, such a service layer would allow you to test the business logic in isolation from the API style, and add new API styles as needed.
To summarize, if you have a single team that uses TypeScript for both the client and server, both tRPC and GraphQL are good choices, although the GraphQL ecosystem is much more mature and gives you more options to scale your API development.
What's the best API style when my frontend is TypeScript but backends are Go, Python, or Java?In this scenario, you have a single team that is responsible for both the web client and the server, but the team uses multiple languages for different parts of the stack, e.g., TypeScript for the client and Go, Python, or Java for the server.
In this scenario, we're going to rule out tRPC as it's designed for TypeScript-first development, which makes GraphQL the default choice for this scenario for the same reasons as in the previous scenario.
However, GraphQL might not always be the best choice, depending on your requirements.
Should I use GraphQL or gRPC when the client is a CLI or backend service?In this scenario, you have a single team that is responsible for both the client and the server, but the client is a CLI or a backend service that doesn't have a UI.
GraphQL gives you a lot of flexibility through Fragments and Selection Sets in general, which can be particularly useful when you have a UI that needs different data requirements per component.
But what if we're talking about a CLI or a backend service that doesn't have a UI? A CLI has simpler, less nested data requirements than a UI. A backend service doesn't benefit from GraphQL's flexibility as much as a UI does. Instead, GraphQL might introduce unnecessary complexity and overhead in service-to-service communication. The client needs to fetch the Schema through introspection, define Queries, generate Models, and wire it all up.
In this scenario, gRPC might be a better choice as it's designed for service-to-service communication. The server defines the Protocol Buffers schema, which is then used to generate client and server code in multiple languages. The client directly calls the RPC method on the server without the need to first define a Query. In service-to-service communication, over-fetching is less of a concern.
What should I use for long-running jobs inside one company: REST, GraphQL, or AsyncAPI?In this scenario, you have a single company with one or more teams that need to implement long-running operations. and you need to implement long-running operations. This could be a video encoding job, a machine learning model training job, or a data processing job. These jobs can take minutes, hours, or even days to complete. We need a way to run them asynchronously and provide progress updates to the client.
Designing long-running GraphQL or REST workflows
Once a job outlives HTTP timeouts, your schema and transport choices matter. API design best practices for long-running operations: GraphQL vs REST compares patterns for progress, polling, and subscriptions without pretending everything is a quick RPC.
In this scenario, we're going to rule out REST, GraphQL, and gRPC as they are designed for request-response communication. The request would time out before the job completes.
We're seeing a clear trend towards Event-Driven Architectures and AsyncAPI in this scenario. AsyncAPI is a specification for defining event-driven APIs, which allows you to define the events that your API produces and consumes, including the payload structure, message format, and protocol details.
Implementers need to decide whether Events should be durable or not. If the Event is not durable, it's lost if the consumer is not available to process it. If the Event is durable, it's stored in a message broker until the consumer is available to process it. This decision has implications on the reliability and scalability of the system. Ephemeral Event systems are simpler to implement, but events can easily be lost.
With Stream Processing tools like Apache Kafka or NATS JetStream, you can build more reliable systems with better guarantees around message delivery and processing compared to simple Pub/Sub systems.
There are a few limitations to keep in mind when using Async APIs like Kafka or NATS JetStream. These systems require a very powerful client library to handle the complexity of the protocol, which makes them less suitable for limited environments like browsers or mobile devices. Also, you don't want to publish large nested payloads as messages, so you'd want to have the possibility to "join" messages from a Stream with data from other sources. Thirdly, message brokers are not designed to be used across multiple companies, so you'd want to have a way to "bridge" messages securely and with limited overhead between different companies.
For the first two problems, we've found a solution in Event-Driven Federated Subscriptions (EDFS). EDFS is a declarative approach to join messages from Pub/Sub systems and Streams with data from Microservices.
Here's an example of how you could define an EDFS Subscription in your GraphQL Schema:
In this example, we're defining a Subscription that listens to the employees.{{ args.id }} topic in the NATS JetStream system. When a message is published to this topic, the employeeUpdated Subscription is triggered, and the client receives the updated Employee data.
You can also see that we've defined the Employee type with the @key directive. This is how we tell the GraphQL Federation Router that the id field can be used to join other Employee fields from different services. E.g. we could now add an Employee Service to enrich the NATS stream with additional Employee data like so:
You can now subscribe to the employeeUpdated field, and the Router will automatically join the NATS Stream data with the Employee Service data.
To learn more, check out the EDFS Documentation .
For the second problem, bridging messages between different companies, we need a different approach.
When should I prefer WebHooks vs AsyncAPI for cross-company event-driven APIs?In this scenario, you have multiple companies that need to implement long-running operations and event-driven APIs. These companies might have different requirements, different technologies, and different security policies. You need a way to securely exchange messages between companies and ensure that messages are delivered reliably.
An example of this scenario is GitHub's WebHooks. GitHub allows you to register WebHooks that are triggered when certain events happen in your repository, e.g., a new Pull Request is opened. When the event happens, GitHub sends an HTTP POST request to the WebHook URL you've registered, containing information about the event.
Good implementations of WebHooks sign the payload with a secret key which is shared between GitHub and the WebHook receiver. This allows the receiver to verify that the payload was sent by GitHub and not by an attacker.
WebHooks are a very simple and effective way to build secure event-driven APIs across multiple companies, but they are not without their challenges.
On the side of the sender, you need to ensure that all messages are delivered reliably. If the receiver is unable to process the message, there needs to be a way to retry sending the message. If something goes wrong, both parties need to be able to troubleshoot the issue, which requires logging and monitoring.
You'd usually want to combine WebHooks with a persistent message queue like RabbitMQ, NATS JetStream, or Apache Kafka to ensure that messages are delivered reliably and to "buffer" spikes in traffic.
On the side of the receiver, you need to ensure that every message is processed exactly once, not twice, but also not zero times.
So, if you're receiving a WebHook event, you'd want to store it in a database or message queue before responding with a 200 OK. In addition, systems like NATS JetStream allow you to define a window of time in which messages will be deduplicated, which can be useful to prevent processing the same message twice. Furthermore, Stream Processing tools allow an event consumer to "acknowledge" a message once it has been processed, which ensures that the message was processed. If no acknowledgment is received within a certain time frame, the message can be redelivered.
To summarize, there's no one-size-fits-all solution for implementing long-running operations and event-driven APIs. The choice of technology depends on the requirements of the system and the constraints of the environment. Depending on these, it's likely that you'll need to combine multiple technologies to build a reliable and scalable system.
How do I scale APIs across many teams and services: REST catalog or GraphQL Federation?In this scenario, you have multiple teams that are responsible for different parts of the stack, e.g. multiple product teams that build mobile and web applications with different requirements and constraints. In addition, you have many backend teams that build services in a variety of languages that are suitable for the task at hand.
This is the most common scenario in scale-ups and enterprises, where you want to scale your API development across many teams and services. You need a solution that allows teams to work autonomously while providing centralized governance and control. At the same time, you want to foster collaboration across teams and services to avoid duplication of effort and ensure consistency.
There's an "old" way of doing this, and there's an "emerging" way that we're seeing more and more companies adopt. Jens Neuse unpacks the adoption side of that split in Exploring 2.5 Reasons People Embrace GraphQL—why monolithic GraphQL lost mindshare while Federation gained it.
The old way is to use REST APIs with OpenAPI (formerly known as Swagger) to define the API contract. OpenAPI specifications are then published into a central repository, usually known as API Catalog or API Portal. Teams can use the API Catalog to discover APIs, generate client SDKs, and mock servers.
There are several challenges with this approach. Although API specifications are published into a central repository, this workflow doesn't foster collaboration across teams and services. Teams are still working in silos and don't have visibility into what other teams are building. It's very common to see duplication of effort and inconsistency across APIs.
The emerging way is to use GraphQL Federation to compose multiple GraphQL services into a single schema. On the client side, API consumers can query the composed schema as if it were a single API. As Federation builds on top of GraphQL, it inherits all the benefits, like allowing different clients with varying data requirements to use the same API without having to put a custom BFF (Backend for Frontend) in front of it. But that's not even the main benefit of Federation in this scenario. GraphQL Federation allows multiple teams to collaborate on a single API without stepping on each other's toes. Teams can work together to define Entities and Relationships in the Schema, while still being able to work autonomously on the parts of the schema they own.
What if your backend teams don't write GraphQL?
They don't have to. With GraphQL Federation over gRPC, backend teams build plain gRPC services and the Router talks to them directly, so clients still get one GraphQL schema with no shim layer in between. The Router also batches entity lookups, so N+1 never lands on the service.
With Federation, the API Catalog is not an afterthought. The unified Schema is the evolution of the API Catalog. Instead of having to search through all existing APIs in the Catalog to find the ones who expose a User entity, you can just look at the Schema and see that such an Entity exists, which fields it has, and which services and stakeholders are responsible for it.
With REST, an entity like a User would be owned by a single API, and if you wanted to link a User to a Post, you'd have to establish the relationships in the API Schema, e.g. by embedding a link to the Posts API in the User API. With Federation, we can define these concepts in a declarative way in the Schema, so it's immediately clear which services are responsible for which parts of the Schema, and how another service can "join" a field on an Entity from another service.
To summarize, if you are looking to scale your API development across many teams and services, GraphQL Federation is the emerging standard to achieve this. It allows teams to work autonomously while providing centralized governance and control, and fosters collaboration across teams and services to avoid duplication of effort and ensure consistency.
Similarly to what React and NextJS did for the frontend world, GraphQL Federation is on its way to revolutionize the way we build APIs. It's becoming the standard for building APIs in a distributed environment, and the more companies adopt it, the more tools and best practices will emerge around it.
Past the hot takes on GraphQL vs REST
GraphQL vs REST: 18 claims fact-checked looks at the evidence behind the hot takes.
It's important that we shift the discussion from "GraphQL vs REST" in the context of "which technology performs better on a technical level", to "which technology aligns best with our business goals and constraints and allows us to scale our API development across many teams and services".
Should I expose my public API as REST, GraphQL, or both?In this scenario, you have one or more teams that need to build a Public API for third-party developers. This API needs to be well-documented, easy to use, and scalable. The constraints are different from building an internal API, as you need to consider the needs and requirements of third-party developers, like for example long-term stability and backward compatibility.
There are two main approaches to building a Public API: REST and GraphQL.
REST APIs are well-suited for building Public APIs as they are easy to understand and use. You can define the API contract using OpenAPI, which is a well-established and widely accepted standard for defining RESTful APIs. OpenAPI allows API consumers to generate client SDKs and mock servers, and you'll get the least resistance from third-party developers to adopt your API.
There are things to consider when using REST as the standard for your Public APIs, but these are manageable.
Over-fetching can become a problem within your API as you add new functionality over time. You need to be careful to not add too much bloat into your API, even if the changes are backwards compatible.
Speaking of which, when building a public REST API, you'd want to think about versioning, sunsetting, and the API lifecycle in general. How will you handle deprecation of endpoints? How will you inform your API consumers about changes? How will you track which consumer is using which version of your API? Versioning is more than just setting headers.
Another aspect of Public APIs is security. How are you planning to handle authentication and authorization? How are you going to protect your API against denial of service attacks (DDOS)?
Answers to these questions might lead to integrating OpenID Connect (OIDC) for Authentication and OAuth2 for Authorization, as well as a Rate-Limiting solution to mitigate DDOS attacks.
In addition, are you exposing a set of Endpoints from a single API, or are you intending to publish multiple Endpoints from different internal services? In both cases, you might consider using an API Gateway to handle cross cutting concerns like Authentication, Rate-Limiting, etc...
An alternative approach to using REST as your Public API could be to use GraphQL. This has several advantages but also disadvantages.
The biggest disadvantage is that you're introducing an entry barrier. Developers are simply more likely to adopt your API if it's built using REST. However, depending on the structure of your API, using GraphQL could also be an advantage, e.g. if you make heavy use of deeply nested relationships.
It's important to note that you don't have to decide between either REST or GraphQL for your Public API. It can also be a good solution to support both standards. As discussed earlier in the chapter on tRPC and GraphQL, you can build an internal "service" layer that abstracts away the business logic and expose both GraphQL and REST side-by-side. This increases the cost of development and maintenance, but would allow your users to use their favourite API style.
That said, a lot of the benefits of GraphQL are less important in server-to-server scenarios. If you're building an integration with the GitHub REST API, it's probably less of a concern if the Objects sent by the GitHub API are bigger than what you could have queried with their GraphQL API.
On the other hand, GraphQL gives you some interesting advantages over REST, which are especially interesting for Public APIs. GraphQL Schema Registries like Cosmo Studio give you field-level Schema-usage metrics which can be filtered by client. It can be a huge advantage to be able to know exactly what fields your clients are using. E.g. if you're intending to deprecate a field, you can track the usage of clients and inform them directly to use another field instead. With REST, analytics data is less granular and only available at the Endpoint-level.
However, these analytics insights don't come for free, as they put the burden of having to define GraphQL Queries for each integration on the API consumer.
Another aspect to consider is whether you're exposing an internal API from a single team or from multiple teams. With REST, you need to put tooling in place to establish rules across all APIs in terms of API design, but also ensure that all participating APIs follow the same security standards. When using GraphQL with Federation, your Schema Registry can help you to implement centralized governance.
Another aspect of using Federation in this context is that you're able to define Authorization rules in a declarative way within the GraphQL Schema. When it comes to Authentication and Authorization in Public APIs, it's important for an API consumer to be able to understand the requirements to query a field or request an endpoint. The declarative approach of adding authorization policies to the GraphQL Schema can allow a client to immediately understand what claims, scopes, and security policies are required to make a request.
Finally, GraphQL Federation can also help multiple teams to expose a "better" unified API compared to assembling multiple REST APIs combined with an API Gateway. It might be easier for multiple team to establish common design patterns and naming conventions when designing one unified GraphQL API, with a distributed implementation, compared to defining many distributed REST APIs, although tooling is available to achieve similar workflows with both approaches.
To summarize, this section has no clear winner. Both REST and GraphQL are viable solutions for exposing a public-facing API.
If you think your company can benefit from GraphQL Federation, you could internally use the distributed GraphQL approach and add a REST API Facade on top.
Either way, you still might want to add WebHooks into the mix in case your company wants to offer similar integration-points like GitHub, where third party developers can handle events asynchronously and react to them.
| Use case | Recommended API style(s) |
|---|---|
| Same team, TypeScript client & server | tRPC or GraphQL |
| Same team, multiple server languages | GraphQL |
| CLI or backend client, service-to-service | gRPC |
| Long-running operations within one company | AsyncAPI (Pub/Sub or Streams) |
| Long-running operations across companies | WebHooks (+ queues/brokers internally) |
| Multiple clients & servers across many teams | GraphQL Federation |
| Public API for third-party developers | REST and/or GraphQL |
We can keep comparing the technical aspects of different API styles and how GraphQL solves over-fetching and under-fetching, and we can also do something meaningful. We can look at the requirements of our business and derive what technologies best fit our needs.
I hope this post inspires others to have an open-minded conversation about use cases and technologies. API Styles, Solutions and Frameworks are no one-size-fits-all. What we need is a diverse API toolbelt, ready to be applied to different scenarios. Most of the time, it's not an either-or decision but rather a combination that leads to success.
If you're interested in having a discussion around API Strategy, please book a meeting with us and we're happy to share experiences from other companies.
Frequently Asked Questions (FAQ)
Start from use cases and constraints, not from a technology preference. Pick the style that aligns with business goals and team context.
Both work; tRPC offers a fast TypeScript-first flow, while GraphQL now provides a similar DX via tools like gql.tada and Grats. GraphQL is preferable if you may expose a public API, rely on fragments, or need a path to multi-team scale.
Rule out tRPC; GraphQL is the default choice here for the same reasons as above, though the final call still depends on requirements.
Use gRPC for CLI or backend-to-backend clients where GraphQL’s flexibility is less valuable. It provides schema-driven, multi-language code generation and straightforward RPC calls.
Within one company, favor AsyncAPI with durable streams like Kafka or NATS JetStream; EDFS can join stream events with service data. Across companies, prefer WebHooks with signed payloads, retries, buffering via queues/streams, and exactly-once handling.
Use Federation to scale across many teams with a unified schema and centralized governance. For public APIs, both REST and GraphQL are viable—REST (OpenAPI) eases adoption, while GraphQL offers granular usage analytics and governance; exposing both via a shared service layer is also an option.
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


