
Scaling GraphQL Subscriptions in Go with Epoll and Event Driven Architecture

Make it work, make it right, make it fast. This is a mantra that you've probably heard before. It's a good mantra that helps you to focus on not over-engineering a solution. What I've came to realize is that it's usually enough to make it right, it's usually fast enough by making it right.
When we started implementing GraphQL Subscriptions in Cosmo Router, we focused on making it work. This was a few months ago. It was good enough for the first iteration and allowed us to get feedback from our users and better understand the problem space.
In the process of making it right, we've reduced the number of goroutines by 99% and the memory consumption by 90% without sacrificing performance. In this article, I'll explain how we've achieved this. Using Epoll/Kqueue played a big role in this, but also rethinking the architecture to be more event-driven.
Let's take a step back so that we're all on the same page.
GraphQL Subscriptions are a way to subscribe to events that are happening in your application. For example, you could subscribe to a new comment being created. Whenever a new comment is created, the server will send you a notification. This is a very powerful feature that allows you to build real-time applications.
GraphQL Subscriptions are usually implemented using WebSockets, but they can also be run over HTTP/2 with Server-Sent Events (SSE).
The client opens a WebSocket connection to the server by sending a HTTP Upgrade request. The server upgrades the connection and negotiates the GraphQL Subscriptions protocol. There are currently two main protocols in use, graphql-ws and graphql-transport-ws.
Once the GraphQL Subscription protocol is negotiated, the client can send a message to the server to start a Subscription. The server will then send a message to the client whenever new data is available. To end a Subscription, eiter the client or the server can send a message to stop the Subscription.
Federated GraphQL Subscriptions are a bit more complicated than regular GraphQL Subscriptions. There's not just the client and the server, but also a Gateway or Router in between. That said, the flow is still very similar.
The client opens a WebSocket connection to the Gateway. The Gateway then opens a WebSocket connection to the origin server. The Gateway then forwards all messages between the client and the origin server.
Instead of setting up and negotiating a single GraphQL Subscription protocol, the Gateway sets up and negotiates two GraphQL Subscription protocols.
The idea of GraphQL Federation is that resolving the fields of an Entity can be split up into multiple services. An Entity is a type that is defined in the GraphQL Schema. Entities have a @key directive that defines the fields that are used to identify the Entity. For example, a User Entity could have a @key(fields: "id") directive. Keys are used to resolve (join) Entity fields across services.
The problem with Entities and Subscriptions is Subscriptions must have a single root field, which ties the "invalidation" of the Subscription to a single service. So, if multiple services contribute fields to our User Entity, they have to coordinate with each other to invalidate the Subscription.
This creates dependencies between Subgraphs , which is something that we want to avoid for two reasons. First, it means that we have to implement some coordination mechanism between Subgraphs. Second, it means that different teams owning the Subgraphs cannot move independently anymore but have to coordinate deployments, etc... Both of these things defeat the purpose of using GraphQL Federation.
To solve the limitations of classic GraphQL Subscriptions with Federation, we've introduced Event-Driven Federated Subscriptions (EDFS) . In a nutshell, EDFS allows you to drive Subscriptions from an Event Stream like Kafka or NATS. This decouples the Subscription root field from the Subgraphs, solving the aforementioned limitations. You can read the full announcement of EDFS here.
When we started implementing EDFS in Cosmo Router, we focused on making it work. Our "naive" implementation was very simple:
- Client opens a WebSocket connection to the Router
- Client and Router negotiate the GraphQL Subscriptions protocol
- Client sends a message to start a Subscription
- Router subscribes to the event stream
- Router sends a message to the client whenever a new event is received
We've got this working but there were a few problems with this approach. We've set up a Benchmark to measure some stats with pprof when connecting 10.000 clients. We've setup our Router to enable the pprof HTTP server and started the Benchmark.
To measure a running Go program, we can use the pprof HTTP server. You can enable it like this:
We can now start our program, connect 10.000 clients and run the following command to measure the number of goroutines:
In addition, we can also measure the heap allocations / memory consumption:
Let's take a look at the results!
First, let's take a look at the number of goroutines that are created.
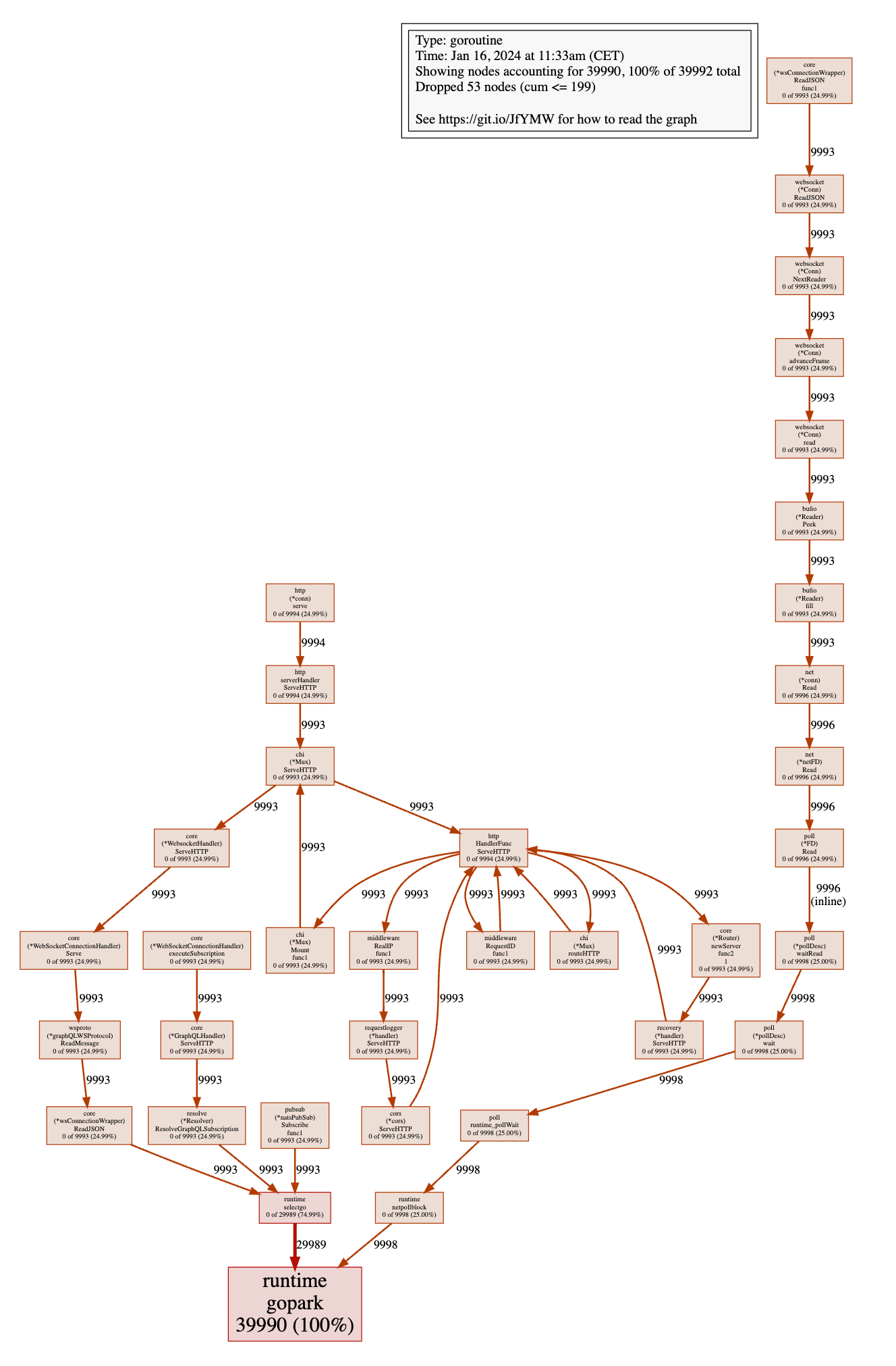
This is a lot of goroutines! It looks like we're creating 4 goroutines per client and Subscription. Let's take a closer look at what's going on.
All 4 goroutines call runtime.gopark which means that they are waiting for something. 3 of them are calling runtime.selectgo which means that they are waiting for a channel to receive a message. The other one is calling runtime.netpollblock which means that it's waiting for a network event.
Of the 3 other goroutines, one is calling core.(*wsConnectionWrapper).ReadJSON, so it's waiting for the client to send a message. The second one is calling resolve.(*Resolver).ResolveGraphQLSubscription, so it's waiting on a channel for the next event to be resolved. The third one is calling pubsub.(*natsPubSub).Subscribe which means that it's waiting for a message from the event stream.
Lots of waiting going on here if you ask me. You might have heard that goroutines are cheap and that you can create millions of them. You can indeed create a lot of goroutines, but they are not free. Let's take a look at the memory consumption to see if the number of goroutines impacts the memory consumption.
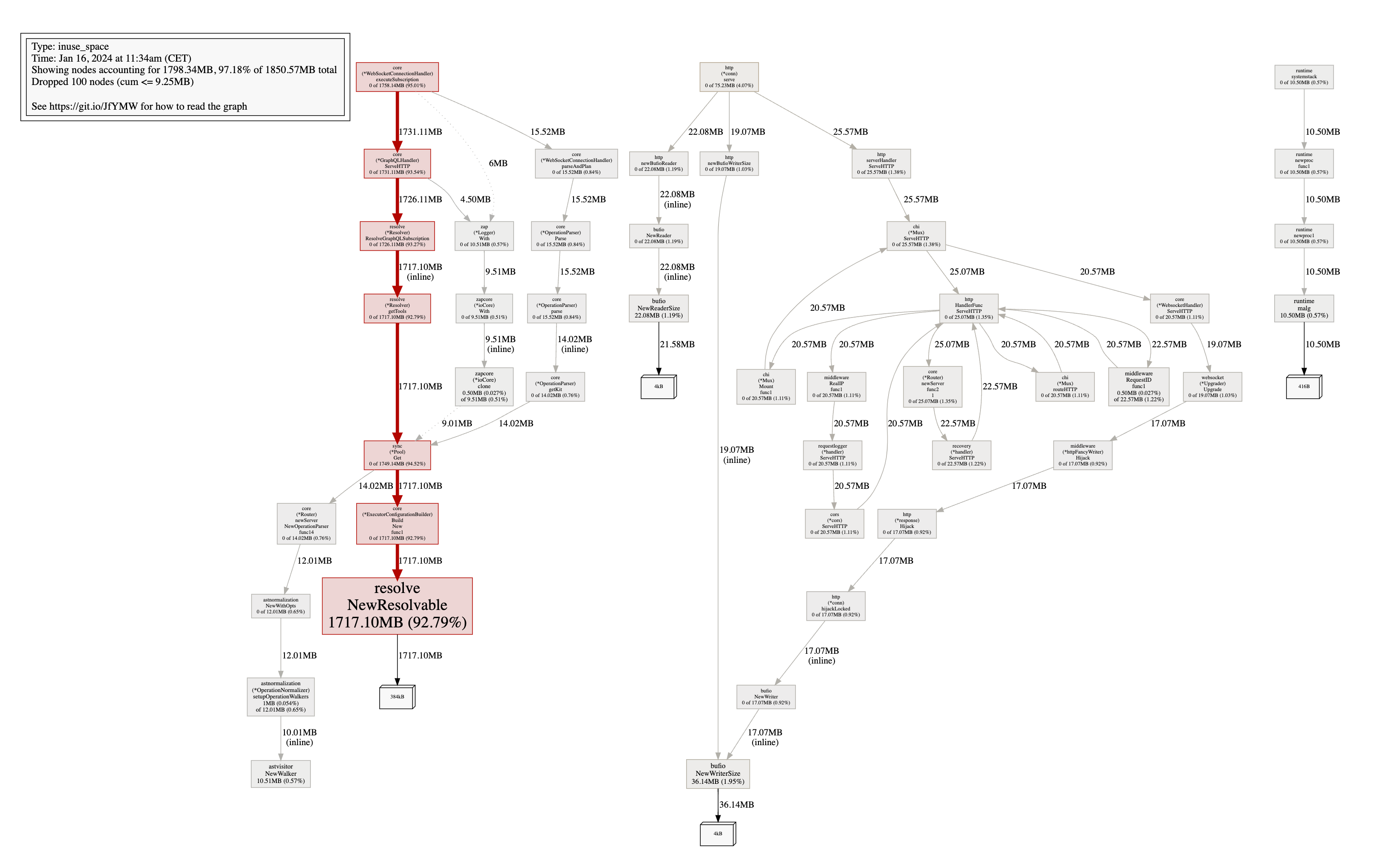
The heap is at almost 2GB, which means that we're requesting around 3.5GB of memory from the OS (you can check this with top). Let's take a look at the allocations to see where all this memory is going. 92% of the memory is allocated by the resolve.NewResolvable func, which is called by resolve.(*Resolver).ResolveGraphQLSubscription, which is called by core.(*GraphQLHandler).ServeHTTP. The rest is negligible.
Next, let's contrast this with the optimized implementation of EDFS.
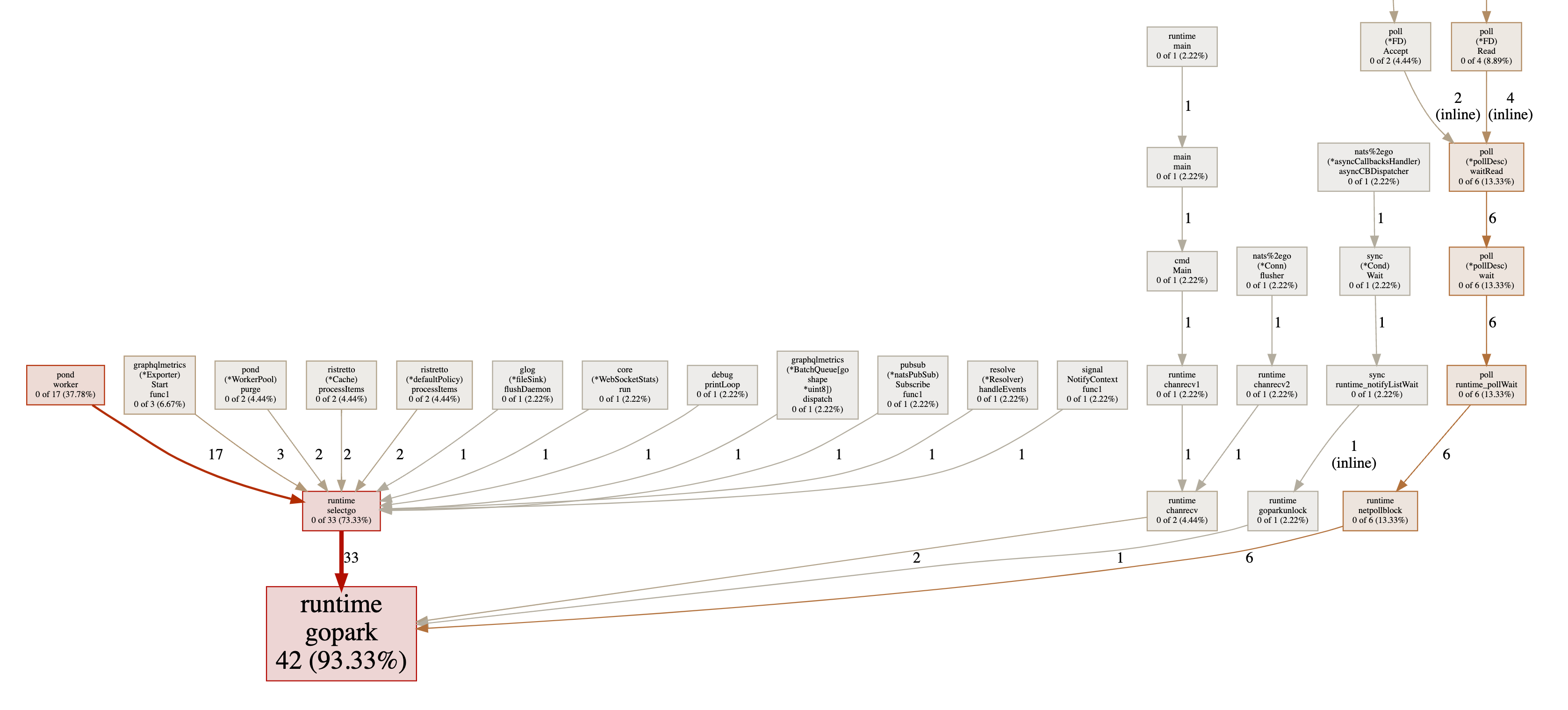
We're now down to 42 goroutines, which is a reduction of 99%! How is it possible that we're doing the same thing with 99% less goroutines? We'll get to that in a bit. Let's first take a look at the memory consumption.
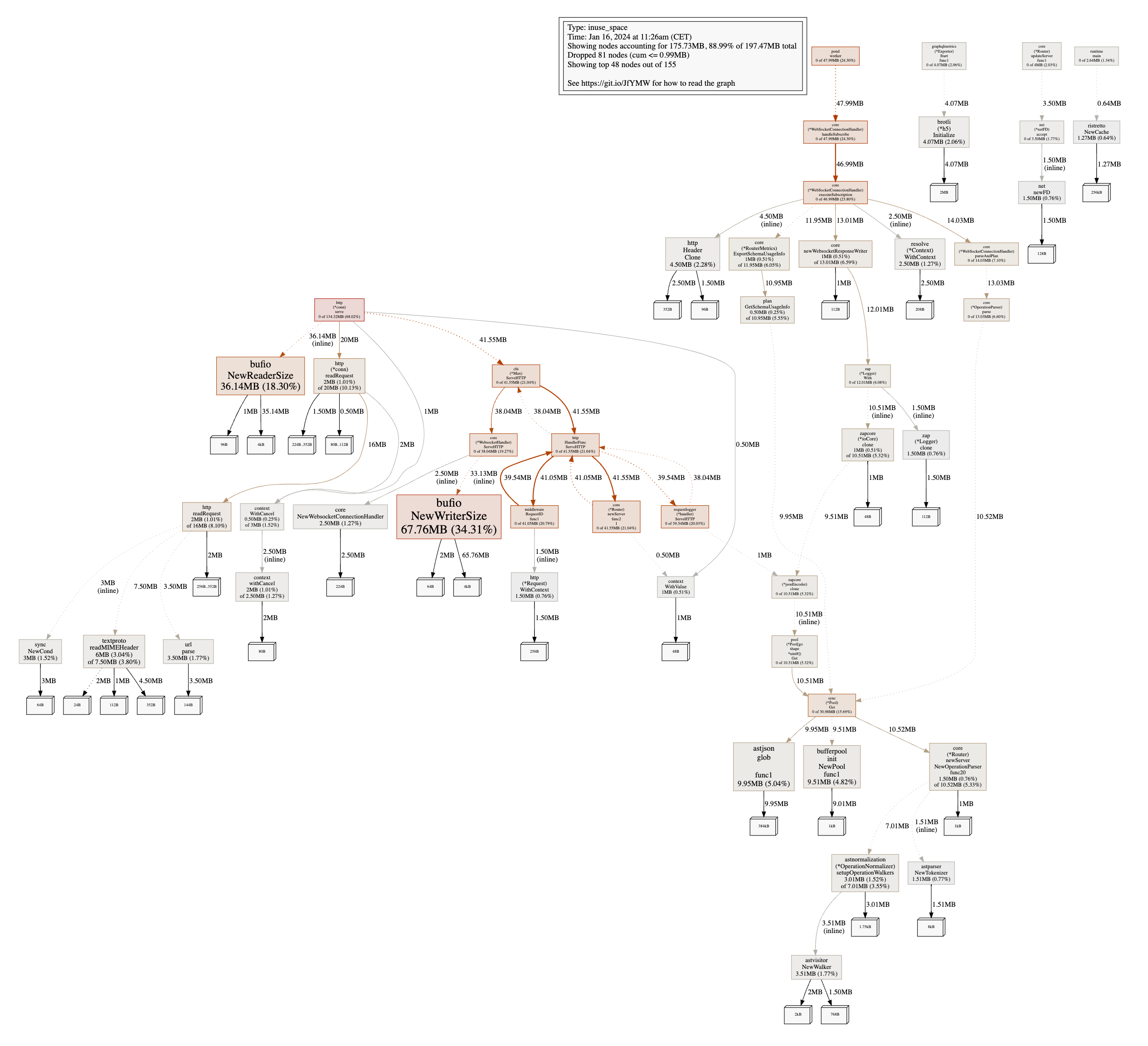
The heap is down to 200MB, which is a reduction of 90%! The main contributors are now bufio.NewReaderSize and bufio.NewWriterSize, which are tied to http.(*conn).serve. Side note, these allocations were previously not really visible because they were hidden by other allocations.
Root cause analysis: How to reduce the number of goroutines and memory consumption for GraphQL Subscriptions?
There are two main questions that we need to answer:
- Why are we creating 4 goroutines per client and Subscription?
- Why is
resolve.NewResolvableallocating so much memory?
Let's eliminate them one by one, starting with the easiest one.
Here's the code of the WebsocketHandler ServeHTTP func:
The ServeHTTP method is blocking until the connectionHandler.Serve() method returns. This was convenient because it allowed us to use the defer statement to close the connection, and we could use the r.Context() to propagate the context as it wasn't canceled until the ServeHTTP method returned.
The problem with this approach is that this keeps the goroutine alive for the entire duration of the Subscription. As the go net/http package spawns a new goroutine for each request, this means that we keep one goroutine alive for each client, even though we've already hijacked (upgraded) the connection, so this is completely unnecessary.
But instead of simply not blocking, we can do even better and eliminate another goroutine.
Do we really need to blocking read with one goroutine per connected client? And how is it possible that single-threaded servers like nginx or Node.js can handle thousands of concurrent connections?
The answer is that these servers are driven by events. They don't block on a connection, but instead wait for an event to happen. This is usually done using Epoll/Kqueue on Linux/BSD and IOCP on Windows.
With Epoll/Kqueue, we can delegate the waiting for an event to the Operating System (OS). We can tell the OS to notify us when there is data to read from a connection.
The typical usage pattern of WebSocket connections with GraphQL Subscriptions is that the client initiates the connection, sends a message to start a Subscription and then waits for the server to send a message. So there's not a lot of back and forth going on. That's a perfect fit for Epoll/Kqueue.
Let's take a look at how we can use Epoll/Kqueue to manage our WebSocket connections:
If epoll is available, we add the connection to the epoll instance and return. Otherwise, we handle the connection synchronously in a new goroutine as a fallback, but at least we don't block the ServeHTTP method anymore.
Here's the code for using the epoll instance:
We use one single goroutine to wait for events from the epoll instance. If a connection has an event, we check if the connection is still valid. If it is, we read the message and handle it. To handle the message, we use a thread pool behind the scenes to not block the epoll goroutine for too long. You can find the full implementation on GitHub .
With this approach, we've already reduced the number of goroutines by 50%. We're now down to 2 goroutines per client and Subscription. We're not blocking in the ServeHTTP func anymore, and we're not blocking to read from the connection anymore.
That makes it 3 problems left. We need to eliminate another 2 goroutines for the Subscription and reduce the memory consumption of resolve.NewResolvable. As it turn out, all of these problems are related.
Let's take a look at the naive implementation of ResolveGraphQLSubscription:
There are a lot of problems with this implementation:
- It's blocking
- It keeps a buffer around for the entire duration of the Subscription, even if there's no data to send
- We create a trigger for each Subscription, even though the trigger might be the same for multiple Subscriptions
- We blocking read from the trigger
- The
getToolsfunc allocates a lot of memory. As we're blocking the parent func for the entire duration of the Subscription, this memory is not freed until the Subscription is done. That's the line of code that's allocating most of the memory.
To fix these problems, you have to recall what Rob Pike famously said about Go:
Don't communicate by sharing memory, share memory by communicating.
Instead of having a goroutine that's blocking on a channel, and another one that's blocking on the trigger, and all of this memory that's allocated while we're blocking, we could instead have a single goroutine that's waiting for events like client subscribes, client unsubscribes, trigger has data, trigger is done, etc...
This one goroutine would manage all of the events in a single loop, which is actually quite simple to implement and maintain. In addition, we can use a thread pool to handle the events to not block the main loop for too long. This sounds a lot like the epoll approach that we've used for the WebSocket connections, doesn't it?
Let's take a look at the optimized implementation of ResolveGraphQLSubscription:
We've added a func to the Trigger interface to generate a unique ID. This is used to uniquely identify a Trigger. Internally, this func takes into consideration the input, request context, Headers, extra fields, etc. to ensure that we're not accidentally using the same Trigger for different Subscriptions.
Once we have a unique ID for the Trigger, we send an event to the main loop to "subscribe" to the Trigger. That's all we're doing in this func. We're not blocking anymore, no heavy allocations.
Next, let's take a look at the main loop:
It's a simple loop that runs in one goroutine, waiting for events until the context is canceled. When an event is received, it's handled by calling the appropriate handler func.
There's something powerful about this pattern that might not be obvious at first glance. If we run this loop in a single goroutine, we don't have to use any locks to synchronize access to the triggers. E.g. when we add a subscriber to a trigger, or remove one, we don't have to use a lock because we're always doing this in the same goroutine.
Let's take a look at how we handle a trigger update:
In the first func you can see how we're modifying the trigger and subscription structs. Keep in mind that all of this is still happening in the main loop, so it's safe to do this without any locks.
We're creating a wait group to prevent closing the trigger before all subscribers have been notified of an update. It's being used in another func in case we're closing the trigger.
Next, you can see that we're submitting the actual process of resolving the update per subscriber to a thread pool. This is the only place where we're using concurrency when handling events. Using a thread pool here has two advantages. First, the obvious one, we're not blocking the main loop while resolving the update. Second, but not less important, we're able to limit the number of concurrently resolving updates. This is very important because as you're aware, in the previous implementation we were allocating a lot of memory in the getTools func because we didn't limit this.
You can see that we're only calling getTools in the executeSubscriptionUpdate func when we're actually resolving the update. This func is very short lived, and as we're using a thread pool for the execution and a sync.Pool for the tools, we're able to re-use the tools efficiently and therefore reduce the overall memory consumption.
If you're interested in the full implementation of the resolver, you can find it on GitHub .
We've started with a naive implementation of EDFS that was working fine but we realized that it had some limitations. Thanks to having an initial implementation, we were able to define a test-suite to "nail" down the expected behaviour of the system.
Next, we've identified the key problems with our initial implementation:
- We were creating 4 goroutines per client and Subscription
- We were allocating a lot of memory in the
resolve.NewResolvablefunc - We were blocking in the
ServeHTTPfunc - We were blocking to read from the connection
We've solved these problems by:
- Using Epoll/Kqueue to not block on the connection
- Using an event-driven architecture to not block on the Subscription
- Using a thread pool to not block the main loop when resolving a Subscription update (and limit the number of concurrent updates)
- Using a sync.Pool to re-use the tools when resolving a Subscription update
With these changes, we've reduced the number of goroutines by 99% and the memory consumption by 90% without sacrificing performance.
We didn't fish in the dark, we've used pprof to analyze exactly what was going on and where the bottlenecks were. Furthermore, we've used pprof to measure the impact of our changes.
Thanks to our test-suite, we were able to make these changes without breaking anything.
We could probably reduce memory consumption even further, as the allocations of the bufio package are still quite visible in the heap profile. That said, we're aware that premature optimization is the root of all evil, so we hold off on further optimizations until we really need them.
There's a spectrum between "fast code" and "fast to reason about code". The more you optimize, the more complex the code becomes. At this point, we're happy with the results and we're confident that we can still efficiently maintain the code.
If you're interested in learning more about EDFS, you can read the full announcement here. There's also some documentation available on the Cosmo Docs . If you enjoy watching videos more than reading, you can also watch a Demo of EDFS on YouTube .
I hope you've enjoyed this blog post and learned something new. If you have any questions or feedback, feel free to comment or reach out to me on Twitter .
I took inspiration from the 1M-go-websockets project. Thank you by Eran Yanay for creating this project and sharing what you learned with the community.
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


