
Cosmo Graph Feature Flags vs. Apollo Progressive Overrides: A Different Model for Gradual Rollouts

TL;DR
Graph Feature Flags in Cosmo let platform teams create isolated Supergraph compositions that swap in feature versions of one or more Subgraphs. This enables safe, incremental schema evolution and gradual production rollouts without deploying a separate environment per feature branch. Composition happens at build time, so you avoid runtime composition overhead and catch incompatible Subgraphs before they reach users.
GraphQL Federation solves an organizational problem. It breaks down a single monolithic GraphQL schema into multiple smaller services (Subgraphs). Ownership of these services can be distributed across different teams. This lets teams work independently and deploy their Subgraphs on their own, while still enforcing centralized governance and coordination across the overall schema.
However, this independence comes with a challenge when it comes to Schema Evolution. Different teams might want to evolve their Subgraphs in ways that are incompatible with the work of other teams which is happening in parallel. If we only have one single Schema, we're unable to experiment with new features in isolation. At the same time, large environments with many Subgraphs won't allow us to deploy a unique set of Subgraphs for each feature branch. We need a way to create isolated compositions of Subgraphs where we're able to replace one or more Subgraphs with a different version, potentially incompatible with other isolated compositions. This is where Graph Feature Flags come into play.
State of GraphQL Federation 2026
How are teams governing schema changes, handling production traffic, and measuring Federation success? Share your experience and get early access to the full report. For every valid survey completed, we'll donate $30 to UNICEF .
We're not the ones who came up with the idea of Graph Feature Flags. We've recently onboarded a new customer, who has been using Graph Feature Flags for a while now. They've customized Apollo Gateway to support Graph Feature Flags and have been using it for their GraphQL Federation setup. When they migrated to Cosmo, they wanted to keep using Graph Feature Flags, but they didn't want to continue maintaining their custom implementation.
We've been working closely together with the Platform Engineering team to understand their implementation, and turn it into a refined and more capable feature that we can offer to all Cosmo users.
Here's a high-level overview of how the initial implementation worked:
- A team creates a new feature branch for a Subgraph and deploys it to the staging environment
- The team publishes a Feature Flag to the Gateway
- When the Gateway receives a request with a Feature Flag Cookie, it creates an in-memory composition of all Subgraphs and replaces the Subgraph that has the Feature Flag with the one from the feature branch
Our main criticism of this approach was that it runs composition for the Feature Flag at runtime. The Gateway would have to do a lot of work in case the composition for a Feature Flag is not cached yet. In addition, we'd prefer to have a more declarative way to define Feature Flags, allowing us to do composition at build time. This not only takes load off the Gateway (Router) but also allows us to prevent runtime errors due to incompatible Subgraphs.
As we've explored how we could support Graph Feature Flags in Cosmo, we've come up with a new approach that enables not just continous Schema Evolution, but also gradual rollouts of new features to a subset of traffic in production.
- Fast & Efficient Schema Evolution: Teams can experiment with new features in isolation
- Gradual Rollouts: Gradually roll out new features to a subset of traffic
At a high level, here's how Graph Feature Flags work in Cosmo:
We're introducing two new concepts: Feature Subgraphs and Feature Flags. Feature Subgraphs are versions of Subgraphs that replace the original Subgraph in a composition. Feature Flags are a group of Feature Subgraphs that are composed together to create a new isolated composition of Subgraphs.
In addition, the Cosmo Router supports running multiple compositions on the same instance, This is the foundation for Graph Feature Flags, as we can use a Header or Cookie to determine which composition (Supergraph) to use for a request.
This enables isolated experiments and gradual rollouts of new features with build-time composition. This is more efficient, prevents runtime errors, and gives you immediate feedback if a Feature Flag composition is valid or not.
Let's take a closer look at the two main use cases for Graph Feature Flags and how they work.
Let's say we have a simple Federation setup with two Subgraphs: Products and Users. Two teams want to work in parallel on Feature A and Feature B. For Feature A, we'd like to use the latest version of the Products Subgraph, and a new variant of the Users Subgraph. For Feature B, we'd like to replace both Subgraphs with new versions. Here's how our setup would look like:
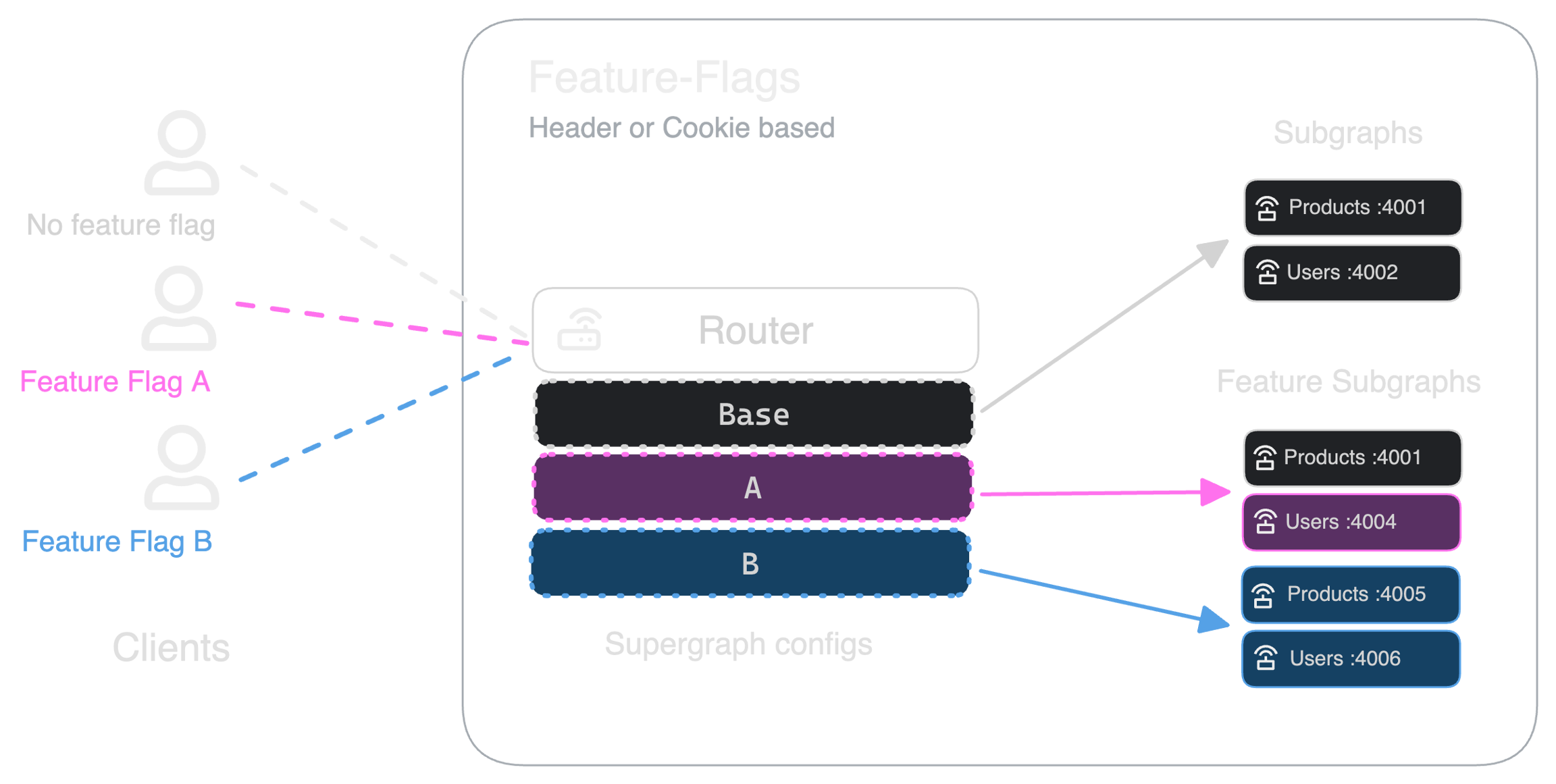
Requests with no Feature Flag (Cookie or Header) will use the default Supergraph (Base), which is the composition of Products:4001 and Users:4002. Traffic will be routed to these two Subgraphs.
Requests with the Feature A Feature Flag enabled will use the A Supergraph, which is the composition of Products:4001 and Users:4004. Requests will be routed to the Products:4001 Subgraph and the Users:4004 Subgraph.
Finally, requests with the Feature B Feature Flag enabled will use the B Supergraph, which is the composition of Products:4005 and Users:4006. The Router will only route traffic to the Products:4005 and Users:4006 Subgraphs for these requests.
With this setup, there's no need to deploy a whole new set of Subgraphs for each feature branch. You can have a Staging or Pre-Production environment that's deployed from all main branches of your Subgraphs.
Next, let's say we want to develop a new feature that spans multiple Subgraphs. We can create an "Epic", a "Project" or "Master Ticket" in our project management tool and assign a Feature Flag name to it. We can now create feature branches for each affected Subgraph and deploy a "Feature Subgraph" for all open Pull Requests. The Frontend team can test against this new composition and iterate with the backend developers. Once all Pull Requests are merged, the Feature Flag will be removed and the new composition will be the default one.
It's already a great way to continously evolve your Schema without having to coordinate deployments or changes across multiple teams. But we can take it even further. With Graph Feature Flags, we can also do gradual rollouts of new features to a subset of traffic in production.
Let's say we have implemented our new feature in the previous example using our staging environment. We're now ready to roll it out to production, but we want to be cautious and only enable it for a subset of traffic.
This can have multiple reasons:
- We want to monitor the performance of the new feature
- We want to monitor the impact on the user experience
- We want to monitor the impact on the backend and frontend services
We might be introducing a new feature and we're not yet sure how much traffic it will generate. What we can do is to enable the Feature Flag for a subset of traffic, measure the impact, and gradually increase the traffic share.
Here's an example of how this could look like.
In this example, we're using the @override directive to move ownership of a field from the Products Subgraph to the Users Subgraph in the hopes of reducing the number of requests to the Products Subgraph. We've identified a Query that's particularly expensive to resolve and found a way to reduce the number of network requests by migrating the field to the Users Subgraph.
With Graph Feature Flags, we can create a new Supergraph composition that includes the @override directive, but we're not routing any traffic to it yet. As we're putting it behind a Feature Flag, we can be confident that it's composing correctly.
Once the Feature Flag is deployed, we can test it manually, e.g. by using the integrated GraphiQL Playground in Cosmo Studio. From the Studio, you can select all available Feature Flags from a dropdown to get access to the new Supergraph. Using Advanced Request Tracing (ART), you can compare the performance of your existing Queries between the current Supergraph and the new Supergraph with the @override directive. Internally, the Studio sets a Header with the Feature Flag name to enable it on the Router.
Once we're confident that the new Supergraph is performing well, we can start enabling the Feature Flag for a subset of traffic. This can be done in various ways, as the Router is very flexible in how it handles Feature Flags. To enable a Feature Flag on the Router, you need to set a Header or Cookie with the Feature Flag name. This gives you the following options:
- Load Balancer / API Gateway: You can configure your Load Balancer or API Gateway to set a Header or Cookie for some percentage of traffic.
- Client: You can set a Header or Cookie on the client side to enable the Feature Flag for a subset of users.
If a Graph Feature Flag is compatible with the current Supergraph, but only changes the internal behavior of one or more Subgraphs, it's safe to enable it at the Load Balancer or API Gateway level.
If a Graph Feature Flag requires changes to the client, e.g. by adding a new capability to the Frontend, you could add a Feature Flag to the Frontend Framework that enables the new capability for a subset of users, and simultaneously enable the Feature Flag on the Router for this subset of users. This can be done, e.g. by setting a Cookie on the client side if the Frontend Feature Flag is enabled, or by setting a Header on the client.
In both cases, you can monitor the impact of the new Feature Flag and compare it to the default Supergraph. Graph Feature Flags are fully integrated with OTEL (OpenTelemetry) and Cosmo Studio. This means that you can use Cosmo Studio, DataDog, or any other OTEL-compatible monitoring solution to compare the performance of the new Supergraph with the default Supergraph. Metrics and Traces are tagged with the Feature Flag name, so you can easily filter and compare them.
If you want to learn more about how to use Graph Feature Flags in Cosmo, check out the Cosmo Docs .
As you've seen in the previous examples, Graph Feature Flags allow you to experiment with new features in isolation and gradually roll them out to a subset of traffic in production. This is a great way to evolve your Schema in a safe and controlled way.
Although some readers might already understand the potential of Graph Feature Flags, I'd like to explicitly point out one more use case that I'm particularly excited about: Supergraph Previews for every Pull Request!
We're probably all familiar with the concept of Preview Environments for Frontend applications. For every Pull Request, a new isolated staging environment is created to preview the changes, allowing the Frontend team to test the changes in isolation and get immediate feedback from stakeholders.
With a (micro-)service architecture, it's much harder to create isolated staging environments for every Pull Request because of the complexity of the setup. You can't just deploy a unique set of 100 services for every Pull Request. This is where Graph Feature Flags come in handy.
With Graph Feature Flags, you can set up your Continuous Integration pipeline to deploy a new Feature Subgraph and Feature Flag for every Pull Request. You could for example use the Subgraph name and Pull Request number as the Feature Flag name. This way, you can create one composition for every Pull Request without having to deploy a whole new set of Subgraphs. All we need is a Staging environment that's deployed from all main branches of your Subgraphs. With Graph Feature Flags, we can then "override" the Subgraphs for a specific Pull Request.
Here's an example of how our GitHub Actions pipeline could look like:
- A Pull Request is opened
- The CI pipeline deploys a new Feature Subgraph for the Pull Request
- The CI pipeline creates a new Feature Flag for the Pull Request
- The CI pipeline sets the Feature Flag on the Router
- The CI pipeline runs the tests against the new Supergraph
- The Frontend team can test the changes in the integrated GraphiQL Playground in Cosmo Studio
- The Pull Request is merged and the Feature Flag is removed
There's no need to coordinate deployments across multiple teams, we don't need to deploy large numbers of Subgraphs for every Pull Request, and we also don't need a dedicated Router for every Pull Request.
Cosmo Router is able to handle multiple Feature Flags at the same time, so you can easily run many Previews in parallel, enabling teams to work independently on their Pull Requests against the same (partially) shared Staging environment.
Apollo has a related feature called "Progressive Overrides", which allows you to annotate a field with the @override directive and an additional label argument to gradually move ownership of a field from one Subgraph to another.
Here's an example of how a Schema with Progressive Overrides could look like:
In this example, we're moving the user field from the monolith Subgraph to the users Subgraph, but only for 25% of the traffic.
With Cosmo's Graph Feature Flags, we can achieve the same result by creating a Feature Subgraph that includes the @override directive, and enabling the Feature Flag for a subset of traffic.
What's different is that you can migrate the traffic gradually at the Load Balancer or API Gateway level, instead of having to set a label argument on the field level.
What's great about the approach using a label is that it's declarative and part of the Schema. If you're already using a Schema Registry, which is very likely if you're using Federation, you can look at the history of Schema changes and see what values the label argument had in the past.
There are also some downsides to this approach, which is why we've decided to take a different route to solve the same problem.
Composing a Supergraph can be a complex operation, and it's usually driven through CI/CD pipelines that are triggered by Pull Requests. Based on our experience, we've found that CI/CD pipelines for Federation Subgraphs can take between 3-15 minutes to complete, depending on the complexity of the Supergraph, the number of Subgraphs, dependencies and the framework you're using. If you're intending to migrate traffic gradually, or you have to quickly roll back a change, you don't have the time to wait 15 minutes for a CI/CD pipeline to complete. If production traffic is negatively impacted by a change, you need to be able to roll back within seconds.
As such, we've come up with a solution that allows you to leverage composition checks at build time, while being able to migrate traffic gradually by setting a Header or Cookie at the Load Balancer or API Gateway level.
Schema governance beyond feature flags
Feature flags buy you time; registry discipline buys you trust. These posts cover the checks, extensions, and collaboration rituals that make “replace a subgraph at the edge” safe:
- GraphQL Federation schema checks with open source schema registry: why CI-time composition is non-negotiable.
- Versionless APIs that stay backwards compatible: evolving SDL without breaking unknown clients.
- Subgraph check extensions in Cosmo: custom lint rules that encode your org’s invariants.
- GraphQL Federation schema changes from months to days: what faster iteration actually looked like for one team.
Another advantage of Cosmo's Graph Feature Flags is that we're able to fully replace a Subgraph with a new version. With Apollo's Progressive Overrides, you're only able to move ownership of a field from one Subgraph to another, but you cannot replace a Subgraph entirely. With Cosmo's Graph Feature Flags, you could create a new version of a Subgraph that leverages a completely different technology stack, e.g. if you're migrating from Node.js to Rust. The @override directive is not sufficient to handle such a migration as it's limited to moving ownership of a field to another Subgraph. What we're able to do with Cosmo's Graph Feature Flags is (re-)build a Subgraph in a different technology, or adding a Cache like Redis or Memcached to a Subgraph, and then compare the performance (avg requests per second & p95 latency) and reliability (error rate) of the new Subgraph with the old Subgraph.
Graph Feature Flags let you do something that's hard to get right any other way: validate a schema change in production-like conditions before routing real traffic to it. Composition happens at build time. Rollout happens at the edge, via a header or cookie. No new environment, no full redeploy.
For setup details and CLI commands, see the Cosmo docs on Feature Flags .
CEO & Co-Founder at WunderGraph
Jens Neuse is the CEO and one of the co-founders of WunderGraph, where he builds scalable API infrastructure with a focus on federation and AI-native workflows. Formerly an engineer at Tyk Technologies, he created graphql-go-tools, now widely used in the open source community. Jens designed the original WunderGraph SDK and led its evolution into Cosmo, an open-source federation platform adopted by global enterprises. He writes about systems design, organizational structure, and how Conway's Law shapes API architecture.


