
Serverless GraphQL Federation Router for AWS Lambda

TL;DR
- WunderGraph released an officially supported Serverless GraphQL Federation Router for AWS Lambda.
- The router runs as an event-driven Lambda function instead of a traditional HTTP server.
- It supports GraphQL Federation, OpenTelemetry tracing, metrics, and schema usage analytics.
- The router binary was reduced to 19MB to improve Lambda cold starts.
- In testing, cold starts with a subgraph request took about 641ms, while warm requests averaged around 80ms.
- A benchmark with 100 concurrent users reached approximately 480ms p95 latency.
- Deployment requires packaging the Lambda router binary as
bootstraptogether with arouter.jsonconfiguration file.
Cosmo Router is deployment-agnostic. The same binary runs on Kubernetes (production standard for high-throughput graphs), as a standalone process on VMs or containers, on AWS Lambda (serverless, event-driven), or through managed on-premises plans when you want WunderGraph to operate the control plane in your environment.
| Deployment | Best for | Tradeoffs |
|---|---|---|
| Kubernetes | Steady high-throughput production (100k+ RPS), horizontal scaling, GitOps | Requires cluster ops; see the Helm chart and self-hosted docs |
| AWS Lambda | Variable traffic, pay-per-request, no server management | Cold starts (~640ms in testing); event-driven execution model |
| Managed on-premises | Enterprise compliance with WunderGraph operating the control plane | Commercial plan |
This guide focuses on the Lambda path. For Kubernetes or full self-hosting — including scaling to 100k+ RPS — start with the self-hosted deployment guide instead.
This guide is for teams running GraphQL Federation who want to deploy a federation router on AWS Lambda using a serverless architecture.
WunderGraph released an officially supported Serverless GraphQL Federation Router for AWS Lambda . The router allows teams to run a federated GraphQL gateway on Lambda using an event-driven serverless architecture with built-in OpenTelemetry support, schema analytics, and GraphQL Federation support.
The router is designed for small deployment size, fast cold starts, and integration with AWS Lambda execution patterns.
A GraphQL gateway, also known as a GraphQL router, acts as a single access point that aggregates data from multiple sources, orchestrating responses to GraphQL queries. It provides a unified GraphQL schema from different microservices, databases, or APIs, streamlining query processing and schema management. By routing requests to the appropriate services and merging the responses, a GraphQL gateway simplifies client-side querying, enabling seamless data retrieval from a variety of back-end services and systems. This architectural design enhances scalability, maintainability, and the ability to evolve API landscapes without impacting client applications.
In order to scale out a federated Graph, you need more than just a Gateway, though. You should have a Schema Registry, Analytics, Schema Usage Metrics, breaking change detection, and a lot more. For that, we've built Cosmo which is a complete platform to manage your federated Graph. Check out Cosmo on GitHub if you're interested, it's fully open-source (Apache 2.0 licensed).
In this article, the terms GraphQL gateway and GraphQL router are used interchangeably to describe the federated entry point handling GraphQL requests.
AWS Lambda provides a serverless computing service, offering a hassle-free solution where concerns about server provisioning, scaling, and infrastructure management are handled by AWS. This allows you to concentrate solely on your business logic. Although it might sound like a jargon-filled proposition, the practical benefits for companies are substantial. Operating gateway services is inherently complex and challenging, but AWS Lambda simplifies this process. It stands out as the most popular and mature serverless computing service, available in all regions and featuring an exceptionally generous free tier. These attributes make AWS Lambda an ideal choice for our specific needs.
The router runs as an AWS Lambda function using an event-driven execution model. Instead of running a continuously active HTTP server, AWS Lambda invokes the router handler for each request event.
This allows the GraphQL Federation router to integrate with AWS services and serverless infrastructure patterns in a serverless deployment model.
Due to the architecture of Lambda, we had to make our router event-driven. AWS Lambda functions are invoked by events. You can't simply run an http server. Instead, you have to register a handler function that is invoked by an event. This is a huge difference to traditional servers. Luckily, the community already built a lot of adapters to make this process as easy as possible. We decided to use the akrylysov/algnhsa to handle the event and response handling for us. This allows us to make our router compatible with only a few lines of code "simplified".
As a side effect, our Router can now be integrated into the existing AWS ecosystem. For example, we can run a GraphQL mutation through an SQS or S3 event. This allows us to build a very flexible and scalable system.
That's it! Of course not, there is a lot more going on under the hood. We down-shrink the router binary to 19MB to advance a small footprint and therefore fast cold starts. We also went a different route to report metrics and traces to our collectors. We will talk about this in the next section.
Our Router has built-in support for OpenTelemetry for tracing and metrics. We also collect schema usage data of your GraphQL operations to give you insights into your schema usage. In that way, we can identify if a schema change is safe to deploy or not.
- Lambda functions cannot continue background work after a response is sent.
- Traditional SIGTERM-based flushing patterns do not fit the Lambda execution model.
- Metrics and traces must be flushed synchronously after each request.
- Metrics and traces are sent in parallel.
- Traces are sampled to reduce overhead.
- Writes do not wait for acknowledgement from collectors.
- Added latency was measured at under 75ms.
In the AWS Lambda handler, you can't do work after the response was sent. If you are thinking in servers, we looked for a way to do arbitrary work in the background and on SIGTERM #Issue . This does not fit into the serverless mindset. Maybe your function will never shutdown, so you have to find another way. We have to flush the metrics and traces synchronously after each request. This is tricky, because it adds latency to the response. It is much better than it sounds, because we optimized the flushing process to be as fast as possible. All metrics and traces are sent in parallel without write acknowledgement to the collectors and traces are sampled to reduce the overhead. This adds less than 75ms of latency to the response. This is a very small price to pay for the benefits you get.
AWS Lambda includes a free tier of 1 million requests per month. Beyond that, the 128MB model costs about $2.28 per 1 million requests, assuming a full second per request. CPU and cost both scale with memory size, so the 1536MB model we recommend below for faster cold starts costs proportionally more per request. Warm requests finish in around 80ms, not a full second, so real-world cost runs well under that worst-case estimate.
| Scenario | Result |
|---|---|
| Cold start + subgraph request | ~641ms |
| Lambda initialization time | ~300ms |
| Warm request latency | ~80ms |
| Benchmark concurrency | 100 VUs |
| Benchmark p95 latency | ~480ms |
Our tests showed that the Router handles subsequent requests with this plan very well but at the cost of much higher cold start times. We recommend using the 1536MB memory size model. This is the sweet spot of good cold starts and low costs. We were able to wake up the Router and making a subgraph request in 641ms. The initialization time of the lambda function took just 300ms.
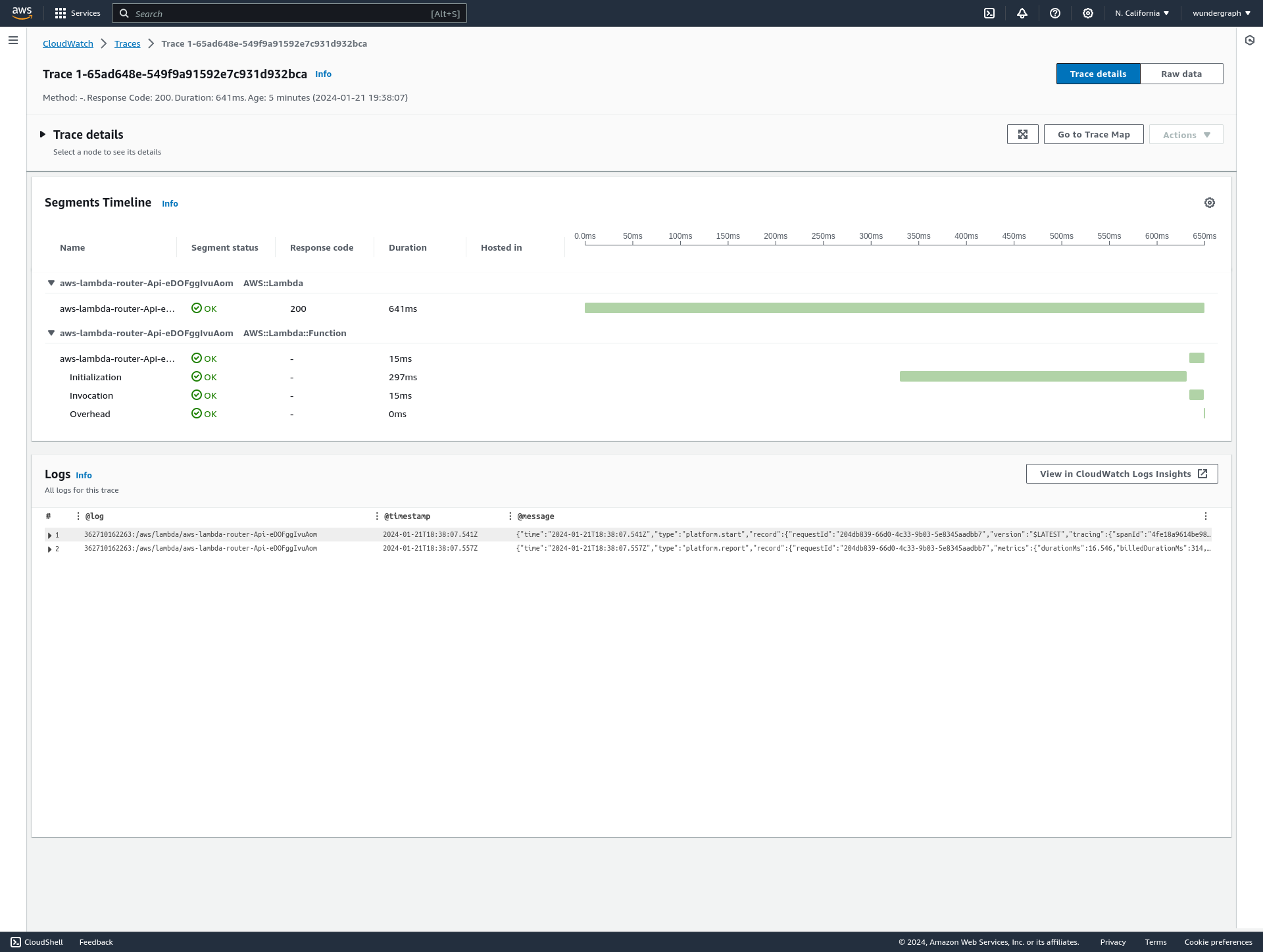
Once the Lambda function is initialized warm, it can handle subsequent requests in 80ms. In this scenario, we made a Subgraph request to the Employees API which is hosted on fly.io in the US West (LAX) region. This is a very good result and shows that our Router performs very well on AWS Lambda.
Additionally, we tested the performance of the router with 100 concurrent users over a period of 60 seconds. We warmed the functions with 2 pre-runs. Due to simplicity, I didn't redeploy the router near my location. Instead, I used the same setup as above. The router was deployed in the US West (Oregon) region while I'm located in Germany. We will definitely see better results if we deploy the router and subgraphs near my location, but I think the results already speak for themselves.
The router was able to handle all requests with p95 of 480ms. This is a very good result and shows that our router scales well on AWS Lambda.
I want to call out @codetalkio who does a fantastic job with their repository to unmistify the landscape of supported GraphQL Federated Gateways on AWS Lambda. It gave us the inspiration to support AWS Lambda as a first-class citizen.
As you might know, we love Open Source! You can find the source code of the Serverless Router on GitHub . We manage separate releases for the AWS Lambda router. You can find the releases here .
You don't have to build the router yourself. You can download the latest release and follow the instructions below.
Deployment requires:
- the Lambda router binary
- a
router.jsonconfiguration file - a zip archive containing both files
Download the Lambda Router binary from the official Router Releases page.
Create a .zip archive with the binary and the
router.jsonfile. You can download the latestrouter.jsonwithwgc federated-graph fetch. The .zip archive should look like this:bash . └── myFunction.zip/ ├── bootstrap # Extracted from the Router release archive └── router.json # Downloaded with `wgc federated-graph fetch`Deploy the .zip archive to AWS Lambda. You can use SAM CLI or the AWS console. Alternatively, you can use your IaC tool of choice.
Before taking traffic in production, see integration testing patterns for the Cosmo Router — the same federation behaviors apply to the Lambda build.
- The router runs GraphQL Federation on AWS Lambda using an event-driven architecture.
- OpenTelemetry tracing, metrics, and schema usage analytics are built in.
- The router binary was optimized for smaller deployment size and improved cold starts.
- Warm requests averaged around 80ms in testing.
- Deployment requires packaging the Lambda router binary together with a
router.jsonconfiguration file.
AWS Lambda allows teams to deploy and scale a GraphQL Federation router using a serverless architecture.
If you are a company and want to use our router in production, please reach out to us . We are happy to help you with the setup process and provide you with support.
Frequently Asked Questions (FAQ)
Yes. Cosmo Router runs on Kubernetes (via Helm), as a standalone binary, on AWS Lambda, or through Cosmo managed and on-premises plans. Lambda fits event-driven and variable-traffic workloads; Kubernetes fits steady high-throughput production deployments.
An officially supported Serverless GraphQL Federation Router for AWS Lambda, enabling a federated gateway to run on Lambda.
Lambda removes server management, scales automatically, is widely available with a generous free tier, and fits the router’s event-driven design.
It has built-in OpenTelemetry for traces and metrics and flushes them synchronously after each request, adding under 75ms by sending in parallel and sampling.
With 1536MB memory, cold start plus a subgraph request was about 641ms (300ms init), warm requests were ~80ms, and a 100-VU test reached p95 ≈ 480ms.
Lambda includes 1M free requests per month; beyond that the 128MB example model costs $2.28 per million requests (assuming 1s per request), with both CPU and cost scaling by memory size.
Download the AWS Lambda router release, zip the binary as “bootstrap” together with router.json (fetched via `wgc federated-graph fetch`), then deploy the zip to Lambda.
No. The AWS Lambda router uses an event-driven execution model where Lambda invokes a handler function for each request.
Yes. The router includes built-in OpenTelemetry support for tracing and metrics.
The article recommends the 1536MB Lambda memory configuration as a balance between cold starts and cost.
Deployment requires the Lambda router binary packaged as `bootstrap` together with a `router.json` configuration file.
Co-Founder of WunderGraph
Dustin Deus is one of the co-founders of WunderGraph. A specialist in Go and distributed systems, he has built scalable APIs, networking layers, and developer tooling adopted by enterprise engineering teams worldwide.


